版权声明:本文为博主原创文章,转载请在文章开头注明出处(作者+原文链接)。 https://blog.csdn.net/ChenVast/article/details/82018189
目录
简介
本次实战采用多个分类模型在一个二分类样本上进行测试,然后进行K折交叉验证,验证模型的性能,最后采用AUC对模型进行评估。
实战过程中会使用网格搜索对其中一个模型进行搜索最优超参数。
本次实战的IDE使用Jupyter Lab进行。
载入相关库
import numpy as np
import pandas as pd
from matplotlib.colors import ListedColormap
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
from sklearn.model_selection import cross_val_score
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
from sklearn.linear_model import Perceptron
from sklearn.metrics import accuracy_score
from sklearn.linear_model import LogisticRegression
from sklearn.svm import SVC
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.tree import export_graphviz
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import roc_curve, auc
from sklearn.metrics import roc_auc_score, accuracy_score
from scipy import interp
from sklearn.model_selection import StratifiedKFold
from sklearn.model_selection import GridSearchCV数据预处理
载入特征数据
data = pd.read_csv("./DataSets/features.dat",header=None)
data.head()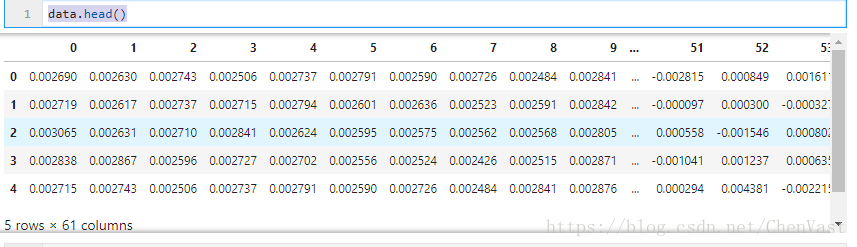
查看特征数据
data.shape(20536, 61)特征数据的维度为61
载入标签数据
labels = pd.read_csv("./DataSets/labels.dat",header=None)
labels.shape(20536, 1)标签数据维度为1,该数据为二分类数据,标签=0或1.
划分训练集和测试集
把数据分为70%的训练数据和30%的测试数据
X_train, X_test, y_train, y_test = train_test_split(
data, labels, test_size=0.3, random_state=0)归一化特征数据
对两个特征数据进行归一化
sc = StandardScaler()
sc.fit(X_train)
X_train_std = sc.transform(X_train)
X_test_std = sc.transform(X_test)开始模型构建
感知器
ppn = Perceptron(max_iter=50, eta0=0.1, random_state=0,n_jobs=-1)
ppn.fit(X_train_std, y_train.values.ravel())
y_pred = ppn.predict(X_test_std)
print('准确率: %.2f' % accuracy_score(y_test, y_pred))准确率: 0.83感知器的K折交叉验证(K=5)
scores = cross_val_score(estimator=ppn,
X=data.values,
y=labels.values.ravel(),
cv=5)
print('CV accuracy scores: %s' % scores)
print('CV accuracy: %.3f +/- %.3f' % (np.mean(scores), np.std(scores)))CV accuracy scores: [0.8105007 0.78504348 0.77982609 0.82226087 0.85003479]
CV accuracy: 0.810 +/- 0.026逻辑回归
lr = LogisticRegression(C=1000.0, random_state=0)
