交叉验证
1.定义:将拿到的训练集,分为训练集和验证集
几折交叉验证(训练集被分为几部分)
2.分割方式:
训练集:训练集+验证集
测试集:测试集

3.为什么需要交叉验证
为了让被评估的模型更加准确可信
注意:交叉验证不能提高模型的准确率
网格搜索
超参数:sklearn中,需要手动指定的参数,叫做超参数
网格搜索就是把这些超参数的值,通过字典的形式传递进去,然后进行选择最优值。
GridSearchCV(暴力搜索选出最优参数)
class sklearn.model_selection.GridSearchCV(estimator, param_grid, *,scoring=None, n_jobs=None, refit=True, cv=None, verbose=0, pre_dispatch='2*n_jobs', error_score=nan, return_train_score=False)
参数:
●estimator – 选择了哪个训练模型
●param_grid – 需要最优化的参数的取值,值为字典或者列表,例如:{“n_neighbors”:[1,3,5]}
●scoring = None :模型评价标准,默认为None,这时需要使用score函数;或者如scoring = ‘roc_auc’,根据所选模型不同,评价准则不同,字符串(函数名),或是可调用对象,需要其函数签名,形如:scorer(estimator,X,y);如果是None,则使用estimator的误差估计函数。
●cv – 几折交叉验证(训练集被分为几部分)交叉验证参数,默认None,使用三折交叉验证。指定fold数量,默认为3,也可以是yield训练/测试数据的生成器
●n_jobs:
1作用:确定计算cpu内核的使用数量
2 用法:为一个整数,整数是几运算过程中就使用cpu的几个内核
3 默认n_jobs = 1,表示使用计算机的一个核进行处理;
4 如果计算机的4核,可以让n_job = 2/3/4,使用2/3/4个核同时处理,提高运行效率
5 n_jobs = -1,表示计算机有几个核就使用几个核进行运算
●verbose:日志冗长度,int:冗长度,0:不输出训练过程,1:偶尔输出,>1:对每个子模型都输出。
return_train_score=’warn’
如果“False”,cv_results_属性将不包括训练分数
属性说明:
■best_score_:在交叉验证中验证的最好结果
■best_estimator_:最好的参数模型 (.best_estimator_).score(x_test,y_test))
■best_params_:最好的参数
■estimator.cv_results_: dict of numpy (masked) ndarrays,每次交叉验证后的验证集准确率结果和训练集准确率结果
例子1
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split,GridSearchCV
from sklearn.preprocessing import StandardScaler
from sklearn.neighbors import KNeighborsClassifier
# 1、获取数据集
iris = load_iris()
# 2、数据基本处理 -- 划分数据集
x_train, x_test, y_train, y_test = train_test_split(iris.data, iris.target, random_state=22)
# 3、特征工程:标准化
# 实例化一个转换器类
transfer = StandardScaler()
# 调用fit_transform
x_train = transfer.fit_transform(x_train)
x_test = transfer.transform(x_test)
# 4、KNN预估器流程
# 4.1 实例化预估器类
estimator = KNeighborsClassifier()
# 4.2 模型选择与调优——网格搜索和交叉验证
# 准备要调的超参数
param_dict = {
"n_neighbors": [1, 3, 5]}
estimator = GridSearchCV(estimator, param_grid=param_dict, cv=3)
#3个超参数,经过3折交叉验证,共计算了9次(3*3)
# 4.3 fit数据进行训练
estimator.fit(x_train, y_train)
# 5、评估模型效果
# 方法a:比对预测结果和真实值
y_predict = estimator.predict(x_test)
print("比对预测结果和真实值:\n", y_predict == y_test)
# 方法b:直接计算准确率
score = estimator.score(x_test, y_test)
print("直接计算准确率:\n", score)
print("在交叉验证中验证的最好结果:\n", estimator.best_score_)
print("最好的参数模型:\n", estimator.best_estimator_)
print("每次交叉验证后的准确率结果:\n", estimator.cv_results_)
例子2
import numpy as np
from sklearn import datasets
# 得到原始数据
digits = datasets.load_digits()
X = digits.data
y = digits.target
# 根据自己编写的函数,对原始数据进行切分
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.2, random_state = 666)
# 1)定义搜索的参数范围
param_grid = [
{
'weights':['uniform'],
'n_neighbors':[i for i in range(1, 11)]
