版权声明:博主原创文章,转载请注明来源,谢谢合作!!
https://blog.csdn.net/hl791026701/article/details/84351289
Word embeddings
词语和句子的嵌入已经成为了任何基于深度学习的自然语言处理系统必备的组成部分,它们将词语和句子编码成稠密的定长向量,从而大大地提升通过神经网络处理文本数据的能力。当前主要的研究趋势是追求一种通用的嵌入技术:在大型语料库中预训练的嵌入,它能够被添加到各种各样下游的任务模型中(情感分析、分类、翻译等),从而通过引入一些从大型数据集中学习到的通用单词或句子的表征来自动地提升它们的性能。在过去的五年中,人们提出了大量可行的词嵌入方法。目前最常用的模型是 word2vec 和 GloVe,它们都是基于分布假设(在相同的上下文中出现的单词往往具有相似的含义)的无监督学习方法。
尽管此后有一些研究通过引入语义或者句法的监督信息来增强这些无监督方法,但是纯粹的无监督学习方法在 2017 年到 2018 年得到了令人关注的提升的是「FastText」(word2vec 的一种拓展)。
- lecture slides
- 搜集的一些视频: course intro, lecture, seminar
- Stanford CS224N的讲座视频 - intro, embeddings (english)
词向量空间分布

三种常见的词向量表达方法
- On hierarchical & sampled softmax estimation for word2vec page
- GloVe project page
- FastText project repo
- Semantic change over time - oberved through word embeddings - arxiv
word2vec
Word2vec就是用来将一个个的词变成词向量的工具。 包含两种结构,一种是skip-gram结构,一种是cbow结构,skip-gram结构是利用中间词预测邻近词,cbow模型是利用上下文词预测中间词 :
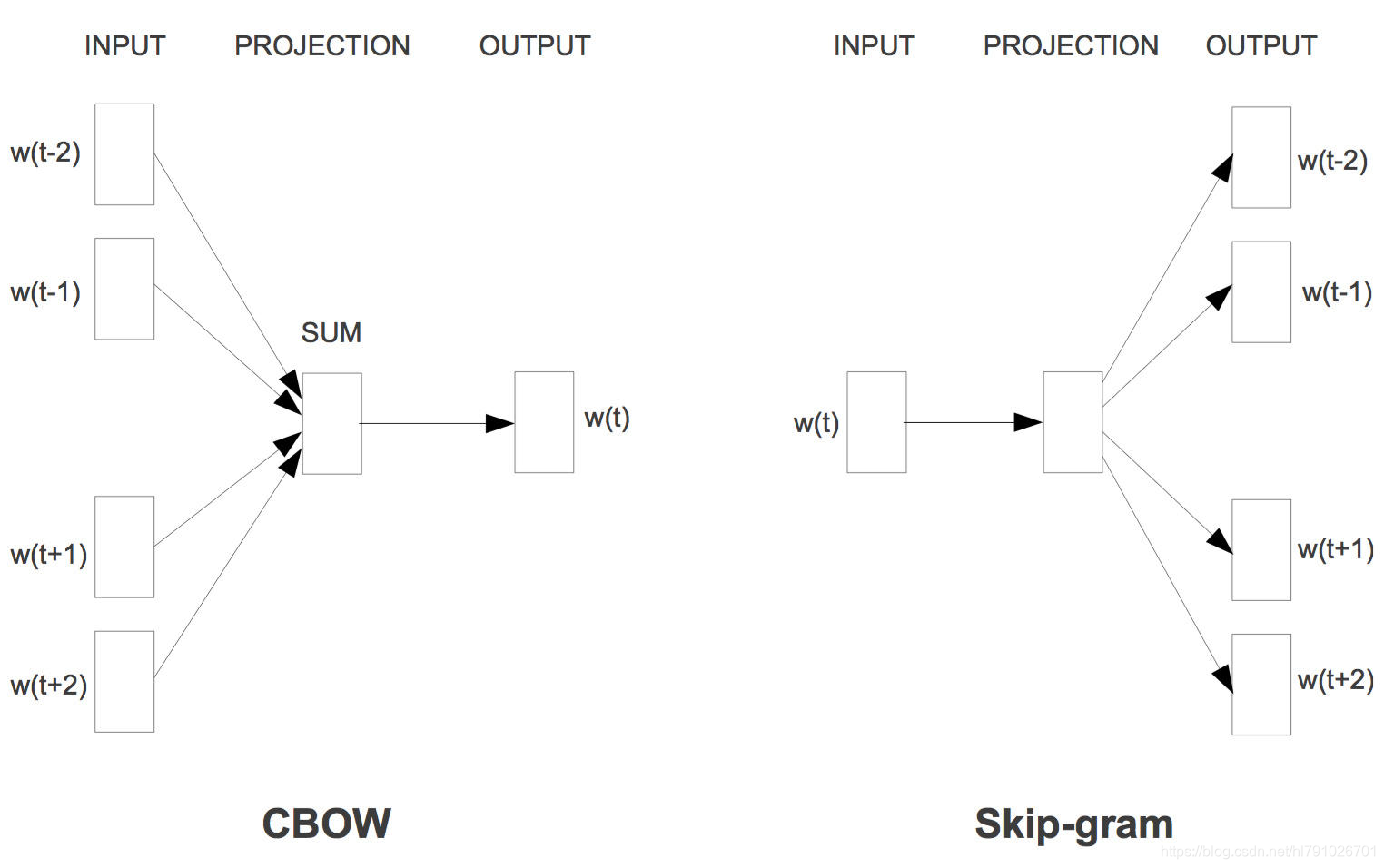
- CBOW(Continuous Bag-of-Words Model)是一种根据上下文的词语预测当前词语的出现概率的模型,其图示如上图左。CBOW是已知上下文,估算当前词语的语言模型;而Skip-gram只是逆转了CBOW的因果关系而已,即已知当前词语,预测上下文,其图示如上图右,最后在输出层加上Hierarchical Softmax(层次Softmax)和Negative Sampling(负采样)两个降低复杂度的近似方法。
