参考:
https://blog.csdn.net/scotfield_msn/article/details/69075227
Mr.Scofield http://blog.csdn.net/scotfield_msn/article/details/69075227
https://tensorflow.google.cn/tutorials/text/word_embeddings
一、将文本表示为数字
1.1、独热码
1.2、用唯一的数字编码每个单词
1.3、词嵌入
1.3.1、概念

二、word embeddings的简单应用
2.1、embedding layer
嵌入层可以理解为一个查询表,它从整数索引(表示特定单词)映射到稠密向量(它们的嵌入)。嵌入的维数(或宽度)是一个参数,您可以用它来试验看看什么对您的问题有效,这与您在稠密层中试验神经元的数量非常相似。
2.1.1、使用Keras创建一个embeddings layer
# embedding layer 可以看作一个查找表,index(代表特定的词) -> dense vectors(代表embeddings)
embedding_layer = layers.Embedding(1000, 5)创建嵌入层时,嵌入的权重是随机初始化的(与任何其他层一样)。在训练过程中,通过反向传播逐步调整。一旦训练好了,习得的单词嵌入将大致编码单词之间的相似性(因为它们是针对您的模型所训练的特定问题而学习的)。
如果你将一个整数传递给一个嵌入层,结果会用嵌入表中的向量替换每个整数:
result = embedding_layer(tf.constant([1, 2, 3]))
print(result.numpy)
print(result.shape)
<bound method _EagerTensorBase.numpy of <tf.Tensor: id=15, shape=(3, 5), dtype=float32, numpy=
array([[ 0.03555963, -0.02336618, -0.02792581, 0.02153123, -0.00080024],
[ 0.01049923, 0.02071321, -0.00729645, 0.00019827, 0.02012112],
[-0.03894432, 0.01516298, -0.03782441, 0.03441912, 0.04282563]],
dtype=float32)>>
(3, 5)对于文本或序列问题,嵌入层采用整数的二维张量,shape(样本,sequence_length),其中每个条目都是整数序列。它可以嵌入可变长度的序列。您可以将形状(32、10)(长度为10的32个序列的批次)或(64、15)(长度为15的64个序列的批次)输入到上述的嵌入层中。
返回的张量比输入多一个轴,嵌入向量沿着新的最后一个轴对齐。传递一个(2,3)输入批处理,输出为(2,3,n)
result = embedding_layer(tf.constant([[0,1,2],[3,4,5]]))
print(result.shape)
(2, 3, 5)2.2、训练
在本教程中,您将在IMDB电影评论上训练一个情感分类器。在这个过程中,模型将从头开始学习嵌入式。我们将使用一个预处理的数据集。
2.2.1、加载数据集
# imdb 数据集
(train_data, test_data), info = tfds.load(
'imdb_reviews/subwords8k',
split = (tfds.Split.TRAIN, tfds.Split.TEST),
with_info=True,
