上文记忆网络介绍模型并非端到端的QA训练,该论文End-To-End Memory Networks就在上文的基础上进行端到端的模型构建,减少生成答案时需要事实依据的监督项,在实际应用中应用意义更大。
本文分为三个部分,分别是数据集处理、论文模型讲解及模型构造、模型训练。主要参考代码为MemN2N。
数据集处理
==
论文中使用了babi数据集,关于本数据集在文章Ask Me Anything: Dynamic Memory Networks for Natural Language Processing 阅读笔记及tensorflow实现中有详细介绍并有处理流程,因此在这里也不再赘述。
模型讲解及构建
模型的结构如下图所示。图(a)是单层的模型,图(b)是多层模型(三层)。
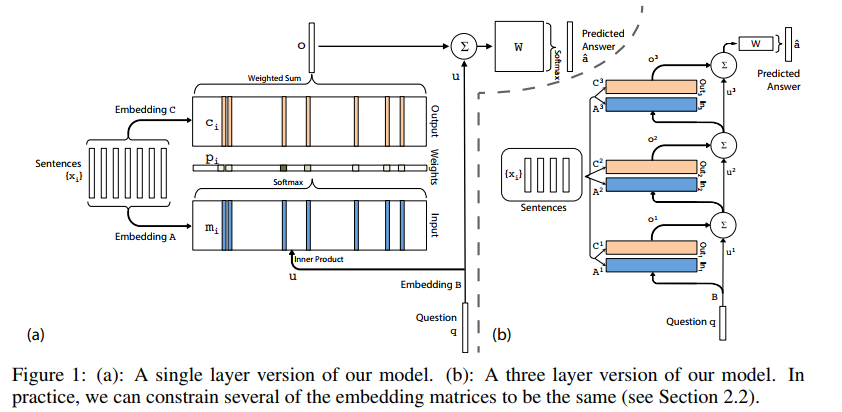
单层记忆网络
以图(a)为例,输入有两个部分,
使用输入集合
首先,上下文集合S通过隐含层矩阵Embedding
其中,
然后,每个输入
答案向量的编码向量o以后,需要解码生成预测的答案,通过一个待训练矩阵
多层记忆网络
如图(b)所示,多层记忆网络和单层的基本结构是类似的,有一些小的细节需要改变,以将几个单层网络连接起来。
1、将
2、每一层都有嵌入矩阵
2.1相邻的嵌入矩阵相同,这样比着之前减少了一般参数,即
2.2层间共享参数,即
论文中也提到2.1的方式比2.2的方式训练效果要好很多。
模型构建代码
按照代码的逻辑捋一下训练时需要注意的重要参数:
story:[None,10,7] –Sentences最多有10句话,每句话最多有7个单词。
query:[None,7] –q问题最多有7个单词。
m_emb_A:[None,10,7,20] –story通过一个[vocab_size, embedding_size]的嵌入矩阵。
q_emb:[None,7,20] –query通过一个[vocab_size,embedding_size]的嵌入矩阵。
u_0:[None,20] –q_emb通过位置编码,具体细节详见4.1章,得到u_0代表问题的向量表示。
u_temp:[None,1,20] –u_0拓展维度变为[None,20,1],并且将第一维和第二维进行transpose得到[None,1,20]。
m_A:[None,10,20] –得到10句话的向量表示。
dotted:[None,10] –将u_temp与m_A点乘,并求和,得到记忆单元中10句话的权重。
probs:[None,10] –得到softmax概率。
probs_temp:[None,1,10]
m_emb_C:[None,10,7,20] –同m_emb_A
m_C:[None,10,20] –同m_A
c_temp:[None,20,10]
o_k:[None,20] –得到输出编码向量
with tf.variable_scope(self._name):
# Use A_1 for thee question embedding as per Adjacent Weight Sharing
# 将问题变量queries通过嵌入矩阵A_1得到问题向量q_emb
# 然后将q_emb与其位置编码变量_encoding加权求和得到u_0
# self._encoding是位置编码向量,就是对词出现的顺序进行编码,具体细节详见4.1章
q_emb = tf.nn.embedding_lookup(self.A_1, queries)
u_0 = tf.reduce_sum(q_emb * self._encoding, 1)
u = [u_0]
# 总共三层,待训练的参数有四个矩阵,分别是A_1,C_1,C_2,C_3
for hopn in range(self._hops):
# 对于第一层,记忆单元的嵌入矩阵为A_1
if hopn == 0:
m_emb_A = tf.nn.embedding_lookup(self.A_1, stories)
m_A = tf.reduce_sum(m_emb_A * self._encoding, 2)
# 对于第二层和第三层,记忆单元的嵌入矩阵分别为C_1和C_2
else:
with tf.variable_scope('hop_{}'.format(hopn - 1)):
m_emb_A = tf.nn.embedding_lookup(self.C[hopn - 1], stories)
m_A = tf.reduce_sum(m_emb_A * self._encoding, 2)
# hack to get around no reduce_dot
u_temp = tf.transpose(tf.expand_dims(u[-1], -1), [0, 2, 1])
dotted = tf.reduce_sum(m_A * u_temp, 2)
# Calculate probabilities
probs = tf.nn.softmax(dotted)
probs_temp = tf.transpose(tf.expand_dims(probs, -1), [0, 2, 1])
with tf.variable_scope('hop_{}'.format(hopn)):
m_emb_C = tf.nn.embedding_lookup(self.C[hopn], stories)
m_C = tf.reduce_sum(m_emb_C * self._encoding, 2)
c_temp = tf.transpose(m_C, [0, 2, 1])
o_k = tf.reduce_sum(c_temp * probs_temp, 2)
# Dont use projection layer for adj weight sharing
# u_k = tf.matmul(u[-1], self.H) + o_k
u_k = u[-1] + o_k
# nonlinearity
if self._nonlin:
u_k = nonlin(u_k)
u.append(u_k)
# Use last C for output (transposed)
with tf.variable_scope('hop_{}'.format(self._hops)):
return tf.matmul(u_k, tf.transpose(self.C[-1], [1,0]))模型训练
模型训练部分就是一些熟悉的代码,这里不再赘述,大概经过100个epochs的训练,训练效果如下:

总体来说,端到端的记忆网络的提出,使记忆网络变得更加实用,不再需要对支持事实这一监督项,因此可用的数据集就变得更多。本篇代码使用的babi数据集,训练集和测试集各1000个,词表总共才30个,因此是一个极度简单的模型。因此在接下来的几篇文章中,将会采用较大的数据集对记忆网络以后发展的模型进行说明。