},
{
'weights':['distance'],
'n_neighbors':[i for i in range(1, 11)],
'p':[i for i in range(1, 6)]
}
]
# 2)创建一个需要进行网格搜索的机器学习算法对象
from sklearn.neighbors import KNeighborsClassifier
knn_clf = KNeighborsClassifier()
# 3)实例化scikit-learn中的网格搜索对象
from sklearn.model_selection import GridSearchCV
# 创GridSearchCV对应的实例对象,一般传入4个参数:
grid_search = GridSearchCV(knn_clf, param_grid, n_jobs = -1, verbose = 2)
# 4)对网格搜索的实例对象fit
grid_search.fit(X_train, y_train)
# 5)查看结果
# 查看网格搜索得到的最佳的分类器对应的参数(为最佳分类器的所有参数)
grid_search.best_estimator_
# 查看准确度
# 此处得到的准确度(0.9853963838664812)并没有之前(n_neighbors = 3时)得到的准确度高,因为评判标准改变了
grid_search.best_score_
# 查看之前定义的网格搜索参数中最优的结果
grid_search.best_params_
# 获取最佳分类器模型
knn_clf = grid_search.best_estimator_
# 6)使用最佳分类器进行预测
knn_clf.score(X_test, y_test)
cross_val_score(选出最优评分的模型)
sklearn.model_selection.cross_val_score(estimator, X, y=None, groups=None, scoring=None, cv=’warn’, n_jobs=None, verbose=0, fit_params=None, pre_dispatch=‘2*n_jobs’, error_score=’raise-deprecating’)
from sklearn.model_selection import cross_val_score
参数:
estimator: 需要使用交叉验证的算法
X: 输入样本数据
y: 样本标签
groups: 将数据集分割为训练/测试集时使用的样本的组标签(一般用不到)
scoring: 交叉验证最重要的就是他的验证方式,选择不同的评价方法,会产生不同的评价结果。
cv: 交叉验证折数或可迭代的次数
n_jobs: 同时工作的cpu个数(-1代表全部)
verbose: 详细程度
fit_params: 传递给估计器(验证算法)的拟合方法的参数
pre_dispatch: 控制并行执行期间调度的作业数量。减少这个数量对于避免在CPU发送更多作业时CPU内存消耗的扩大是有用的。该参数可以是:
•没有,在这种情况下,所有的工作立即创建并产生。将其用于轻量级和快速运行的作业,以避免由于按需产生作业而导致延迟
•一个int,给出所产生的总工作的确切数量
•一个字符串,给出一个表达式作为n_jobs的函数,如’2 * n_jobs
error_score: 如果在估计器拟合中发生错误,要分配给该分数的值(一般不需要指定)
from sklearn import datasets
from sklearn.model_selection import train_test_split,cross_val_score
from sklearn.neighbors import KNeighborsClassifier
import matplotlib.pyplot as plt
iris = datasets.load_iris()
X = iris.data
y = iris.target
x_train,x_test,y_train,y_test = train_test_split(X,y,test_size=1/3,random_state=3)
k_range = range(1,31)
cv_scores = [] #用来放每个模型的结果值
for n in k_range:
knn = KNeighborsClassifier(n) #knn模型,这里一个超参数可以做预测,当多个超参数时需要使用另一种方法GridSearchCV
scores = cross_val_score(knn,x_train,y_train,cv=10,scoring='accuracy') #cv:选择每次测试折数 accuracy:评价指标是准确度,可以省略使用默认值。
print(scores)
cv_scores.append(scores.mean())
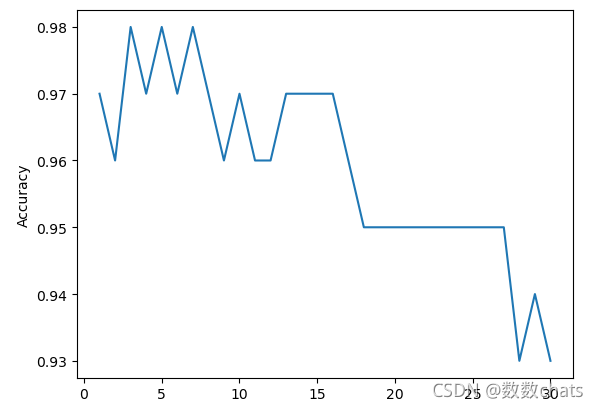
plt.plot(k_range,cv_scores)
plt.xlabel('K')
plt.ylabel('Accuracy') #通过图像选择最好的参数
plt.show()
best_knn = KNeighborsClassifier(n_neighbors=3) # 选择最优的K=3传入模型
best_knn.fit(x_train,y_train) #训练模型
print(best_knn.score(x_test,y_test))
小结
GridSearchCV :
除了自行完成叉验证外,还返回了最优的超参数及对应的最优模型
所以相对于cross_val_score来说,GridSearchCV在使用上更为方便;但是对于细节理解上,手动实现循环调用cross_val_score会更好些。
cross_val_score :
一般用于获取每折的交叉验证的得分,然后根据这个得分为模型选择合适的超参数,通常需要编写循环手动完成交叉验证过程。