1.实验目的
(1)运用GridSearchCV比较不同的模型、不同的参数对实验结果的影响。
(2)运用字典存储模型和参数
(3)实验所用数据集为sklearn自带的手写数字数据集
2.导入必要模块并读取数据
from sklearn import datasets
from sklearn import svm #支持向量机
from sklearn.ensemble import RandomForestClassifier #随机森林
from sklearn.linear_model import LogisticRegression #逻辑回归
from sklearn.naive_bayes import GaussianNB #先验为高斯分布的朴素贝叶斯
from sklearn.naive_bayes import MultinomialNB #先验为多项式分布的朴素贝叶斯
from sklearn.tree import DecisionTreeClassifier #决策树
digits = datasets.load_digits() #加载手写题数据集
3.构建模型-参数字典
#构建模型到参数的字典
model_params = {
'svm':{
'model':svm.SVC(gamma='auto'),
'params':{
'C':[1,10,20],
'kernel':['rbf','linear']
}
},
'random_forest':{
'model':RandomForestClassifier(),
'params':{
'n_estimators':[1,5,10]
}
},
'logistic_regression':{
'model':LogisticRegression(),
'params':{
'C':[1,5,10]
}
},
'naive_bayes_gaussian':{
'model':GaussianNB(),
'params':{}
},
'naive_bayes_multinomial':{
'model':MultinomialNB(),
'params':{}
},
'decision_tree':{
'model':DecisionTreeClassifier(),
'params':{
'criterion':['gini','entropy']
}
}
}
4.训练
from sklearn.model_selection import GridSearchCV #导入网格搜索与交叉验证模型
import pandas as pd
scores = []
for model_name, mp in model_params.items():
clf = GridSearchCV(mp['model'],mp['params'],cv=5,return_train_score=False) #实例化
clf.fit(digits.data,digits.target) #训练
scores.append({
'model':model_name,
'best_score':clf.best_score_,
'best_params':clf.best_params_
})
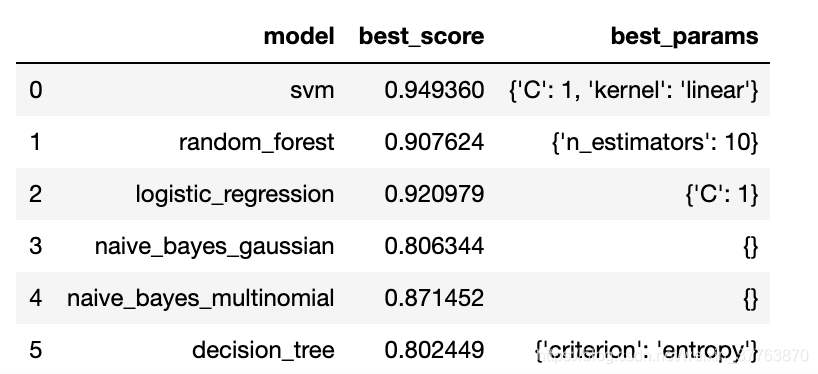
5.打印不同模型、不同参数对应的结果
df = pd.DataFrame(scores,columns=['model','best_score','best_params']) #把结果放入表格
df