- 聚类分析
百度百科:聚类分析指将物理或抽象对象的集合分组为由类似的对象组成的多个类的分析过程。同一个簇中的对象有很大的相似性,而不同簇间的对象有很大的相异性。
方法——(还可直接用SPSS)
1. 系统聚类法(适用于数据量比较小的情况)
2. K-均值法:先把样品粗略分为K个初始类别,逐个分派样品到其最近均值的类中(通常用标准化数据计算欧式距离),重新计算类的均值,直到没有新元素的进出情况。
matlab代码——
Y=pdist(X); SF=squareform(Y); Z=linkage(Y,'average'); dendrogram(Z); T=cluster(Z,'maxclust',n) %n是类的最大数目 %代码参考:https://blog.csdn.net/henu111/article/details/81512314
- 因子模型&主成分分析
因子模型的提出主要是为了解决数据维度过大的问题,假设原有P个X变量,现通过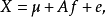 用少于P的m个F变量对X进行衡量,其中A为变换系数矩阵,里面的元素可以称为因子载荷,类比标准化后的β参数,其绝对值越大越好。
用少于P的m个F变量对X进行衡量,其中A为变换系数矩阵,里面的元素可以称为因子载荷,类比标准化后的β参数,其绝对值越大越好。
其中因子载荷 aij 的统计意义就是第i个变量与第 j 个公共因子的相关系数即表示 Xi 依赖 Fj 的份量(比重))
构建因子模型一共有三种方法(计算因子载荷的三种方法)——
- 主成分分析法
a.对原始数据X进行标准化处理为Z,同时根据标准化的数据计算简单相关系数矩阵R/协方差矩阵Σ;根据相关系数矩阵R/协方差矩阵Σ解出特征值和主成分系数,并且把特征值从大到小进行排列。
[coeff,latent,explained] = pcacov(X); %coeff是主成分系数;latent是特征值;explained是每个主成分方差占总方差的百分比
这里matlab输出的主成分系数行代表原始变量X,列代表主成分Z,每一列Z是用表格中的数据*X组合而出。
b.根据特征值和主成分系数计算得因子载荷矩阵B: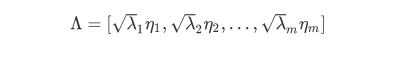
c.根据特征值大于1或者累计特征值比率大于某个特定值来确定要在列上选择多少公共因子进入因子模型分析。
d.根据上述因子载荷矩阵进行因子旋转得C。其中因子旋转即正交变换,不仅是找出公共因子以及对变量分组,更重要的是找出每个公共因子的含义。而因子旋转一共也有三个旋转方法:方差最大化/四次方最大旋转/等量最大法;下面的代码采用第一种方法:
[lambda2,t] = rotatefactors(lambda(:,1:num),'method','varimax');
e.计算因子得分:得分F = X*R'*C'(相当于是用X来表示F,之前是用F来表示Z);最后再根据F1,F2,F3,……等公共因子的各自得分*因子贡献率的权重算出最后得分F
f.根据最后得分F与有实际经济意义的变量进行回归分析,得到因子分析法的回归方程
2.主因子法
3.极大似然估计
[lambda,psi,T,stats,F] = factoran(X,m,param,val); %X为分析数据矩阵,m为公共因子个数,param和val分别表示正交因子旋转矩阵的属性及其取值(默认为最大方差正交变换) %lambda是因子载荷矩阵,psi为个体因子方差向量,T为因子旋转矩阵,stats是一系列检验统计量(以公共因子为m是H0假设),F是公共因子得分