版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/u013555719/article/details/82144833
5.2自然语言处理
觉得有用的话,欢迎一起讨论相互学习~Follow Me
2.1词汇表征 Word representation
- 原先都是使用词汇表来表示词汇,并且使用1-hot编码的方式来表示词汇表中的词汇。
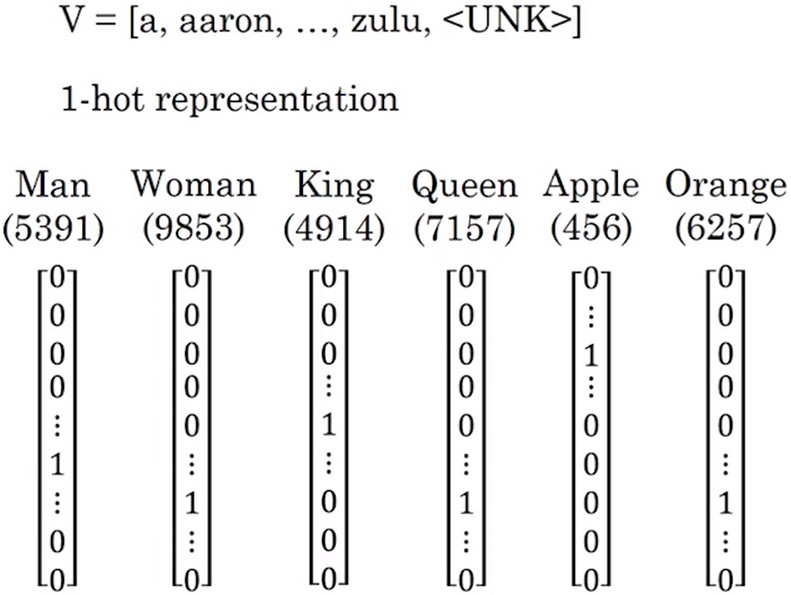
- 这种表示方法最大的缺点是 它把每个词孤立起来,这样使得算法对相关词的泛化能力不强
- 例如:对于已知句子“I want a glass of orange _ ” 很可能猜出下一个词是”juice”.
- 如果模型已知读过了这个句子但是当看见句子”I want a glass of apple _ “,算法也不能猜出下一个词汇是”juice”,因为算法本身并不知道“orange”和“apple”之间的关系。也许比起苹果,橙子与其他单词之间的距离更近。即算法并不能从“orange juice”是一个很常见的短语而推导出“apple juice”也是一个常见的短语。
- 这是因为任意两个用“one-hot”编码表示的单词的内积都是0。
特征表示:词嵌入 (Featurized representation: word embedding)
- 使用特征化的方法来表示每个词,假如使用性别来作为一个特征,用以表示这些词汇和 性别 之间的关系。
| Man | Woman | King | Queen | Apple | Orange |
|---|---|---|---|---|---|
| Gender | -1 | 1 | -0.95 | 0.97 | 0.00 |
* 当然也可以使用这种方法表示这些词汇和 高贵 之间的关系。
| Man | Woman | King | Queen | Apple | Orange |
|---|---|---|---|---|---|
| Royal | 0.01 | 0.02 | 0.93 | 0.95 | -0.01 |
* 使用各种特征对词汇表中的单词进行表示
| Man | Woman | King | Queen | Apple | Orange |
|---|---|---|---|---|---|
| Gender | -1 | 1 | -0.95 | 0.97 | 0.00 |
| Royal | 0.01 | 0.02 | 0.93 | 0.95 | -0.01 |
| Age | 0.03 | 0.02 | 0.7 | 0.69 | 0.03 |
| Food | 0.09 | 0.01 | 0.02 | 0.01 | 0.95 |
* 假设为了表示出词汇表中的单词,使用300个特征进行描述,则词汇表中的每个单词都被表示为一个300维的向量。此时使用e_NO.表示特定的单词,例如Man表示为
,Woman表示为
,King表示为
* 对于词嵌入的表示形式通过大量不同的特征来表示词汇,在填词处理时,会更容易通过Orange juice而联想到 Apple juice.
