基于语义规则的胶囊网络跨域情感分类


论文
ABSTRACT
CapsuleDAR利用胶囊网络编码内在的空间的部分-整体关系,构成领域不变知识(domain invariant knowledge),弥补了源域和目标域之间的知识缺口。此外,我们还提出了一个规则网络,将这些规则纳入到胶囊网络中,以提高全面的句子表示学习。
I. INTRODUCTION
现有的情绪分类方法可以根据所使用的知识和信息分为两类:
基于词典(exicon-based)的方法和基于语料库(orpus-based)的方法。
基于词汇的方法根据情绪符号来计算文本中的消极词汇和积极词汇,如果积极词汇的数量大于消极词汇的数量,则将文本中的情绪极性指定为积极词汇。
相比之下,基于语料库的方法利用机器学习算法来训练一个情绪分类器的方法在语料充足的情况下效果更好。
结构对应学习(SCL,tructural correspondence learning)[1]、[14]是一种杰出的领域适应方法。Panet al.[2]提出了光谱特征重组(SFA),通过对齐枢轴和非枢轴(aligning pivots with non-pivot)来实现跨域分类。为了利用深度神经网络的优点,Glorotet al.[15]提出了堆叠去噪自动编码器(SDA),它可以自动从不同领域的大量数据中学习共同的特征表示。Zhou等人[16]提出了一种学习跨域异构特征映射的深度学习方法。随后,Ziser和Reichart[17]提出了一种自动编码器- SCL模型,它结合了SCL方法和自动编码器模型。经验证,该模型优于以往的方法。一般而言,上述跨域情感分类方法不仅从源域中提取特征,而且可以学习连接跨域知识鸿沟的共享特征。
胶囊网络中的每个胶囊都是神经网络的聚合体,其中每个神经元代表文中所呈现的特定特征的各种属性。这些属性可以是不同类型的实例化参数,如n-gram特征、单词或短语的位置信息、句子的句法特征等。
我们还提出了一个规则网络,将语义规则(如句子结构)纳入胶囊网络,以进一步提高跨域情感分类的性能。具体来说,第一个规则是利用源域和目标域之间的枢轴特性(pivot features)来增强卷积滤波器的性能。二是利用句子结构信息,丰富跨域情感分类句子的综合表示学习。
II. RELATED WORK
A. CROSS-DOMAIN SENTIMENT CLASSIFICATION
Glorotet al.[15]引入了堆叠去噪自动编码器(SDA)来从源和目标域学习文档的单值抽象特征表示。Chenet al.[23]提出了mSDA算法,该算法保留了SDA强大的特征学习能力,解决了SDA的高计算成本和可扩展性问题。随后,为了进一步提高跨域情感分类的性能,提出了SDA方法的许多扩展[24]-[26],但以往的方法缺乏解释能力,无法证明网络是否具有足够的能力来学习支点特征。为了提高深度学习模型的可解释性Ziser和Reichart[17]提出了AE-SCL-SR方法,该方法结合了自动编码器和基于数据轴(pivot-based)的跨域分类方法。Liet al.[6]引入了AMN方法(IJCAI-17),利用注意机制自动捕捉枢轴,无需人工干预。为了提高分类能力,Ziser和Reichart,[7]提出了一种结合LSTM和cnn与pivot特征的PBLMs方法。
B. CAPSULE NETWORKS
最近,人们提出了一种新的神经网络,利用胶囊的概念来改进CNN和RNN的表示局限性。带有转换矩阵的胶囊允许网络自动学习部分和整体的关系。因此,Sabouret al.[27]提出了用矢量输出胶囊网络代替cnn。此外,CNNs中的max-pooling操作也被一种新的协议路由算法所取代。胶囊网络通过在MNIST数据上实现一流的结果显示了它的潜力。以一个典型的神经网络对隐藏向量进行编码的实例为例,利用注意机制建立了胶囊表示。Zhaoet al.[31]在文本分类中应用了胶囊网络。他们表明,胶囊网络在文本分类方面优于基线方法。
III. OUR METHODOLOGY
我们的模型,如图1所示,是在Sabouret al.[27]中提出的胶囊网络的一个变体。它由基本网络和规则网络两个网络组成,以提高跨域情感分类的性能。
A. PROBLEM DEFINITION
源域中标签文档的集合表示为
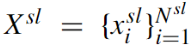
源域中的样本数目为
每个文档
对应一个ne-hot表示的情绪标签
在目标域,给出一个未标记的数据集
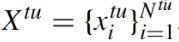
目标域中的样本数为
该模型的目的是利用在源域数据上预先训练好的分类器来预测目标域样本的情绪极性。
B. FRAMEWORK OVERVIEW
基本网络使用一个经过文本训练的胶囊网络来进行情绪预测。
它包含一个嵌入层,一个用于捕获文本的n-gram的卷积层,一个Incaps层和一个Outcaps层,然后是一个Classcaps层。
规则网络将语义规则利用到胶囊网络中,胶囊网络使用公共知识边界来弥合源域和目标域之间的知识鸿沟。
规则网络的结构与基础网络相似,卷积层的参数由两种网络共享。我们在Outcaps和classcaps层之间增加了一个Rulecaps层,以充分利用语义规则。