- Hierarchical Softmax使用的办法其实是借助了分类的概念。假设我们是把所有的词都作为输出,那么“足球”、“篮球”都是混在一起的。而Hierarchical Softmax则是把这些词按照类别进行区分的,二叉树上的每一个节点可以看作是一个使用哈夫曼编码构造的二分类器。在算法的实现中,模型会赋予这些抽象的中间节点一个合适的向量,真正的词会共用这些向量。这种近似的处理会显著带来性能上的提升同时又不会丢失很大的准确性。
- Negative Sampling也是用二分类近似多分类,区别在于它会采样一些负例,调整模型参数使得可以区分正例和负例。换一个角度来看,就是Negative Sampling有点懒,它不想把分母中的所有词都算一次,就稍微选几个算算。
- 如果感兴趣具体的推到和原理可以看这里 :word2vec原理推导与代码分析 , word2vec、glove和 fasttext 的比较
Glove
GloVe和word2vec的思路相似 但是充分考虑了词的共现情况,以及其他一些trick来进行传统矩阵分解运算进而得到word vectors,比率远比原始概率更能区分词的含义。
GloVe 算法包含以下步骤:
- 使用词共现矩阵收集词共现信息。每个 Xij 元素代表词汇 i 出现在词汇 j上下文的概率。一般我们需要扫描一遍我们的语料库:对于每一个字段,我们查看在这个字段之前或者之后,使用 window_size 定义的一定范围内的上下文。一个词距离这个字段越远,我们给予这个词的权重越低。一般使用这个公式:
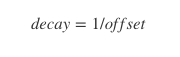
- 对于每一组词对,
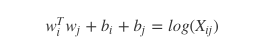
这里 wi 向量代表主词,wj 代表上下文词的向量。bi, bj 是主词和上下文词的常数偏倚。 - 定义损失函数
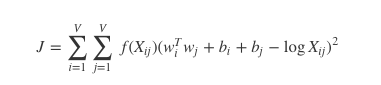
这里 f 是帮助我们避免只学习到常见词到一个权重函数。GloVe 到作者选择如下到函数:
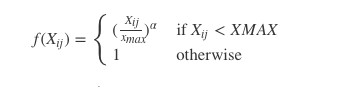
上面说到,GloVe每个词涉及到两个词向量,一个词语本身的向量wi,一个词的context向量w~i。最初这样设计,将word和context的向量分开,不用一套,是为了在更新参数的时候能够简单地套用SGD。
但是呢,我们可以看到,公式本身是对称的,context和word其实并没有什么区别。
那么两个向量应该是一样语义空间中的差不多的词向量,context word vector这个副产品自然不能落下,GloVe经过一番试验,最终发现,两个向量加起来最后起到的效果最好。
GloVe 使用
GloVe已经在github开源,源码以及binary可以在GloVe Github找到。