可视化词向量 (Visualizing word embedding)
Maaten L V D, Hinton G. Visualizing Data using t-SNE[J]. Journal of Machine Learning Research, 2008, 9(2605):2579-2605.
- 对于词向量的可视化,是将300维的特征映射到一个2维空间中–t-SNE算法

2.2使用词嵌入 Using word embeddings
- 继续使用实体命名识别(named entity recognition)的例子,示例:”Sally Johnson is an orange farmer”Sally Johnson 是一个种橙子的农民。对于Sally Johnson,我们能很快识别出这是一个人名,这是因为看到了”orange farmer”这个词,告诉我们Sally Johnson是一个农民。
- 使用词嵌入的方式,很快能够识别出橙子和苹果是同类事物。在句子“Sally Johnson is an orange farmer”中识别出Sally Johnson是一个人名后,在句子“Robert Lin is an apple farmer”中也可以很容易的识别出Robert Lin是一个人名。
- 词嵌入文本识别的方法基于的是一个巨大的文本库,只有使用巨量的文本作为训练集的基础上,系统才会真正的有效。一个NLP系统中,使用的文本数量达到了1亿甚至是100亿。
- 在你的识别系统中,也许训练集只有100K的训练数据,但是可以使用迁移学习的方法,从大量无标签的文本中学习到大量语言知识。
将迁移学习运用到词嵌入 (Transfer learning and word embeddings)
- 先从一个非常大的文本集中学习词嵌入,或者从网上下载预训练好的词嵌入模型。
- 使用词嵌入模型,将其迁移到自己的新的只有少量标注的训练集的任务中。
- 优化模型:持续使用新的数据来微调自身的词嵌入模型。
- 词嵌入技术在自身的标注训练集相对较少时优势最为明显。在 实体命名识别(named entity recognition),文本摘要(text summarization),文本解析(co-reference resolution),指代消解(parsing)中应用最为广泛 在 语言模型(language modeling), 机器翻译(Machine translation)中应用较少 因为这些任务中,你有大量的数据而不一定需要使用到词嵌入技术。
词嵌入与人脸编码(word embeddings and face encoding)
Taigman Y, Yang M, Ranzato M, et al. DeepFace: Closing the Gap to Human-Level Performance in Face Verification[C]// IEEE Conference on Computer Vision and Pattern Recognition. IEEE Computer Society, 2014:1701-1708.
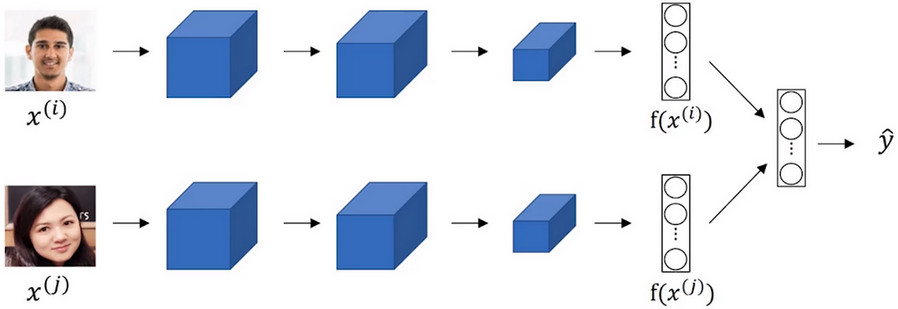
- 词嵌入技术与人脸编码技术之间有奇妙的关系,在人脸编码任务中,通过卷积神经网路将两张人脸图片进行编码成为两个128维的数据向量,然后经过比较判断两张图片是否来自于同一张人脸。
- 对于人脸识别问题,无论这张图片原先是否认识过,经过卷积神经网络处理后,都会得到一个向量表征。
- 对于词嵌入问题,则是有一个固定的词汇表,对于词汇表中的每个单词学习一个固定的词嵌入表示方法。而对于没有出现在词汇表中的单词,视其为UNK(unknowed word)