语言模型
语言模型旨在为语句的联合概率函数P(w1,…,wT)建模, 其中wi表示句子中的第i个词。语言模型的目标是,希望模型对有意义的句子赋予大概率,对没意义的句子赋予小概率。 这样的模型可以应用于很多领域,如机器翻译、语音识别、信息检索、词性标注、手写识别等,它们都希望能得到一个连续序列的概率。
对语言模型的目标概率P(w1,…,wT),如果假设文本中每个词都是相互独立的,则整句话的联合概率可以表示为其中所有词语条件概率的乘积,即:
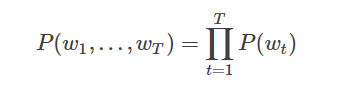
然而我们知道语句中的每个词出现的概率都与其前面的词紧密相关, 所以实际上通常用条件概率表示语言模型:
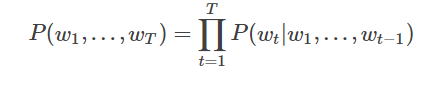
N-gram neural model
n-gram是一种重要的文本表示方法,表示一个文本中连续的n个项。基于具体的应用场景,每一项可以是一个字母、单词或者音节。 n-gram模型也是统计语言模型中的一种重要方法,用n-gram训练语言模型时,一般用每个n-gram的历史n-1个词语组成的内容来预测第n个词。
我们在上文中已经讲到用条件概率建模语言模型,即一句话中第t个词的概率和该句话的前t−1个词相关。可实际上越远的词语其实对该词的影响越小,那么如果考虑一个n-gram, 每个词都只受其前面n-1个词的影响,则有:
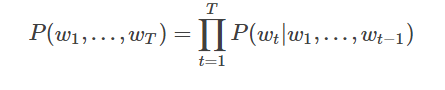
给定一些真实语料,这些语料中都是有意义的句子,N-gram模型的优化目标则是最大化目标函数:
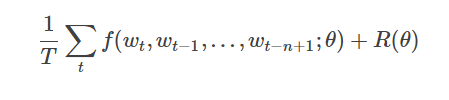
其中f(wt,wt−1,…,wt−n+1)表示根据历史n-1个词得到当前词wt的条件概率,R(θ)表示参数正则项

图2展示了N-gram神经网络模型,从下往上看,该模型分为以下几个部分: - 对于每个样本,模型输入wt−n+1,…wt−1, 输出句子第t个词在字典中|V|个词上的概率分布。
每个输入词wt−n+1,…wt−1首先通过映射矩阵映射到词向量C(wt−n+1),…C(wt−1)。
- 然后所有词语的词向量拼接成一个大向量,并经过一个非线性映射得到历史词语的隐层表示:
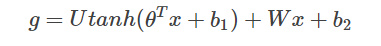
其中,x为所有词语的词向量拼接成的大向量,表示文本历史特征;θ、U、b1、b2和W分别为词向量层到隐层连接的参数。g表示未经归一化的所有输出单词概率,gi表示未经归一化的字典中第i个单词的输出概率。
- 根据softmax的定义,通过归一化gi, 生成目标词wt的概率为:
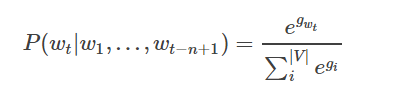
- 整个网络的损失值(cost)为多类分类交叉熵,用公式表示为
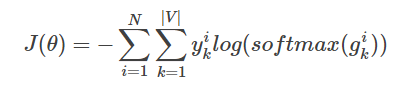
其中yik表示第i个样本第k类的真实标签(0或1),softmax(gik)表示第i个样本第k类softmax输出的概率