lr.fit(X_train_std, y_train.values.ravel())
y_pred2 = lr.predict(X_test_std)
print('准确率: %.2f' % accuracy_score(y_test, y_pred2))准确率: 0.84逻辑回归的K折交叉验证(K=5)
scores = cross_val_score(estimator=lr,
X=data.values,
y=labels.values.ravel(),
cv=5)
print('CV accuracy scores: %s' % scores)
print('CV accuracy: %.3f +/- %.3f' % (np.mean(scores), np.std(scores)))CV accuracy scores: [0.84840056 0.85530435 0.8413913 0.84382609 0.85212248]
CV accuracy: 0.848 +/- 0.005AUC模型评估
绘制DOC曲线和AUC面积
cv = StratifiedKFold(n_splits=3)
fig = plt.figure(figsize=(10, 5))
mean_tpr = 0.0
mean_fpr = np.linspace(0, 1, 100)
all_tpr = []
for i, (train, test) in enumerate(cv.split(data, labels)):
probas = lr.fit(data.values[train], labels.values[train].ravel()).predict_proba(data.values[test])
# 计算ROC曲线和曲线区域
fpr, tpr, thresholds = roc_curve(labels.values[test],
probas[:, 1])
mean_tpr += interp(mean_fpr, fpr, tpr)
mean_tpr[0] = 0.0
roc_auc = auc(fpr, tpr)
plt.plot(fpr,
tpr,
lw=1,
label='ROC fold %d (area = %0.2f)'
% (i+1, roc_auc))
plt.plot([0, 1],
[0, 1],
linestyle='--',
color=(0.6, 0.6, 0.6),
label='random guessing')
mean_tpr /= i+1
# mean_tpr[-1] = 1.0
mean_auc = auc(mean_fpr, mean_tpr)
plt.plot(mean_fpr, mean_tpr, 'k--',
label='mean ROC (area = %0.2f)' % mean_auc, lw=2)
plt.plot([0, 0, 1],
[0, 1, 1],
lw=2,
linestyle=':',
color='black',
label='perfect performance')
plt.xlabel('false positive rate')
plt.ylabel('true positive rate')
plt.title('Receiver Operator Characteristic')
plt.legend(loc="lower right")
plt.tight_layout()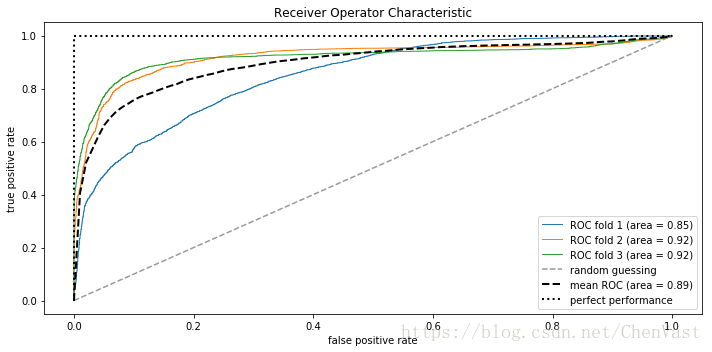
另一种方法,直接求AUC值
pipe_svc = lr.fit(X_train_std, y_train.values.ravel())
y_pred2 = lr.predict(X_test_std)
print('AUC: %.3f' % roc_auc_score(y_true=y_test, y_score=y_pred2))
print('Accuracy: %.3f' % accuracy_score(y_true=y_test, y_pred=y_pred2))支持向量机(SVM)
svm = SVC(kernel='linear', C=100.0,gamma=100.0, random_state=0)
svm.fit(X_train_std, y_train.values.ravel())
y_pred3 = svm.predict(X_test_std)
print('准确率: %.2f' % accuracy_score(y_test, y_pred3))准确率: 0.85K折交叉验证(K=3)
scores = cross_val_score(estimator=svm,
X=data.values,
y=labels.values.ravel(),