as_supervised=True)获取编码器(tfd .features.text. subwordtextencoder),并快速查看词汇表。
词汇表中的"_"表示空格。请注意词汇表如何包括完整的单词(以"_"结尾)和部分单词,它可以用来构建更大的单词:
# tfds.features.text.SubwordTextEncoder
encoder = info.features['text'].encoder
print(encoder.subwords[:20])
['the_', ', ', '. ', 'a_', 'and_', 'of_', 'to_', 's_', 'is_', 'br', 'in_', 'I_', 'that_', 'this_', 'it_', ' /><', ' />', 'was_', 'The_', 'as_']电影评论长度不同, 使用padded_batch方法标准化评论的长度
# 电影评论长度不同, 使用padded_batch方法标准化评论的长度
padded_shapes = ([None],())
train_batches = train_data.shuffle(1000).padded_batch(10, padded_shapes = padded_shapes)
test_batches = test_data.shuffle(1000).padded_batch(10, padded_shapes = padded_shapes)
print("train_batches", train_batches)
train_batch, train_labels = next(iter(train_batches))
print(train_batch[:20])2.2.2、创建模型
# 创建模型
embedding_dim=16
model = keras.Sequential([
layers.Embedding(encoder.vocab_size, embedding_dim),
layers.GlobalAveragePooling1D(),
layers.Dense(16, activation='relu'),
layers.Dense(1, activation='sigmoid')
])
print(model.summary())
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
embedding_1 (Embedding) (None, None, 16) 130960
_________________________________________________________________
global_average_pooling1d (Gl (None, 16) 0
_________________________________________________________________
dense (Dense) (None, 16) 272
_________________________________________________________________
dense_1 (Dense) (None, 1) 17
=================================================================
Total params: 131,249
Trainable params: 131,249
Non-trainable params: 0
_________________________________________________________________
None
model.compile(optimizer='adam',
