5 记录地点:建图模块
在场景识别或导航中,当前观测信息需要与系统参考地图(机器人对世界感知的表示)不断地进行比较。地图根据可用数据和场景识别的类型,选择不同的框架。表I列出了建图方法的分类,分类方法取决于地图抽象程度以及地点描述子是否包括度量信息。列表中内容最详实的地图框架是拓扑度量(拓扑)图。全局度量图仅在小的地理区域范围内可行,但是可以将拓扑图融合到全局度量图中来改善这一点[140]。所以,对于场景识别,任何全局度量图可以被认为是单节点拓扑图。
A.纯图像检索
场景识别中最抽象的地图框架是仅存储环境中每个地点的外观信息,而没有位置信息。纯图像检索的匹配仅基于外观相似性,应用了计算机视觉中一般的图像检索技术[3] ,而不是专门针对场景识别的技术。虽然相对位置信息缺失,但索引更高效。
场景识别的一个关键问题是系统可扩展性——当机器人访问的地方越来越多时,存储需求将增加,搜索效率将会降低。因此,设计地图时要保证数据规模较大时的效率。如果用词袋模型(BOW)来量化描述子空间,反向索引则可以加速图像检索; 针对图像中的词来存储图像ID号,而不是针对图像ID来存储词。反向索引不需要对数据库中的所有图像进行线性搜索,就可以快速排除不可能的图像。
Schindler 等人 [3]使用分层词汇树[95]来实现城市数据集场景识别(20公里的遍历具有大约1亿特征)。文章表明,如果只使用来自每个图像中最独特的特征,则场景识别性能提高,其中信息增益通过条件熵计算。Li和Kosecká[141]研究了在较少特征集时,如何改进场景识别性能。
FAB-MAP 2.0 [87],[142]使用词袋模型的反向索引,演示了1000公里路径的视觉场景识别。Schindler等人 [3]使用投票方案来匹配位置,其中应用了FAB-MAP概率模型,该概率模型包括negative observations(没有出现在图像中的词)以及反向索引之前需要简化的positive observations。
场景识别系统在处理地点和词汇信息时使用分层搜索,效率更高。Mohan等人 [143]使用cooccurent特征矩阵来预选匹配的环境。然后搜索空间被限制在预选的环境子集中,增加了场景识别的效率。
B.拓扑地图
纯拓扑图包含关于地点的相对位置关系信息,但不包括这些地方如何相关的度量信息[5],[6],[118],[119]。拓扑信息可以增加地点匹配的正确率,减少误匹配[14],[84]。类似FAB-MAP的概率系统,给定先验的位置均值,可以作为纯图像检索运行,不过通过贝叶斯滤波或类似技术,将图像处理信息加入时,性能得到改善。
图像检索技术通过使用反向索引来提高效率,而拓扑图可以使用位置信息来加速匹配过程,即,场景识别系统仅需要对接近机器人当前位置的地点进行搜索。基于采样的方法,如粒子滤波器,可以用来对可能的位置采样[12,13],[111],[144]。当机器人定位良好时,找出最大概率的位置,并且这个位置距离当前机器人位置较近,则对该粒子进行重新采样,如果机器人丢失位置信息,颗粒会散布在整个环境中。计算时间与粒子的数量成比例,与环境大小无关[145]。
另外,由于环境中闭环具有稀疏性,Latif等人 [19]使用拓扑信息将场景识别描述为稀疏凸L1-最小化问题,并用同伦法[146]进行闭环检测。
将拓扑信息加到场景识别中后,识别过程就可以使用低分辨率数据,对存储器的需求也会降低。使用稀疏凸L1的最小化公式,在少至48个像素的图像中也可以[19] 识别地点。当图像模糊或在不同条件下(比如一天中不同的时间点)观测时,视觉场景识别系统应用拓扑信息,可以在少至32个像素(4通道)的图片中实现。
C. 拓扑-度量混合地图
拓扑信息的添加可以使图像检索性能增强,而加入度量信息(距离、方向)则可以改善拓扑地图。例如,FAB-MAP [6]和SeqSLAM [118]都是拓扑系统,但是他们分别在CAT-SLAM [13]和SMART [148]算法中加入度量信息,系统的场景识别性能得到改善。
拓扑-度量地图是基于外观的,度量信息是指位置节点之间的相对位姿[149]–[152]。但是,每个地点内的地标或物体信息存储在每个节点中[1],[2],[26],[140],[153] - [156]。拓扑位置节点内的度量信息可以存储为稀疏地标图[2],[7],[76],或稠密占用栅格地图[134](如果从图像数据可以提取出深度信息)。Moravec和Elfes [39]在1980年代中期,提出用截断符号距离函数表示密集空间模型的概念,但这种技术在近几年GPU技术出现后才变得可行。
