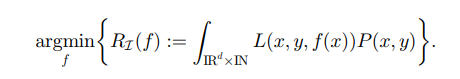要解决的问题
对于目标检测来说,我们一般是用有标注的数据集进行训练或者有少量标注的数据集进行半监督学习
但有些物体是没有被标注或者标注的很少,或者这个物体根本没有被定义
对于一些二分类问题,因正样本数量远小于负样本,我们一般是对正样本进行建模,而不怎么关心负样本
这篇文章就是提供了解决这种问题的方法
一些度量标准
作者用一个公式描述了一个模型的开放程度

给人感觉是利用已有的一些类建立一个模型,然后这个模型能分出多个从来没有出现过的类
emmmm,这个东西,给人感觉是 提取图片特征 + 聚类,具体怎么做的,,,我们接着看
具体做法
对于分类任务,分类器必须支持拒绝(不是任何一类 )
首先是使用了一个SVM,将数据分为离训练集非常近的和非常远的两种,我们需要知道,未知的类别离已知的类别最远可以有多远
对于分类任务,我们不能简单的使用SVM取maximum gap
因为这样虽然会将已知的两类A,B很好的分开但是不一定能将A与未知的类C很好的分开
但如果我们的SVM用于是A,不是A分这两类的话,那就没有这个问题了,这个在文中被称为1-vs-set
将一类与其他的分开,文中使用了两个边界
一般来说loss是这样的