RetinaNet 论文地址:https://arxiv.org/abs/1708.02002
这边只是简单记录一下自己关注的,建议看别人已经写好的博客。
RetinaNet网络框架
图3
- 单级RetinaNet网络架构在前瞻ResNet架构[16](a)之上使用特征金字塔网络(FPN)[20]主干来生成一个丰富的、多尺度的卷积特征金字塔(b)。
- 在这个主干上,RetinaNet附加两个子网,一个用于分类锚箱(c),一个用于从锚箱回归到ground-truth boxs(d)。
- 网络设计有意地简单,这使得这项工作能够专注于一种新颖的focal loss 损失函数,消除了我们的一级探测器和最先进的两级探测器之间的精度差距,如FPN[20]的Faster R-CNN在更快的速度运行时。

2.1 残差网络ResNet
论文地址:https://arxiv.org/abs/1512.03385
相关博客:残差神经网络(ResNet) - 知乎
以下仅仅是部分笔记,具体看原博客吧。
网络的深度:越深的网络提取的特征越抽象,越具有语义信息。
为什么不能简单地增加网络层数?
- 如果简单地增加深度,会导致梯度弥散或梯度爆炸。(解决:对于该问题的解决方法是正则化初始化和中间的正则化层(Batch Normalization),这样的话可以训练几十层的网络。)
- 新的问题:是退化问题,网络层数增加,但是在训练集上的准确率却饱和甚至下降了。这个不能解释为overfitting,因为overfit应该表现为在训练集上表现更好才对。
- 作者推断退化问题可能是因为深层的网络并不是那么好训练,也就是求解器很难去利用多层网络拟合同等函数。例如:导致这个原因就是虽然56层网络的解空间包含了20层网络的解空间,但是我们在训练网络用的是随机梯度下降策略,往往解到的不是全局最优解,而是局部的最优解,显而易见56层网络的解空间更加的复杂,所以导致使用随机梯度下降算法无法解到最优解。
怎么解决退化问题?
一个通俗的理解:
F是求和前网络映射,H是从输入到求和后的网络映射。比如把5映射到5.1,那么引入残差前是F’(5)=5.1,引入残差后是H(5)=5.1, H(5)=F(5)+5, F(5)=0.1。这里的F’和F都表示网络参数映射,引入残差后的映射对输出的变化更敏感。比如s输出从5.1变到5.2,映射F’的输出增加了1/51=2%,而对于残差结构输出从5.1到5.2,映射F是从0.1到0.2,增加了100%。明显后者输出变化对权重的调整作用更大,所以效果更好。残差的思想都是去掉相同的主体部分,从而突出微小的变化,看到残差网络我第一反应就是差分放大器…
这种残差学习结构可以通过前向神经网络+shortcut连接实现,如结构图所示。而且shortcut连接相当于简单执行了同等映射,不会产生额外的参数,也不会增加计算复杂度。 而且,整个网络可以依旧通过端到端的反向传播训练。
残差指的是什么?
其中ResNet提出了两种mapping:一种是identity mapping,指的就是图1中”弯弯的曲线”,另一种residual mapping,指的就是除了”弯弯的曲线“那部分,所以最后的输出是 y=F(x)+x
identity mapping顾名思义,就是指本身,也就是公式中的x,而residual mapping指的是“差”,也就是y−x,所以残差指的就是F(x)部分。

ResNet结构
它使用了一种连接方式叫做“shortcut connection”,顾名思义,shortcut就是“抄近道”的意思,看下图我们就能大致理解:
我们可以看到一个“弯弯的弧线“这个就是所谓的”shortcut connection“,也是文中提到identity mapping,这张图也诠释了ResNet的真谛,当然大家可以放心,真正在使用的ResNet模块并不是这么单一,文章中就提出了两种方式:
这里给出常见的两个残差单元/模块样式:

这两种结构分别针对ResNet34(左图)和ResNet50/101/152(右图),一般称整个结构为一个”building block“。
其中右图又称为”bottleneck design”,目的一目了然,就是为了降低参数的数目,第一个1x1的卷积把256维channel降到64维,然后在最后通过1x1卷积恢复,整体上用的参数数目:1x1x256x64 + 3x3x64x64 + 1x1x64x256 = 69632,而不使用bottleneck的话就是两个3x3x256的卷积,参数数目: 3x3x256x256x2 = 1179648,差了16.94倍。 (这部分如果看起来比较生涩的话,可以先跳过,待会看完5.2小节再回来看就简单了~)
网络中的网络以及 1×1 卷积
(详细看源博客)
在架构内容设计方面,其中一个比较有帮助的想法是使用1×1卷积。也许你会好奇,1×1的卷积能做什么呢?
1×1卷积可以从根本上理解为对这32个不同的位置都应用一个全连接层,全连接层的作用是输入32个数字(过滤器数量标记为,在这36个单元上重复此过程),输出结果是6×6×#filters(过滤器数量),以便在输入层上实施一个非平凡(non-trivial)计算。1×1卷积层就是这样实现了一些重要功能的(doing something pretty non-trivial),它给神经网络添加了一个非线性函数,从而减少或保持输入层中的通道数量不变,当然如果你愿意,也可以增加通道数量。
2.2 FPN网络

先验框anchor
RetinaNet网络的输出为5张大小不同特征图,那么不同大小的特征图自然是负责不同大小物体检测(和特征图所对应的感受野相关)。
可以看出,对5个不同大小的特征图:
[原图大小/8, 原图大小/16, 原图大小/32, 原图大小/64, 原图大小/128]base_size设置为:
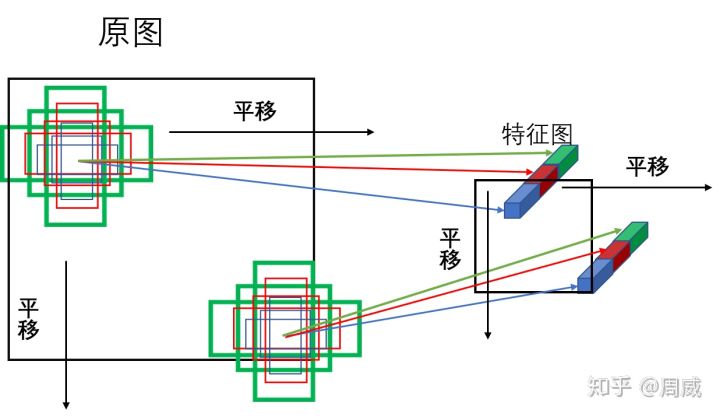
[32,64,128,256,512]即对于长宽为(原图大小/8,原图大小/8)的特征图,其特征图上的每个 单元格cell 对应原图区域上(32,32)大小的对应区域(如下图所示,这里对应的大小并不是实际感受野的大小,而是一种人为的近似设置)。特征图cell和原图的对应关系
那么在大小为base_size的正方形框的基础上,对框进行长宽比例调整(3 种,分别为[0.5, 1, 2])和缩放(3种,分别为[2 ** 0, 2 ** (1.0 / 3.0), 2 ** (2.0 / 3.0)]),便形成9种所谓的基础框/先验框anchor,如下图所示,(注意颜色对应),为一个单元格cell的通道维和anchor对应的关系。
一个单元格cell的通道维和anchor对应的关系
将上图的anchor按固定长度进行平移,然后和其对应特征图的cell进行对应,如下图所示。
anchor的平移和对应
这样,经过对每个特征图做类似的变换,生成全部anchor。


4. Focal Loss损失函数
RetinaNet最主要的创新点在于其使用Focal Loss解决前景和背景样本不平衡的问题。