C. OUR METHODOLOGY
我们的模型由两个组件组成:基础网络和规则网络。接下来,我们将详细说明模型的每个组件。
1) BASE NETWORK
利用基础网络对文本内容特征进行建模
…
b: Conv Layer
作者认为跨源域和目标域的轴心特征(pivot features),可以用来弥合源域和目标域之间的知识鸿沟,因此,引入了基于pivot的filter初始化方法来提高文本表示能力,而不是对卷积层使用随机初始化过滤器。特别地,我们首先使用tf-idf[32]方法来选择源域中每个情绪类别贡献最大的n个图。然后,使用SCL方法[7]来选择主元特征。遵循[6]中的策略,将提取的tf-idf特征和主特征进行集合,使用k-means方法对这些特征进行聚类,并使用聚类的中心向量初始化滤波权重。
图2为bi-gram 滤波器(卷积核)嵌入层处理过程的例子,其中灰色区域为width{2,3,4}的随机参数滤波器,蓝色区域为簇的质心向量。

c: Incaps and Ourcaps Layers
一个胶囊是神经元的集合,代表一个特定类型的对象的实例化参数。胶囊的一个优点是,它们提供了一种有效的方法来模拟人类的感知系统,从而识别部分-整体的关系。
Incaps是第一个胶囊层,由Conv层的数据转换构造而成。这种转换允许Conv层的输出直接用作动态路由方法的输入。Outcaps是第二封装层,由Incaps层通过路由方法产生。
动态路由[27]算法的主要思想是确定一组耦合系数。算法不翻译了哈,感兴趣的再详细看。


d: Classcaps
基网络的最后一层是Classcaps层。使用动态路由由Outcaps构建Classcaps层。这一层中胶囊的数量取决于情感分类任务的规则,其中胶囊的长度代表每个类存在的概率。
2) RULE NETWORK
胶囊中的每个神经元不仅代表句子层次的特征(单词、实体、长度等),还代表该实例是否包含特定结构(如句子结构),以及该结构中的每个元素如何对情绪分类作出贡献。在本节中,我们设计了一个网络,允许网络从句子结构中学习。
与基础网络不同的是,规则网络被用来建模句子的结构特征。第一和第二层分别是embedding层和conv层,然后是两个胶囊层:Incap和outcap层。在规则网络中,我们在Outcaps和Classcaps层之间有一个Rulecaps层,这与基础网络不同。
在规则网络中,嵌入层的输入是转换词背后的原因。所以在outcaps中,学习到的信息是一种文本表征,包括特定的句子结构。
Rulecaps:Rulecaps的输入来自的Outcaps层的输出。具体来说,将base和rule网络的outcap层的输出并行连接,然后将其发送到一个动态路由算法中,得到规则网络的最终Classcaps层。因此,最终输出层的胶囊将由整个句子和子句的特征信息组成。
但在使用动态路由算法构建Rulecaps的过程中,迭代值过大会导致感知结构信息的过拟合。因此,我们在算法1的softmax操作中加入了一个温度参数,增加了这些子句对更高级别胶囊网络的贡献。
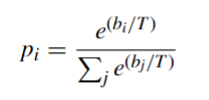
D. TRAINING OBJECTIVE
我们方法的训练目标由两部分组成。一个用于情绪分类器,另一个用于最小化源特征和目标特征之间的距离。我们使用 margin loss 来实现情感分类目标,并使用 deep CORAL loss 来最小化源域和目标域之间的差异。
1) SENTIMENT CLASSIFICATION LOSS
受Sabouret al.[27]提出的CapsNet的启发,我们设计了一个将句子结构知识整合到网络中的双分支目标函数。对于情感分类,第一个分支的目标是最大限度地提高Base Network正确情感的主动概率(active probability)。我们采取hingeloss



IV. EXPERIMENTAL SETUP
A. EXPERIMENTAL DATA
Amazon Review dataset
我们使用了四个产品领域的刊物,包括DVD (D),厨房(K),书籍(B)和电子(E)。

箭头的左边对应于源域,而箭头的右边是目标域。
对于训练集的每一个源域,我们分别随机抽取正极和阴性样本800个。
对于测试集,我们从目标域中随机选择400个评论(200个正的和200个负的),剩下的1600个评论用于在训练过程中最小化源域和目标域之间的差异。

B. MODEL CONFIGURATIONS
1)sentence structure:
在对模型进行训练之前,我们通过句子过渡结构对数据进行预处理,提取过渡(transition)词后的分句作为训练样本的一部分。例如however,过渡词是很强的指示词,它表明过渡词后面的词通常承载着整个复习的情绪。比如说,假设一个句子包含两个从句,但是由过渡词连接起来,但是后面的条款却代表整个整体的情感。

2)hyper-parameter adjustment:
在所有的实验中,我们将卷积核的kernel size分别设置为{1,2,3,4,5},数量设置为100。滤波器初始化选择500个pivots特征。我们使用在英语谷歌新闻语料上训练的300维的word2vec来初始化单词嵌入。其他

剩下的直接看看就好