网格搜索调优超参数
通过对不同超参数列表进行暴力穷举搜索,并计算评估每个组合对模型性能的影响,以获得参数的最优组合。
对SVM模型调优超参数:
import matplotlib.pyplot as plt
from sklearn.model_selection import GridSearchCV
from sklearn.svm import SVC
from sklearn.linear_model import LogisticRegression
from sklearn.preprocessing import StandardScaler
from sklearn.pipeline import Pipeline
import pandas as pd
import numpy as np
from sklearn.preprocessing import LabelEncoder
from sklearn.model_selection import train_test_split
'''
读取乳腺癌数据集
数据集前两列存储样本ID和诊断结果(M代表恶性,B代表良性)
3~32列包含了30个特征
'''
df = pd.read_csv('https://archive.ics.uci.edu/ml/machine-learning-databases'
+ '/breast-cancer-wisconsin/wdbc.data',
header=None)
X = df.loc[:, 2:].values
y = df.loc[:, 1].values
le =LabelEncoder()
# 将类标从字符串(M或B)变为整数的(0,1)
y = le.fit_transform(y)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=0)
'''
在流水线中集成标准化操作以及分类器
PipeLine对象采用元组的序列作为输入,每个元组第一个值为字符串,
可以通过字符串访问流水线的元素,第二个值为sklearn中的转换器或评估器
'''
pipe_svc = Pipeline([
('scl', StandardScaler()),
('clf', SVC(random_state=0))
])
param_range = [0.0001, 0.001, 0.01, 0.1, 1.0, 10.0, 100.0, 1000.0]
# 以字典或者字典列表的方式定义待调优的超参数
param_grid = [
{'clf__C': param_range,
'clf__kernel': ['linear']},
{'clf__C': param_range,
'clf__gamma': param_range,
'clf__kernel': ['rbf']},
]
gs = GridSearchCV(estimator=pipe_svc,
param_grid=param_grid,
scoring='accuracy',
cv=10)
gs.fit(X_train, y_train)
print(gs.best_score_)
'''
输出最佳k折交叉验证准确率:
0.9802197802197802
'''
print(gs.best_params_)
'''
最优的超参数信息:
{'clf__C': 10.0, 'clf__gamma': 0.01, 'clf__kernel': 'rbf'}
'''
clf = gs.best_estimator_
clf.fit(X_train, y_train)
print('Test accuracy: %.3f' % clf.score(X_test, y_test))
'''
Test accuracy: 0.982
'''随机搜索调优超参数
从抽样分布中抽取随机的参数组合。
from sklearn.svm import SVC
from sklearn.model_selection import RandomizedSearchCV
from sklearn.preprocessing import StandardScaler
from sklearn.pipeline import Pipeline
import pandas as pd
from sklearn.preprocessing import LabelEncoder
from sklearn.model_selection import train_test_split
'''
读取乳腺癌数据集
数据集前两列存储样本ID和诊断结果(M代表恶性,B代表良性)
3~32列包含了30个特征
'''
df = pd.read_csv('https://archive.ics.uci.edu/ml/machine-learning-databases'
+ '/breast-cancer-wisconsin/wdbc.data',
header=None)
X = df.loc[:, 2:].values
y = df.loc[:, 1].values
le =LabelEncoder()
# 将类标从字符串(M或B)变为整数的(0,1)
y = le.fit_transform(y)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=0)
'''
在流水线中集成标准化操作以及分类器
PipeLine对象采用元组的序列作为输入,每个元组第一个值为字符串,
可以通过字符串访问流水线的元素,第二个值为sklearn中的转换器或评估器
'''
pipe_svc = Pipeline([
('scl', StandardScaler()),
('clf', SVC(random_state=0))
])
param_range = [0.0001, 0.001, 0.01, 0.1, 1.0, 10.0, 100.0, 1000.0]
# 以字典的方式定义待调优的超参数
param_dist = {'clf__C': param_range,
'clf__kernel': ['linear', 'rbf'],
'clf__gamma': param_range}
rs = RandomizedSearchCV(estimator=pipe_svc,
param_distributions=param_dist,
cv=10)
rs.fit(X_train, y_train)
print(rs.best_score_)
'''
输出最佳k折交叉验证准确率:
0.9802197802197802
'''
print(rs.best_params_)
'''
最优的超参数信息:
{'clf__C': 10.0, 'clf__gamma': 0.01, 'clf__kernel': 'rbf'}
'''
clf = rs.best_estimator_
clf.fit(X_train, y_train)
print('Test accuracy: %.3f' % clf.score(X_test, y_test))
'''
Test accuracy: 0.982
'''嵌套交叉验证选择机器学习算法
结合网格搜索和交叉验证不仅可以对算法的超参数进行调优,而且还可以根据不同算法的表现来选择最适合的机器学习算法。根据研究:使用嵌套交叉验证,估计的真实误差与在测试集上的结果几乎一致。
在外围循环中,使用分层k折交叉验证将训练数据划分为训练快和测试块,训练块用于传入内部循环进行训练和超参数调优,测试块用于评估模型的最终表现。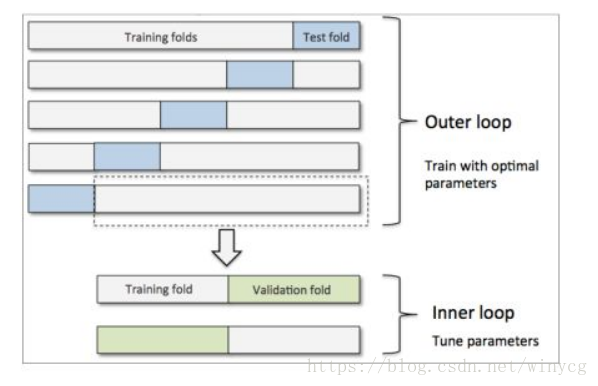
在如下的例子中,外围循环使用分层5折交叉验证,将训练数据划分为5组。每组的训练块传入网格搜索,之后通过网格搜索获得最优的模型。5组数据对应5个模型,之后使用对应的测试块测试准确率,并将5个模型的准确率结果求平均作为该算法的表现。
SVM分类器:
gs = GridSearchCV(estimator=pipe_svc,
param_grid=param_grid,
scoring='accuracy',
cv=10)
scores = cross_val_score(gs, X, y, scoring='accuracy', cv=5)
print(scores)
'''
[0.95652174 0.97391304 0.97345133 0.96460177 0.99115044]
'''
print('CV accuracy: %.3f +- %.3f' % (np.mean(scores), np.std(scores)))
'''
CV accuracy: 0.972 +- 0.012
'''决策树分类器(只考虑决策树的深度)
from sklearn.tree import DecisionTreeClassifier
gs = GridSearchCV(estimator=DecisionTreeClassifier(random_state=0),
param_grid=[{'max_depth': [1, 2, 3, 4, 5, 6, 7, None]}],
scoring='accuracy',
cv=10)
scores = cross_val_score(gs, X, y, scoring='accuracy', cv=5)
print(scores)
'''
[0.92173913 0.89565217 0.92920354 0.94690265 0.89380531]
'''
print('CV accuracy: %.3f +- %.3f' % (np.mean(scores), np.std(scores)))
'''
CV accuracy: 0.917 +- 0.020
'''从结果可以看出,SVM用于对此数据集的未知数据进行分类是一个更好的选择