目录
一、概念
线性回归(Linear Regression)是一种通过属性的线性组合来进行预测的线性模型,其目的是找到一条直线或者一个平面或者更高维的超平面,使得预测值与真实值之间的误差最小化。
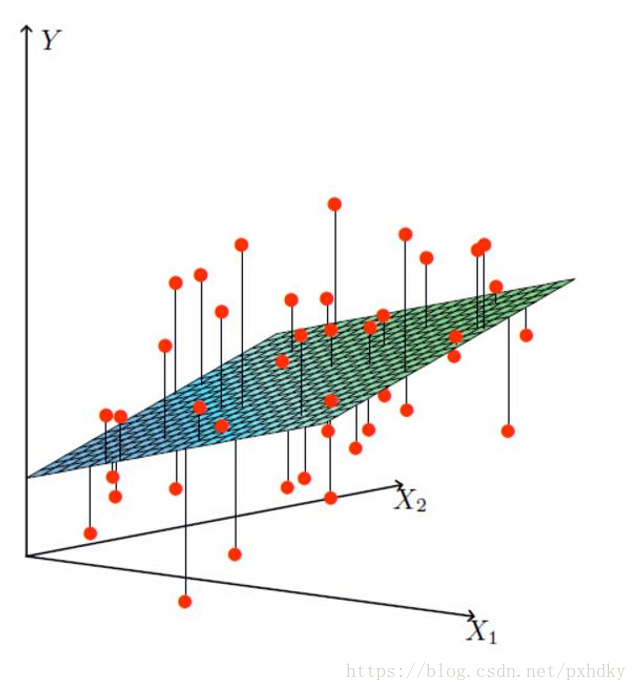
二、特点
- 优点:结果具有很好的可解释性(w直观表达了各属性在预测中的重要性),计算熵不复杂。
- 缺点:对非线性数据拟合不好
- 使用数据类型:数值型和标称型数据
二、原理与推导
1. 给定数据集,其中
,
(线性回归的输出空间是整个实数空间)。
是样本数,
是属性维度。
线性回归试图学得:
(1),使得
。
为便于讨论,使,其中
。此时,
就成为了
,
就成为了
,期望学得的函数为
。
2. 预测值和真实值之间都肯定存在差异,对于每个样本:
(2)
假设误差是独立同分布的,并且服从高斯分布。即:
(3)
将(2)代入(3)中,得到在已知参数和数据
的情况下,预测值为
的条件概率:
(4)
3. 将(4)连乘得到在已知参数和数据
的情况下,预测值为
的条件概率,这个条件概率在数值上等于,likelihood(w|x,y),也就是在已知现有数据的条件下,w是真正参数的概率,即似然函数(5):
(5)
为什么要引入似然函数?为了根据样本估计参数值。
由于乘法难解,通过对数可以将乘法转换为加法,简化计算(为什么要对似然函数进行log变换?)。
对数似然函数: (6)
得到目标函数: (7)
似然函数表示样本成为真实的概率,似然函数越大越好,也就是目标函数越小越好(为什么要让目标函数越小越好?)。
4. 目标函数是凸函数,只要找到一阶导数为0的位置,就找到了最优解。
因此求偏导: (8)
5. 令偏导等于0: (9)
得: (10)
情况一:可逆,唯一解。令公式(10)为零可得最优解为:
(11)
学得的线性回归模型为:
(12)
情况二:不可逆,可能有多个解。选择哪一个解作为输出,将有学习算法的偏好决定,常见的做法是引入正则化。
三、算法描述
1. 从数据集D出发,构建输入矩阵X和输出向量y。
2. 计算伪逆(pseudo-inverse)。
3. 返回,学得的线性回归模型为
。