6 场景识别:置信度生成模块
从根本上讲,场景识别系统是用来判断观测到地方是否到过。因此,任何场景识别系统的目标是通过视觉输入与地图数据的匹配,产生置信分布。该分布表征当前视觉输入与机器人地图中地点信息匹配的相似度或置信度。一般情况下,如果两个地方描述相似,则它们在相同物理位置的可能性就大,而相似到何种程度时才能做出判断,这取决于具体环境。例如,由于感知偏差,不同的地方难以区分,会被误判为相同的环境。相反,变化的条件可能导致相同的地方,在不同的时间差异较大。
A. 场景识别和SLAM
场景识别可以提供闭环检测,它在Pose-GraphSLAM算法中具有重要作用[157]。姿态图,也是基于视图的表示方法[158],[159],广泛应用于现代SLAM系统中,因为对于固定大小的地图,它们的计算效率比较高,尽管它们在长时间运行时增加了计算要求。对于连续建图,闭环检测是非常重要的,因为它可以校正里程计带来的漂移[160],[161]。闭环一般是从在线局部地图更新步骤中检测出来的,许多系统可以一边执行类似SLAM的局部度量校正,一边进行拓扑式闭环校正[1],[2],[80],[161];系统可以使用激光扫描数据[80],[161]或视觉里程计[1],[2]进行局部度量校正,同时有一个独立的全局匹配过程来进行闭环检测。
如果地点描述是基于外观的,并且地点内部不包含任何度量信息,但是地图中包含地点之间的度量距离,则系统仍然可以使用闭环在地点层级上进行度量校正[149] - [152]。但是,如果地点描述中包含与图像特征的度量信息,如FrameSLAM [2]的情况,则可以执行更精确的校正。对于纯拓扑的地图没有度量校正,这是拓扑层级的定位, 也就是说,系统只简单地识别最可能的位置。
如果地图中包含描述地点和地点之间的度量信息,那它可以用来解决全度量SLAM问题。目前可用的SLAM技术比较广泛,见[162] - [164]。Thrun和Leonard [164]验证了三个关键的SLAM问题:扩展卡尔曼滤波器(EKF)[37],[38],[165] - [167]、Rao-Blackwellized粒子滤波器[168]以及上面讨论的姿态图 [160],[161],[169] - [171]。基于视觉的系统可以利用这些方法:EKF用于MonoSLAM [7],Rao-Blackwellized粒子滤波器用于[12],[172]和[173],而姿态图优化技术用于[2] 174]。
B. 拓扑场景识别
如果多个数据通道可用,我们可以使用投票方案[3],[5],[79],[96],[175]。Ulrich和Nourbakhsh [5]使用多个色标,每个色标投票给它认为最可能的位置。根据投票结果,该系统可分为三类:可信的,不确定的或混淆的。如果置信色标投票一致并且总置信度高于某一阈值,则系统对的定位可信; 如果没有一个色标足够可信或总的置信度值太低,那么系统的定位是不确定的; 如果不同的置信色标投票也不一致,则系统是混淆的。
如果系统使用基于文本分析的词袋模型,它可以利用词频-逆文档频率(TF-IDF)得分[56],[114],[176 ]。图像中的每个视觉词具有TF-IDF得分,有两个部分组成:TF词频,指词条在图像中出现的频率;以及IDF逆文档频率,测量词条在所有图像中的频率。TF-IDF得分是这两个值的乘积。
地点匹配度是根据贝叶斯定理计算出来的。早期基于外观定位的概率表示方法有如下几种:高斯函数[177]、高斯混合结合期望做大化[178]或者加入Parzen平滑的高斯内核[179][104]。如果使用词袋模型的话[83],[180]也可以利用TF-IDF来计算观测似然度。Siagian和Itti [111],[181]在两个观测更新步骤中通过观测似然进行蒙特卡罗定位,观测似然包括局部特征似然和物体似然。Garcia-Fidalgo和Rodriguez [182]使用了观测似然,该似然将两个图像之间的特征匹配的数量与图像中特征的总数相关联,然后进行归一化。
观测似然性也可以通过数据驱动方法计算。FAB-MAP[6],[87]就使用了数据驱动方法计算观测似然,它是一种基于外观的概率定位系统。FAB-MAP使用的词袋模型是通过SIFT或SURF特征进行图像描述的,并在训练阶段计算每个词的独特性。由于词袋模型中可能包含许多单词(FAB-MAP中有100000词汇[87]),观测词的完全联合概率分布[见图6(a)]可以通过朴素贝叶斯假设或Chow–Liu树近似[183] [见图6(b)]。
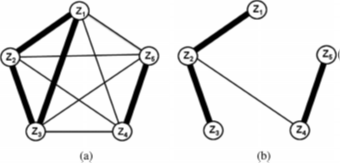