GloVe的代码写的比较糙,每一步是独立的程序,因此要按照以下步骤进行:
- 运行./vocab_count 进行词频统计
- 运行./cooccur 进行共现统计
- 运行./shuffle 进行打散
- 运行./glove 进行训练词向量
简单的应用
- glove+LSTM: 命名实体识别
- 用(Keras)实现,glove词向量来源: http://nlp.stanford.edu/data/glove.6B.zip- 用(Keras)实现,glove词向量来源: http://nlp.stanford.edu/data/glove.6B.zip
- 一开始输入的是7类golve词向量。The model is an LSTM over a convolutional layer which itself trains over a sequence of seven glove embedding vectors (three previous words, word for the current label, three following words).
- CV分类准确度和加权F1约为98.2%。 为了评估测试集的性能,我们将每个CV折叠的模型输出和预测的平均值进行整合。
来源于github:https://github.com/thomasjungblut/ner-sequencelearning
FastText
FastText, 一种技术, 也是 An NLP library by Facebook.
它由两部分组成: word representation learning 与 text classification.
fastText简单来说就是将句子中的每个词先通过一个lookup层映射成词向量,然后对词向量取平均作为真个句子的句子向量,然后直接用线性分类器进行分类,从而实现文本分类,不同于其他的文本分类方法的地方在于,这个fastText完全是线性的,没有非线性隐藏层,得到的结果和有非线性层的网络差不多,这说明对句子结构比较简单的文本分类任务来说,线性的网络结构完全可以胜任,而线性结构相比于非线性结构的优势在于结构简单,训练的更快。
这是对于句子结构简单的文本来说,但是这种方法显然没有考虑词序信息,对于那些对词序很敏感的句子分类任务来说(比如情感分类)fastText就不如有隐藏层等非线性结构的网络效果好,比如线面这几个句子是对词序很敏感的类型:
‘The movie is not very good , but i still like it . ’
‘The movie is very good , but i still do not like it .’
‘I do not like it , but the movie is still very good .’