cv=3)
print('CV accuracy scores: %s' % scores)
print('CV accuracy: %.3f +/- %.3f' % (np.mean(scores), np.std(scores)))CV accuracy scores: [0.77227578 0.84733382 0.87611395]
CV accuracy: 0.832 +/- 0.044Kernel SVM(使用核方法的支持向量机)
ksvm = SVC(kernel='rbf', random_state=0, gamma=10.0, C=100.0)
ksvm.fit(X_train_std, y_train.values.ravel())
y_pred4 = ksvm.predict(X_test_std)
print('准确率: %.2f' % accuracy_score(y_test, y_pred4))准确率: 0.94由此可见使用核方法对于多维数据集的效果很明显
K折交叉验证(K=3)
scores = cross_val_score(estimator=ksvm,
X=data.values,
y=labels.values.ravel(),
cv=3,
n_jobs=-1)
print('CV accuracy scores: %s' % scores)
print('CV accuracy: %.3f +/- %.3f' % (np.mean(scores), np.std(scores)))CV accuracy scores: [0.90870581 0.94726077 0.94711468]
CV accuracy: 0.934 +/- 0.018
参数网格搜索
定义网格搜索需要搜索的参数
param = {"gamma":[0.01,0.1,1,10,100],
"C":[0.01,0.1,1,10,100]}定义网格搜索
grid_search = GridSearchCV(SVC(kernel='rbf',random_state=0),n_jobs=-1,param_grid=param,cv=3,refit='AUC',return_train_score=True)开始搜索
grid_search.fit(X_train_std, y_train.values.ravel())最好的分数
grid_search.best_score_0.9682782608695653网格搜索还是对应于使用常见的参数更为科学和可靠
显示网格
pd.DataFrame(grid_search.cv_results_).T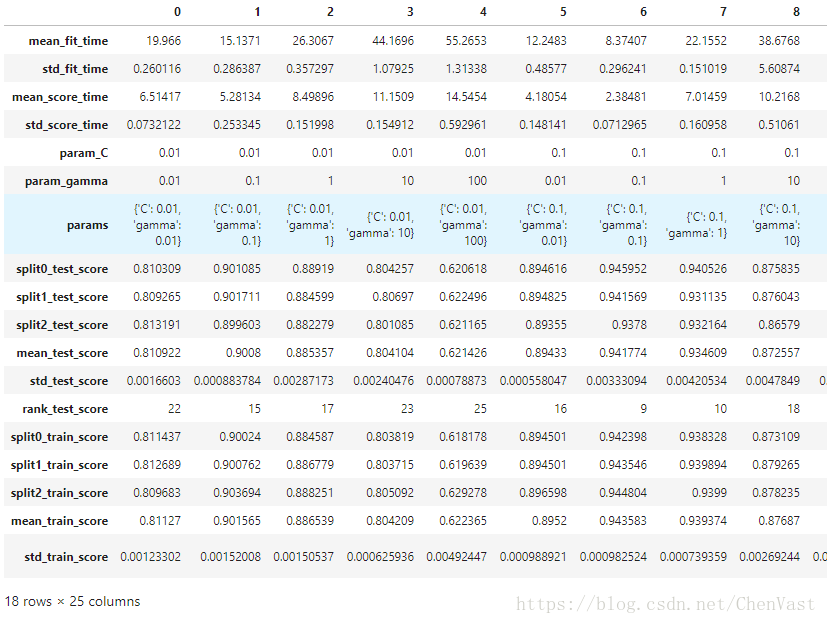
由于有两个参数,每个参数搜索5个值,所以一共有25个结果。
取出最好的模型进行得到预测分数
y_pred10 = grid_search.predict(X_test_std)
print('准确率: %.2f' % accuracy_score(y_test, y_pred10))准确率: 0.97使用三维点图绘制C和gamma和AUC之间的关系
C_val = []
for i in range(0,25):
C_val.append(grid_search.cv_results_["params"][i]["C"])
gamma_val = []
for i in range(0,25):
gamma_val.append(grid_search.cv_results_["params"][i]["gamma"])
AUC_score = grid_search.cv_results_["mean_test_score"]
fig = plt.figure()
ax = Axes3D(fig)
X = C_val
Y = gamma_val
Z = AUC_score
for x,y,z in zip(X,Y,Z):
#print(x,y,z)
#ax.scatter(x, y, z, cmap='rainbow')
ax.scatter(x, y, z, cmap='rainbow')
plt.title("Evaluation of figure")
ax.set_xlabel('Penalty parameter C of the error term')
#ax.set_xlim(0.001, 10)
ax.set_ylabel('gamma')
#ax.set_ylim(0.001, 10)
ax.set_zlabel('AUC')
ax.set_zlim(0, 1)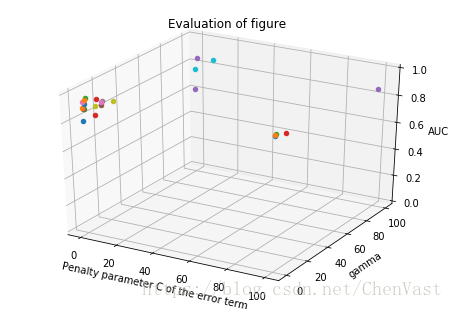
手动网格搜索(不建议)
使用for循环遍历参数
for gamma in [0.001,0.01,0.1,1,10,100]:
