在机器学习的模型中,通常有两类参数,第一类是通过训练数据学习得到的参数,也就是模型的系数,如回归模型中的权重系数,第二类是模型算法中需要进行设置和优化的超参,如logistic回归中的正则化系数和决策树中的树的深度参数等。在上一篇文章中,我们通过验证曲线来寻找最优的超参,在这篇文章中,将通过一种功能更为强大的寻找超参的技巧:网格搜索,它可以寻找最优的超参组合,来提高模型的性能。
一. 网格(grid search)搜索寻找超参
网格搜索:网格搜索其实是一种暴力搜索参数的方法,它通过我们指定不同的超参列表进行穷举搜索,并计算每一个超参组合对于模型性能的影响,来获取最优的超参组合。下面通过sklearn来实现网格搜索寻找超参
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.preprocessing import LabelEncoder
from sklearn.pipeline import Pipeline
from sklearn.svm import SVC
from sklearn.model_selection import GridSearchCV
if __name__ == "__main__":
#读取数据
data = pd.read_csv("G:/dataset/wdbc.csv")
#获取X
X = data.ix[:,2:32]
#获取字符串类别标签
label_y = data.ix[:,1]
#将字符串的标签转为数字
label = LabelEncoder()
Y = label.fit_transform(label_y)
#将数据集分为训练集和测试集
train_x,test_x,train_y,test_y = train_test_split(X,Y,test_size=0.2,random_state=1)
#初始化一个流水线类
pipe = Pipeline([("std",StandardScaler()),
("clf",SVC(random_state=1))])
#定义参数的取值
param_range = [0.0001,0.001,0.01,0.1,1.0,10.0,100.0,1000.0]
#定义一个网格搜索的参数
'''
线性的SVM只需要,只需要调优正则化参数C
基于RBF核的SVM,需要调优gamma参数和C
'''
param_grid = [{"clf__C":param_range,
"clf__kernel":['linear']},
{"clf__C":param_range,
"clf__gamma":param_range,
"clf__kernel":['rbf']}]
#网格搜索超参
grid_search = GridSearchCV(estimator=pipe,param_grid=param_grid,
scoring="accuracy",cv=10,n_jobs=-1)
grid_search = grid_search.fit(train_x,train_y)
#获取模型的最优超参
print(grid_search.best_params_)
#{'clf__C': 0.1, 'clf__kernel': 'linear'}
#获取最好的结果
print(grid_search.best_score_)
#0.978021978022
通过上面的结果可以发现,当SVM的核为”linear”时,参数C为0.1时,模型获得最好的结果为97.8%。
测试模型在测试集上的准确率
clf = grid_search.best_estimator_
print(clf.score(test_x,test_y))
#0.964912280702
网格搜索是一种功能强大的寻找超参的方法,但是由于它在寻找超参的时候使用的是穷举法,需要评估所有的参数组合,所以计算成本也是非常高的。sklearn还提供一种随机网格搜索参数RandomizedSearchCV类,可以以特定的代价从抽样分布中随机抽取参数组合。
二. 嵌套交叉验证
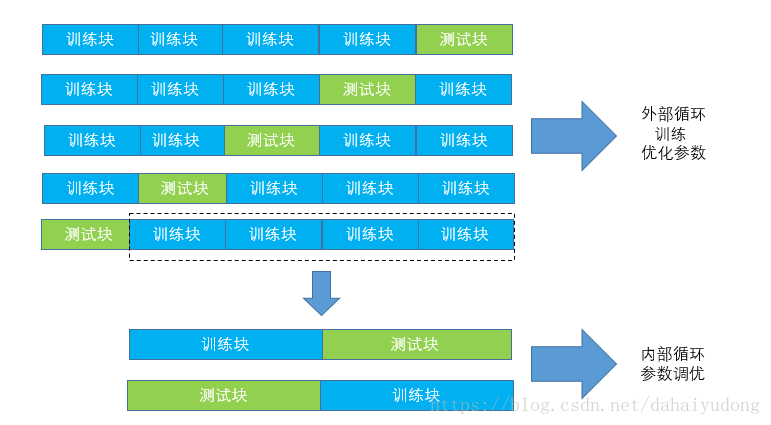
当我们需要在不同的机器学习算法中进行选择的时候,可以通过嵌套交叉验证来进行选择。在对于误差估计的偏差情形研究中表明:使用嵌套交叉验证,估计的真实误差与在测试集上得到的结果几乎没有差距。
嵌套交叉验证分为外部循环和内部循环,在外部循环中,我们将数据分为训练块和测试块。在内部循环中,我们将训练块分为训练块和测试块,在训练块上使用k折交叉验证,测试块用于对于模型进行评估,通过内部循环来进行模型选择。通过上图可以发现,外部循环由5个模块组合,内部循环由2个模块组成,因此嵌套交叉验证也被称为5×2交叉验证。下面通过sklearn来实现嵌套交叉验证
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.preprocessing import LabelEncoder
from sklearn.pipeline import Pipeline
from sklearn.svm import SVC
from sklearn.model_selection import GridSearchCV
from sklearn.model_selection import cross_val_score
if __name__ == "__main__":
#读取数据
data = pd.read_csv("G:/dataset/wdbc.csv")
#获取X
X = data.ix[:,2:32]
#获取字符串类别标签
label_y = data.ix[:,1]
#将字符串的标签转为数字
label = LabelEncoder()
Y = label.fit_transform(label_y)
#将数据集分为训练集和测试集
train_x,test_x,train_y,test_y = train_test_split(X,Y,test_size=0.2,random_state=1)
#初始化一个流水线类
pipe = Pipeline([("std",StandardScaler()),
("clf",SVC(random_state=1))])
#定义参数的取值
param_range = [0.0001,0.001,0.01,0.1,1.0,10.0,100.0,1000.0]
#定义一个网格搜索的参数
'''
线性的SVM只需要,只需要调优正则化参数C
基于RBF核的SVM,需要调优gamma参数和C
'''
param_grid = [{"clf__C":param_range,
"clf__kernel":['linear']},
{"clf__C":param_range,
"clf__gamma":param_range,
"clf__kernel":['rbf']}]
#网格搜索超参
grid_search = GridSearchCV(estimator=pipe,param_grid=param_grid,
scoring="accuracy",cv=5,n_jobs=-1)
scores = cross_val_score(grid_search,train_x,train_y,scoring="accuracy",cv=5)
print("CV accuracy:%.3f +/- %.3f"%(np.mean(scores),np.std(scores)))
#CV accuracy:0.978 +/- 0.012
通过嵌套交叉验证来判断决策树的表现性能
from sklearn.tree import DecisionTreeClassifier
param_range = [1,2,3,4,5,6,7,8,9,10]
grid_search = GridSearchCV(estimator=DecisionTreeClassifier(random_state=0),
param_grid=[
{"max_depth":param_range}
],scoring="accuracy",cv=5)
scores = cross_val_score(estimator=grid_search,X=train_x,y=train_y,scoring="accuracy",cv=5)
print("CV accuray:%.3f +/- %.3f"%(np.mean(scores),np.std(scores)))
#CV accuray:0.908 +/- 0.045
通过SVM和决策树的嵌套交叉验证结果表明,SVM的模型性能要高于决策树模型的性能。