这几个句子的词序差不多,用到的词也差不多,但是表达的意思是完全相反的,如果直接把词向量取平均,显然得到的平均词向量也是相差不到,在经过线性分类器分类很容易把这两个不同的类别分到同一类里,所以fastText很难学出词序对句子语义的影响,对复杂任务还是需要用复杂网络学习任务的语义表达。
原理
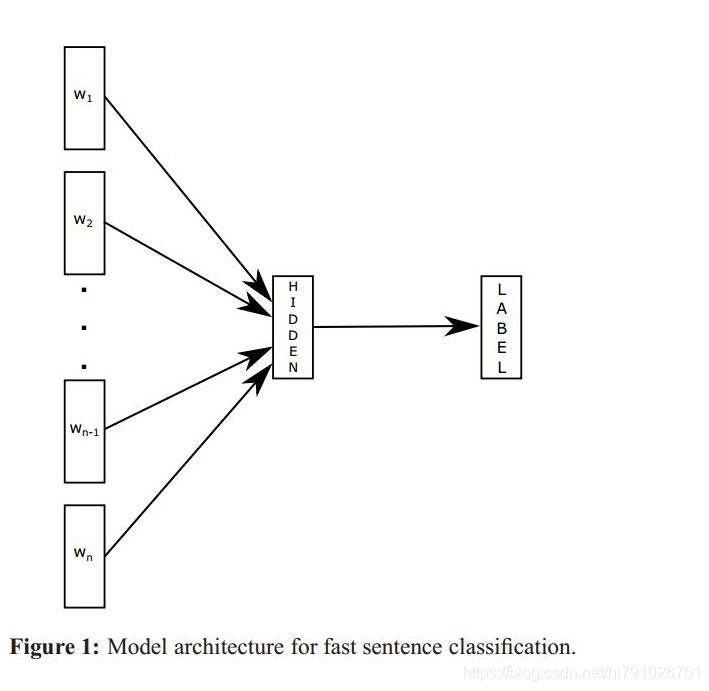
FastText优势
适合大型数据+高效的训练速度:能够训练模型“在使用标准多核CPU的情况下10分钟内处理超过10亿个词汇”,特别是与深度模型对比,fastText能将训练时间由数天缩短到几秒钟。使用一个标准多核 CPU,得到了在10分钟内训练完超过10亿词汇量模型的结果。此外, fastText还能在五分钟内将50万个句子分成超过30万个类别。
Fasttext使用
- 安装
pip install fasttext
- 文本分类
输出数据格式: 样本 + 样本标签 :
ex:
outline = outline.encode("utf-8") + "\t__label__" + e + "\n"
ex :姚 明 喜 欢 打 篮 球 __label__1
classifier = fasttext.supervised('data.train.txt', 'model', label_prefix='__label__')
- 测试模型和使用模型分类
#加载模型
classifier = fasttext.load_model("fasttext.model.bin",label_prefix = "__label__")
# 测试模型 其中 fasttext_test.txt 就是测试数据,格式和 fasttext_train.txt 一样
result = classifier.test("fasttext_test.txt")
result = classifier.predict([line])
- 生成词向量
输入数据格式和上面一样
model = fasttext.skipgram("all.train.txt", "model",dim = 300)
这其中还有一些其他的配置参数可以选择,具体的参数可以查看参考文献。
训练完成之后,会产生模型文件bin和词向量文件vec,词向量文件里面第一行是字典的长度和维度,下面是具体的词向量。
参考:
文本分类(六):使用fastText对文本进行分类–小插曲
使用fasttext完成文本处理及文本预测
相关论文
-
Distributed Representations of Words and Phrases and their Compositionality Mikolov et al., 2013 [arxiv]
-
Efficient Estimation of Word Representations in Vector Space Mikolov et al., 2013 [arxiv]
-
Distributed Representations of Sentences and Documents Quoc Le et al., 2014 [arxiv]
-
GloVe: Global Vectors for Word Representation Pennington et al., 2014 [article]
Multilingual Embeddings. Unsupervised MT.
-
Enriching word vectors with subword information Bojanowski et al., 2016 [arxiv]
-
Exploiting similarities between languages for machine translation Mikolov et al., 2013 [arxiv]
-
Improving vector space word representations using multilingual correlation Faruqui and Dyer, EACL 2014 [pdf]
-
Learning principled bilingual mappings of word embeddings while preserving monolingual invariance Artetxe et al., EMNLP 2016 [pdf]
-
Offline bilingual word vectors, orthogonal transformations and the inverted softmax [arxiv]
Smith et al., ICLR 2017 -
Word Translation Without Parallel Data Conneau et al., 2018 [arxiv]