N-Gram是基于一个假设:第n个词出现与前n-1个词相关,而与其他任何词不相关。(这也是隐马尔可夫当中的假设。)整个句子出现的概率就等于各个词出现的概率乘积。各个词的概率可以通过语料中统计计算得到。假设句子T是有词序列w1,w2,w3…wn组成,用公式表示N-Gram语言模型如下:
P(T)=P(w1)*p(w2)*p(w3)***p(wn)=p(w1)*p(w2|w1)*p(w3|w1w2)***p(wn|w1w2w3…)
一般常用的N-Gram模型是Bi-Gram和Tri-Gram。分别用公式表示如下:
Bi-Gram: P(T)=p(w1|begin)*p(w2|w1)*p(w3|w2)***p(wn|wn-1)
Tri-Gram: P(T)=p(w1|begin1,begin2)*p(w2|w1,begin1)*p(w3|w2w1)***p(wn|wn-1,wn-2)
注意上面概率的计算方法:P(w1|begin)=以w1为开头的所有句子/句子总数;p(w2|w1)=w1,w2同时出现的次数/w1出现的次数。以此类推。(这里需要进行平滑)
二、N-Gram的应用
根据上面的分析,N-Gram(有时也称为N元模型)是自然语言处理中一个非常重要的概念,通常在NLP中,它主要有两个重要应用场景:
(1)、人们基于一定的语料库,可以利用N-Gram来预计或者评估一个句子是否合理。
(2)、另外一方面,N-Gram的另外一个作用是用来评估两个字符串之间的差异程度。这是模糊匹配中常用的一种手段。
1、N-gram在两个字符串的模糊匹配中的应用
首先需要介绍一个比较重要的概念:N-Gram距离。
(1)N-gram距离
它是表示,两个字符串s,t分别利用N-Gram语言模型来表示时,则对应N-gram子串中公共部分的长度就称之为N-Gram距离。例如:假设有字符串s,那么按照N-Gram方法得到N个分词组成的子字符串,其中相同的子字符串个数作为N-Gram距离计算的方式。具体如下所示:
字符串:s=“ABC”,对字符串进行分词,考虑字符串首尾的字符begin和end,得到begin,A,B,C,end。这里采用二元语言模型,则有:(begin,A)、(A,B)、(B,C)、(C,end)。
字符串:t=“AB”,对字符串进行分词,考虑字符串首尾的字符begin和end,得到begin,A,B,end。这里采用二元语言模型,则有:(begin,A)、(A,B)、(B,end)。
此时,若求字符串t与字符串s之间的距离可以用M-(N-Gram距离)=0。
然而,上面的N—gram距离表示的并不是很合理,他并没有考虑两个字符串的长度,所以在此基础上,有人提出非重复的N-gram距离,公式如下所示:
上面的字符串距离重新计算为:
4+3-2*3=1
2、N-Gram在判断句子有效性上的应用
假设有一个字符串s=“ABC”,则对应的BI-Gram的结果如下:(begin,A)、(A,B)、(B,C)、(C,end)。则对应的出现字符串s的概率为:
P(ABC)=P(A|begin)*P(B|A)*P(C|B)*P(end|C)。
3、N-Gram在特征工程中的应用
在处理文本特征的时候,通常一个关键词作为一个特征。这也许在一些场景下可能不够,需要进一步提取更多的特征,这个时候可以考虑N-Gram,思路如下:
以Bi-Gram为例,在原始文本中,以每个关键词作为一个特征,通过将关键词两两组合,得到一个Bi-Gram组合,再根据N-Gram语言模型,计算各个Bi-Gram组合的概率,作为新的特征。
数据平滑:
N-gram的N NN越大,模型 Perplexity 越小,表示模型效果越好。这在直观意义上是说得通的,毕竟依赖的词越多,我们获得的信息量越多,对未来的预测就越准确。然而,语言是有极强的创造性的(Creative),当N NN变大时,更容易出现这样的状况:某些n-gram从未出现过,这就是稀疏问题。
n-gram最大的问题就是稀疏问题(Sparsity)。例如,在bi-gram中,若词库中有20k个词,那么两两组合(C220k C_{20k}^2C 20k2)就有近2亿个组合。其中的很多组合在语料库中都没有出现,根据极大似然估计得到的组合概率将会是0,从而整个句子的概率就会为0。最后的结果是,我们的模型只能计算零星的几个句子的概率,而大部分的句子算得的概率是0,这显然是不合理的。
因此,我们要进行数据平滑(data Smoothing),数据平滑的目的有两个:一个是使所有的N-gram概率之和为1,使所有的n-gram概率都不为0。它的本质,是重新分配整个概率空间,使已经出现过的n-gram的概率降低,补充给未曾出现过的n-gram。
N-gram的进化版:NNLM
NNLM 即 Neural Network based Language Model,由Bengio在2003年提出,它是一个很简单的模型,由四层组成,输入层、嵌入层、隐层和输出层。模型接收的输入是长度为n nn的词序列,输出是下一个词的类别。首先,输入是单词序列的index序列,例如单词 I 在字典(大小为∣V∣ |V|∣V∣)中的index是10,单词 am 的 index 是23, Bengio 的 index 是65,则句子“I am Bengio”的index序列就是 10, 23, 65。嵌入层(Embedding)是一个大小为∣V∣×K |V|\times K∣V∣×K的矩阵,从中取出第10、23、65行向量拼成3×K 3\times K3×K的矩阵就是Embedding层的输出了。隐层接受拼接后的Embedding层输出作为输入,以tanh为激活函数,最后送入带softmax的输出层,输出概率。
NNLM最大的缺点就是参数多,训练慢。另外,NNLM要求输入是定长n nn,定长输入这一点本身就很不灵活,同时不能利用完整的历史信息。

Word2Vec
Word2Vec解决的问题已经和上面讲到的N-gram、NNLM等不一样了,它要做的事情是:学习一个从高维稀疏离散向量到低维稠密连续向量的映射。该映射的特点是,近义词向量的欧氏距离比较小,词向量之间的加减法有实际物理意义。Word2Vec由两部分组成:CBoW和Skip-Gram。其中CBoW的结构很简单,在NNLM的基础上去掉隐层,Embedding层直接连接到Softmax,CBoW的输入是某个Word的上下文(例如前两个词和后两个词),Softmax的输出是关于当前词的某个概率,即CBoW是从上下文到当前词的某种映射或者预测。Skip-Gram则是反过来,从当前词预测上下文,至于为什么叫Skip-Gram这个名字,原因是在处理过程中会对词做采样。
Continuous Bag-of-Words model(CBOW)
CBOW模型通过一个词的上下文(各N个词)预测当前词。当N=2时,模型如下图所示:

具体来说,不考虑上下文的词语输入顺序,CBOW是用上下文词语的词向量的均值来预测当前词。即:
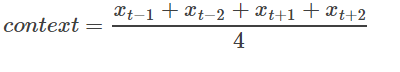
其中xt为第t个词的词向量,分类分数(score)向量 z=U∗context,最终的分类y采用softmax,损失函数采用多类分类交叉熵。
Skip-gram model
CBOW的好处是对上下文词语的分布在词向量上进行了平滑,去掉了噪声,因此在小数据集上很有效。而Skip-gram的方法中,用一个词预测其上下文,得到了当前词上下文的很多样本,因此可用于更大的数据集。

如上图所示,Skip-gram模型的具体做法是,将一个词的词向量映射到2n个词的词向量(2n表示当前输入词的前后各n个词),然后分别通过softmax得到这2n个词的分类损失值之和。