loss='binary_crossentropy',
metrics=['accuracy'])
history = model.fit(
train_batches,
epochs=10,
validation_data=test_batches, validation_steps=20)2.2.3、准确性
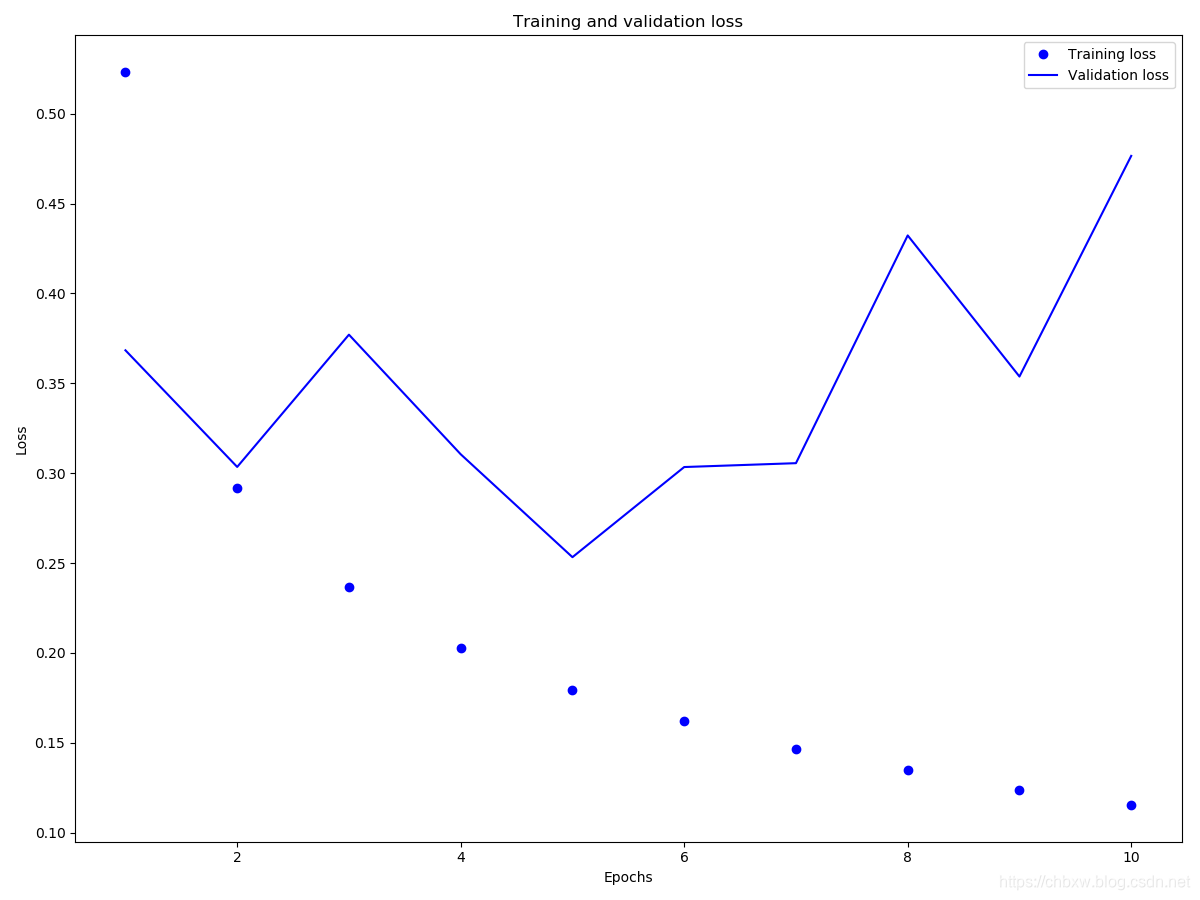
def plotHistory(history):
import matplotlib.pyplot as plt
history_dict = history.history
acc = history_dict['accuracy']
val_acc = history_dict['val_accuracy']
loss = history_dict['loss']
val_loss = history_dict['val_loss']
epochs = range(1, len(acc) + 1)
plt.figure(figsize=(12,9))
plt.plot(epochs, loss, 'bo', label='Training loss')
plt.plot(epochs, val_loss, 'b', label='Validation loss')
plt.title('Training and validation loss')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend()
plt.show()
plt.figure(figsize=(12,9))
plt.plot(epochs, acc, 'bo', label='Training acc')
plt.plot(epochs, val_acc, 'b', label='Validation acc')
plt.title('Training and validation accuracy')
plt.xlabel('Epochs')
plt.ylabel('Accuracy')
plt.legend(loc='lower right')
plt.ylim((0.5,1))
plt.show()
plotHistory(history) 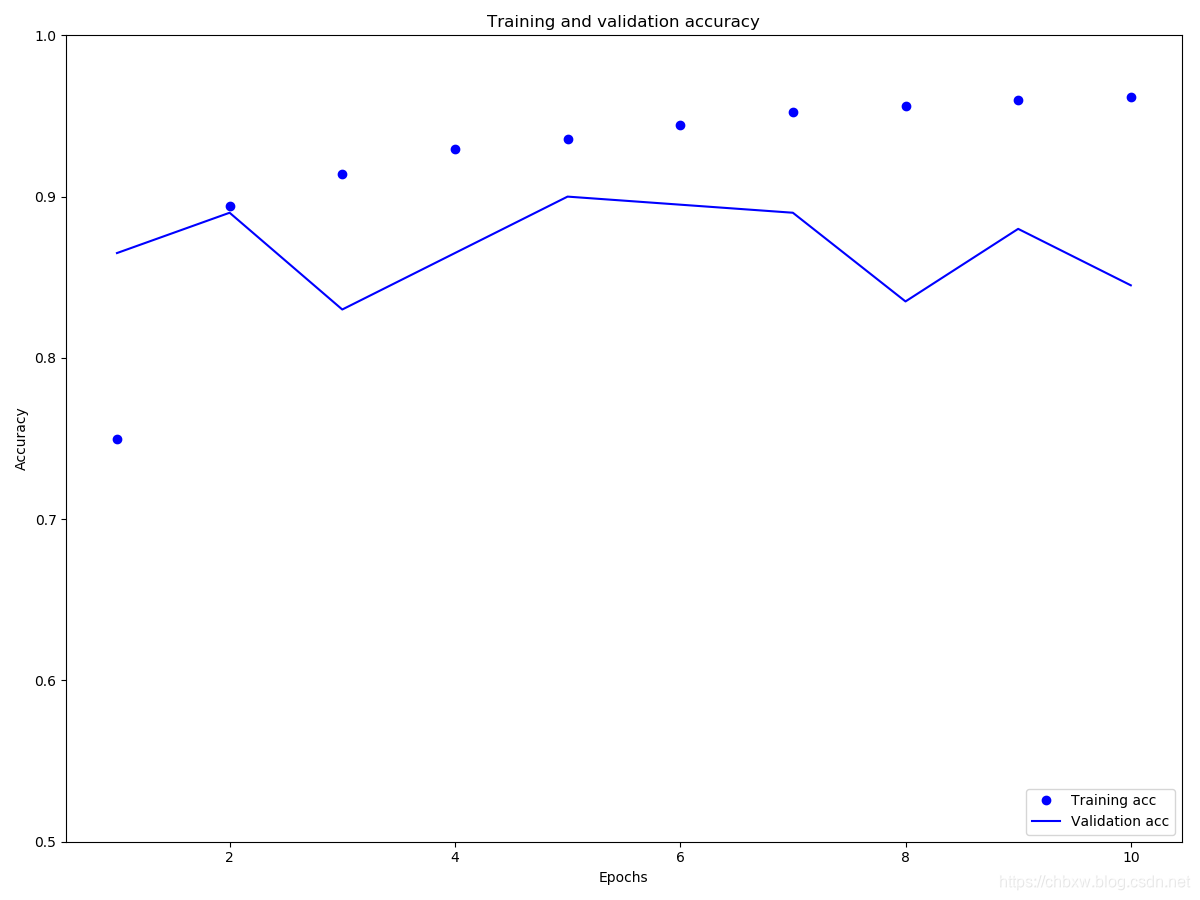
2.2.4、可视化
e = model.layers[0]
weights = e.get_weights()[0]
print(weights.shape) # shape: (vocab_size, embedding_dim)
# (8185, 16)
import io
encoder = info.features['text'].encoder
out_v = io.open('vecs.tsv', 'w', encoding='utf-8')
out_m = io.open('meta.tsv', 'w', encoding='utf-8')
for num, word in enumerate(encoder.subwords):
vec = weights[num+1] # skip 0, it's padding.
out_m.write(word + "\n")
out_v.write('\t'.join([str(x) for x in vec]) + "\n")
out_v.close()
out_m.close()
try:
from google.colab import files
except ImportError:
pass
else:
files.download('vecs.tsv')
files.download('meta.tsv')