摘要:我们着力于解决大规模地点识别的视觉问题,在该任务中需要快速、准确地识别给定查询图像的地点信息。本文主要有以下三个贡献:第一,我们针对地点识别问题以端到端的方式训练了一个卷积神经网络。该网络结构的主要组成部分NetVLAD是一个通用的新VLAD层,该层的提出主要源自于广泛应用在图像检索领域的特征“Vector of Locally Aggregated Descriptors”。该层可以很容易的嵌入到任何CNN网络,并且可以通过后向传播的方式进行训练。第二,利用来自Google Street View Time Machine具有GPS信息的图像数据集,基于一个新的弱监督排序损失以端到端的方式进行了训练过程。最后,提出的方法表现优异…
VLAD
输入N个D维的图像特征和K个聚类中心(“视觉单词”)
作为VLAD的参数,输出K×D维的图像VLAD特征V。V中的点(j, k)通过以下公式进行计算得到:
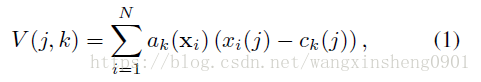
表示
是否属于第k个视觉单词,如果是的话该值为1否则为0。矩阵V之后通过列L2正则化(intra-normaliztion)形成一个向量,并再次进行L2正则化操作。
NetVLAD
为了能够将VLAD加入到CNN框架中并实现端到端的训练,需要把公式(1)中离散项进行连续化处理:
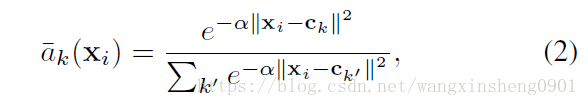
指定了xi到聚类类别ck的权重,其大小正比描述子到聚类中心的距离,范围为[0,1]。α是一个正常数,当期趋近于无穷大时
与原始的
表现一致,即其值取0或者1。
把公式(2)中的平方项展开,可以将分子和分母的公共项消除,从而得到:
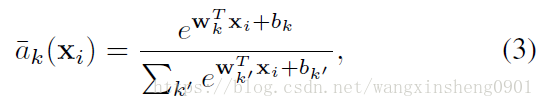
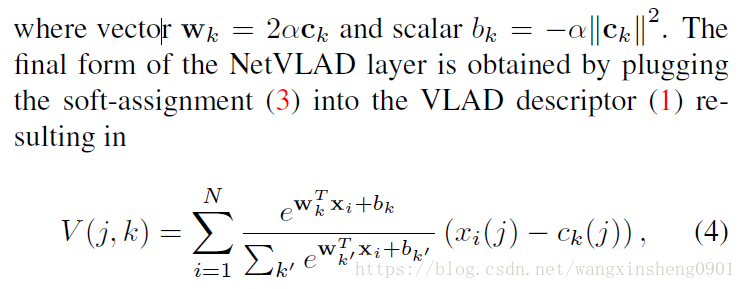
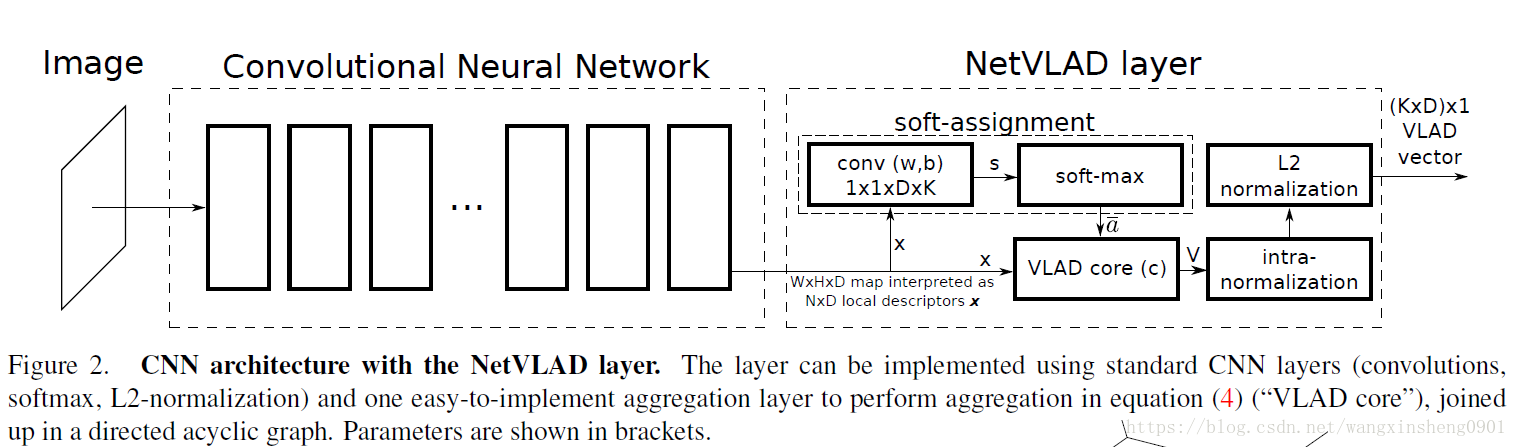
如上图所示,NetVLAD可以被分解为直接嵌入到CNN框架中的几个部分。从公式(4)可以看出,其第一个部分其实是一个soft-max公式

因此描述子xi到K类的分配过程可以分两步进行:1)K个空间大小为1×1的滤波器wk和偏置bk可以得到输出;2)卷积输出通过soft-max函数
获得最终的
。输出在正则化操作后得到一个(K×D)×1大小的描述子。
Triple loss
Google街景数据的特点是标记有GPS位置信息,但是在同一位置上拍摄的照片由于角度不同可能会得到完全不相关的图像,因此需要一些手段得到同一地点下与查询图像最为接近的图像:
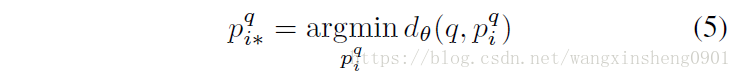
其中是一组可能与查询图像q相关的数据集,通过上式可得到最可能与查询图像匹配的图像。之后再借助与查询图像不相关的图像
可以组成用于训练triple loss的数据。据此定义三元组损失函数:
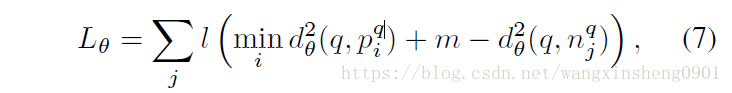
其中l是一个hinge loss l(x)=max(x,0), m是一个常数giving the margin.
本文的训练及测试代码:https://www.di.ens.fr/willow/research/netvlad/
初始化过程、训练的参数、获取三元组图像的过程以及其它细节:https://arxiv.org/abs/1511.07247