[图 6 FAB-MAP学习单词外观和场景识别之间关系的概率模型。(a)完全联合分布考虑单词之间的关系(词之间的粗线表示具有最大交互信息)。(b)Chow-Liu树将整个联合分布近似为连接树,其中每个单词仅取仅与另一个单词有关(来自184|)。
FAB-MAP处理感知混叠问题的时候,不仅考虑两个位置是否相似(它们具有许多共同的视觉词),而且还考虑共同的词是否足够特殊(使该地点相对于其他位置具有可区分性)。如果两个位置看起来类似,但是共有的特征出现频繁,那么将根据所有地点的信息集合(包括看到过的和未看到过的)计算出一个归一化常数,FAB-MAP将该常数作分母,从而降低匹配概率。
最初,我们通过从Chow-Liu树中随机采样来对未访问过的位置建模,当匹配概率大于某个阈值时,我们判断机器人处于某个位置时,其中阈值是用户定义的。然而,Paul和Newman [60],[62],[185]提出了一种迭代学习机制,生成一组代表世界外观真实分布的集合。Latent Dirichlet Allocation [186]将图像分成几个主题,总结了目前为止机器人所感知到的世界。利用这些主题可以生成与世界物体数量对应的采样集;例如,叶子在许多环境中出现,因此它不具有独特性。系统不断学习,获取更多的环境信息,不断优化采样集。此外,他们还提出在线-离线学习过程,在机器人的“停机时间”,可以通过互联网下载和处理相关图像数据。
Olson [187]观察到“正确的假设所得到的结果通常彼此一致,而不正确的假设得到的结果彼此不同”,并用这种方法来消除假阳性匹配,通过计算假设之间的成对一致性矩阵,从它的主特征向量中来找到一致性最强的假设组合。该论文还得出,产生置信匹配所需的信息量应该与机器人的位置不确定性相关。该系统要求局部假设匹配的物理空间大于机器人的位置不确定性,以确保机器人不会在其不确定性区域误定位[187]。
FAB-MAP要求匹配要求特征具有高区分度,上面提到的方法与之相反,它需要多个匹配,但是这些匹配不需要特别的可区分性,因为匹配之间的几何关系确保了假设的唯一性。
生物学启发式位置识别方法模拟了大鼠海马中已知的位置细胞结构[116],[188]。在RatSLAM [116]中,使用了一种称为连续吸引子网络(CAN)的神经网络来模拟位置细胞(见图7)。CAN结合自身运动和视觉感知信息,使用局部激励和全局抑制机制来定位。类似的,Giovannangeli等人[188]使用位置细胞模型,在没有度量地图的情况下,实现了室内和室外环境中的视觉导航。
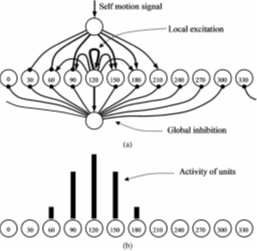
[图7 CAN是一种神经网络,用于模拟位置细胞,头向细胞和网格细胞的行为。(a)CAN用于模拟头向细胞。 每个细胞激发自身及临近细胞(见局部激发箭头)并抑制其他细胞。(b)运动输入会带来局部激发和全局抑制,这两项组合产生以120°为中心的稳定活动信息,它与里程计和视觉输入结合,激励附近的姿态细胞,抑制远处的细胞,从而进行场景识别116|)。
C. 场景识别系统的评估
通常根据精确度和召回率,以及他们之间的precision-recall关系曲线来评估拓扑场景识别系统性能。系统根据置信度测量来选择匹配,正确的匹配称为真阳性,不正确的匹配是假阳性,并且系统误丢弃的真匹配是假阴性匹配。精确度是指真阳性匹配在所选出的匹配中的比例,召回率是真阳性匹配与所有真匹配的总数的比例,即

完美的系统将达到100%的精确度和100%的召回率。精确度和召回率通常通过precision–recall曲线彼此相关,precision–recall曲线在置信度值范围描述了精确度和召回率的关系。
近期,场景识别优先避免假阳性匹配[6],因为将错误引入地图可能会导致灾难性的失败。因此,召回率100%是场景识别成功的关键指标。有一些方法使用拓扑信息来校正假阳性匹配[ 189 ]–[ 191 ],关注点也从消除假阳性转换到发现许多潜在的地点匹配,然后在拓扑后处理步骤中校正误匹配。当在动态环境中执行场景识别时,严格匹配方法可能会失败,增加潜在匹配的数目是特别重要的。
此外,随着场景识别系统从“演示”(通常具有预先记录的数据集)转变为“调度”(在自主车辆上实时操作),性能评估方法可能会进一步改变,以将环境中地点匹配的空间分布考虑在内。例如,McManus 等人 [192]使用“在行驶给定距离内没有匹配成功的概率”来判断场景识别系统是否成功。该方法可以得到地点匹配在环境中的分布情况,也能保证“包含场景识别模块的导航系统”的完整性。