for C in [0.001,0.01,0.1,1,10,100]:
ksvm = SVC(kernel='rbf',gamma=gamma,C=C)
scores = cross_val_score(ksvm,X_train,y_train,cv=5)
score = scores.mean()
print("gamma / C / score:",gamma,C,score)决策树
tree = DecisionTreeClassifier(criterion='entropy', max_depth=10, random_state=0)
tree.fit(X_train_std, y_train.values.ravel())
y_pred5 = tree.predict(X_test_std)
print('准确率: %.2f' % accuracy_score(y_test, y_pred5))准确率: 0.97K折交叉验证
scores = cross_val_score(estimator=tree,
X=data.values,
y=labels.values.ravel(),
cv=3)
print('CV accuracy scores: %s' % scores)
print('CV accuracy: %.3f +/- %.3f' % (np.mean(scores), np.std(scores)))CV accuracy scores: [0.95427987 0.95193572 0.96128561]
CV accuracy: 0.956 +/- 0.004
随机森林
forest = RandomForestClassifier(criterion='entropy',
n_estimators=10,
random_state=1,
n_jobs=-1)
forest.fit(X_train_std, y_train.values.ravel())
y_pred6 = forest.predict(X_test_std)
print('准确率: %.2f' % accuracy_score(y_test, y_pred6))准确率: 0.98K折交叉验证
scores = cross_val_score(estimator=forest,
X=data.values,
y=labels.values.ravel(),
cv=3)
print('CV accuracy scores: %s' % scores)
print('CV accuracy: %.3f +/- %.3f' % (np.mean(scores), np.std(scores)))CV accuracy scores: [0.97180836 0.95821768 0.97399562]
CV accuracy: 0.968 +/- 0.007KNN
knn = KNeighborsClassifier(n_neighbors=5, p=2, metric='minkowski',n_jobs=-1)
knn.fit(X_train_std, y_train.values.ravel())
y_pred7 = knn.predict(X_test_std)
print('准确率: %.2f' % accuracy_score(y_test, y_pred7))准确率: 0.96K折交叉验证
scores = cross_val_score(estimator=knn,
X=data.values,
y=labels.values.ravel(),
cv=3)
print('CV accuracy scores: %s' % scores)
print('CV accuracy: %.3f +/- %.3f' % (np.mean(scores), np.std(scores)))CV accuracy scores: [0.87540169 0.89408327 0.93075237]
CV accuracy: 0.900 +/- 0.023
问题
标签数据集都加.values.ravel()
因为原来的数据集矩阵形状如下
labels.shape(20536, 1)模型方法使用数据集时,提示需要调整为(20536,),所以
labels.values.ravel().shape(20536,)调整该样式。
网格搜索计算成本
在本次实战中,网格搜索的计算成本为4核CPU全开,消耗18分钟。
大家可以先凭着经验,定义几个有意义的参数,再进行网格搜索,不然很浪费计算资源。
程序代码和数据集
程序代码和数据集存放在我的GitHub
项目地址:https://github.com/935048000/MachineLearningModelImplementation
有错误欢迎大家指正,一起进步。