1、交叉验证
交叉验证:为了让被评估的模型更加准确可信。
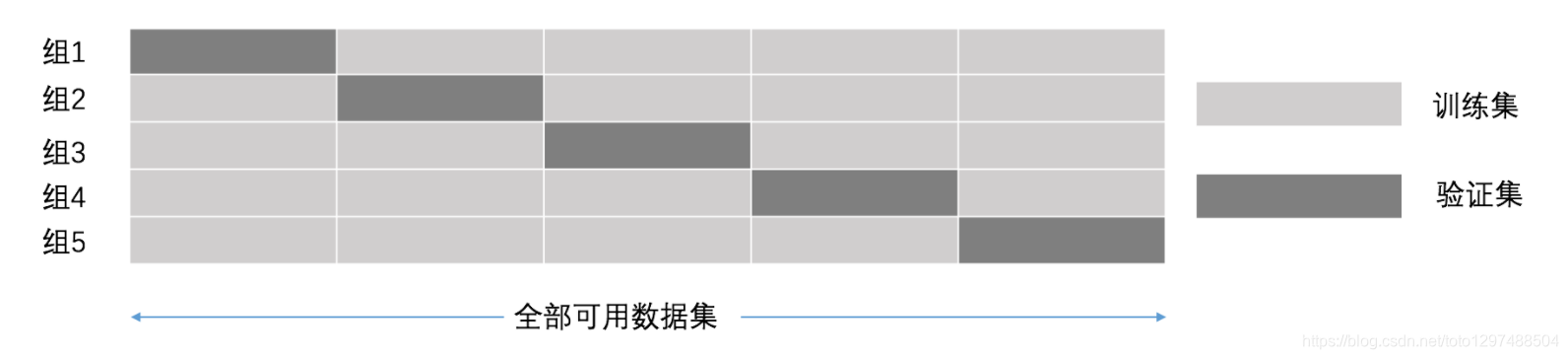
交叉验证:将拿到的数据,分为训练和验证集。以下图为例:将数据分成5份,其中一份作为验证集。然后经过5次(组)的测试,每次都更换不同的验证集。即得到5组模型的结果,取平均值作为最终结果。又称5折交叉验证。
2、超参数搜索-网格搜索
通常情况下,有很多参数是需要手动指定的(如k-近邻算法中的K值),这种叫超参数。但是手动过程繁杂,所以需要对模型预设几种超参数组合。每组超参数都采用交叉验证来进行评估。最后选出最优参数组合建立模型。

3、超参数搜索-网格搜索API
sklearn.model_selection.GridSearchCV
class sklearn.model_selection.GridSearchCV(estimator, param_grid, scoring=None, fit_params=None, n_jobs=None, iid=’warn’, refit=True, cv=’warn’, verbose=0, pre_dispatch=‘2*n_jobs’, error_score=’raise-deprecating’, return_train_score=’warn’)
用途:
对估计器的指定参数值进行详尽搜索
estimator:估计器对象,sklearn里面封装的模型(这被假定为实现SCIKIT学习估计器接口。)
param_grid:估计器参数(dict){
"n_neighbors":[1,3,5]},值为字典或者列表,字典里面的键代表estimator模型中的可以设置的参数,值是GridSearchCV要去遍历优化的具体值。
比如具体的GridSearchCV函数结构如下:
svr = GridSearchCV(SVR(), param_grid={
"kernel": ("linear", 'rbf'),"C": np.logspace(-3, 3, 7), "gamma": np.logspace(-3, 3, 7)})
第一个参数是建立的SVR模型(estimator);
第二个参数是SVR()模型中,允许的参数。kernel(核函数):linear(线性核)、rbf(径向基核);C(惩罚系数):设置范围为从1.e-03到1.e+03的等比数列,共7个数;gamma(核系数):同上。SVR()详细参数可见:https://blog.csdn.net/qq_24852439/article/details/85305317
scoring:模型评价方法,也是按照上面参数的方法,给定一个列表或者字典形式。评价方法可以参照sklearn里面的metric ( string, callable, list/tuple, dict or None, default: None)
fit_params: dict, optional 传递给FIT方法的参数。自0.19版本以来,Fista PARAMS作为一个构造函数参数在0.19版本中被弃用,将在0.21中删除。
n_jobs:并行运行的核数。默认值为1。-1的时候运行你所有的CPU核
pre_dispatch:int, or string, optional 控制并行执行期间分派的作业数量。减少这个数目可以避免在比CPU能够处理的更多任务被分配时避免内存消耗的爆炸。这个参数可以是:
没有,在这种情况下,所有的工作都立即被创造和产生。使用此操作轻量级和快速运行的作业,以避免由于按需生成作业而导致的延迟。
一个int,给出产生的总工作的确切数量。
一个字符串,将表达式作为NSJOB的函数,如“2×N-JOB”
iid : boolean, default=True 如果是真的,假设数据在褶皱上是相同分布的,损失最小的是每个样本的总损失,而不是整个褶皱的平均损失。
cv:指定几折交叉验证 (int, cross-validation generator or an iterable, optional),确定交叉验证拆分策略。CV的可能输入是:没有,使用默认的3倍交叉验证;整数:以指定的数量。
refit:boolean,or string,default=True 在整个数据集上使用最佳找到的参数重新估计。 对于多指标评价,这需要是一个字符串,使用记分器来寻找最佳的参数,用于重新估计估计器的末尾。重新编译的估计器在BestyRealSturix属性中可用,并且允许直接在GRIDSCACHCV实例上使用预测。此外,对于多度量评估,属性BestJoixxx,BestJoSeCype和BestHythPrimeSt*将仅在重新设置时可用,所有这些都将被确定为特定的记分器。
verbos:integer 控制冗长:越高,信息越多。
error_score : ‘raise’ (default) or numeric 如果在估计器拟合中出现错误,则将其赋值给分数。如果设置为“raise”,则会引发错误。如果给定数值,则FitFailedWarning被提升。此参数不影响重新配置步骤,它总是会引发错误。
return_train_score:boolean, optional
fit:输入训练数据
score:准确率
结果分析:
best_score_ : 在交叉验证中测试的最好结果
best_estimator_ : 最好的参数模型
cv_results_ : 每次交叉验证后的测试集准确率结果和训练集准确率结果。
打个赏呗,您的支持是我坚持写好博文的动力。
