关键词
End2End, Memory Networks, Multiple hops
来源
arXiv 2015.03.31 (published at NIPS 2015)
特色
设计了全新网络,相对于LSTM,以词为单位的时序,memory network是以句子为单位。
解决方案
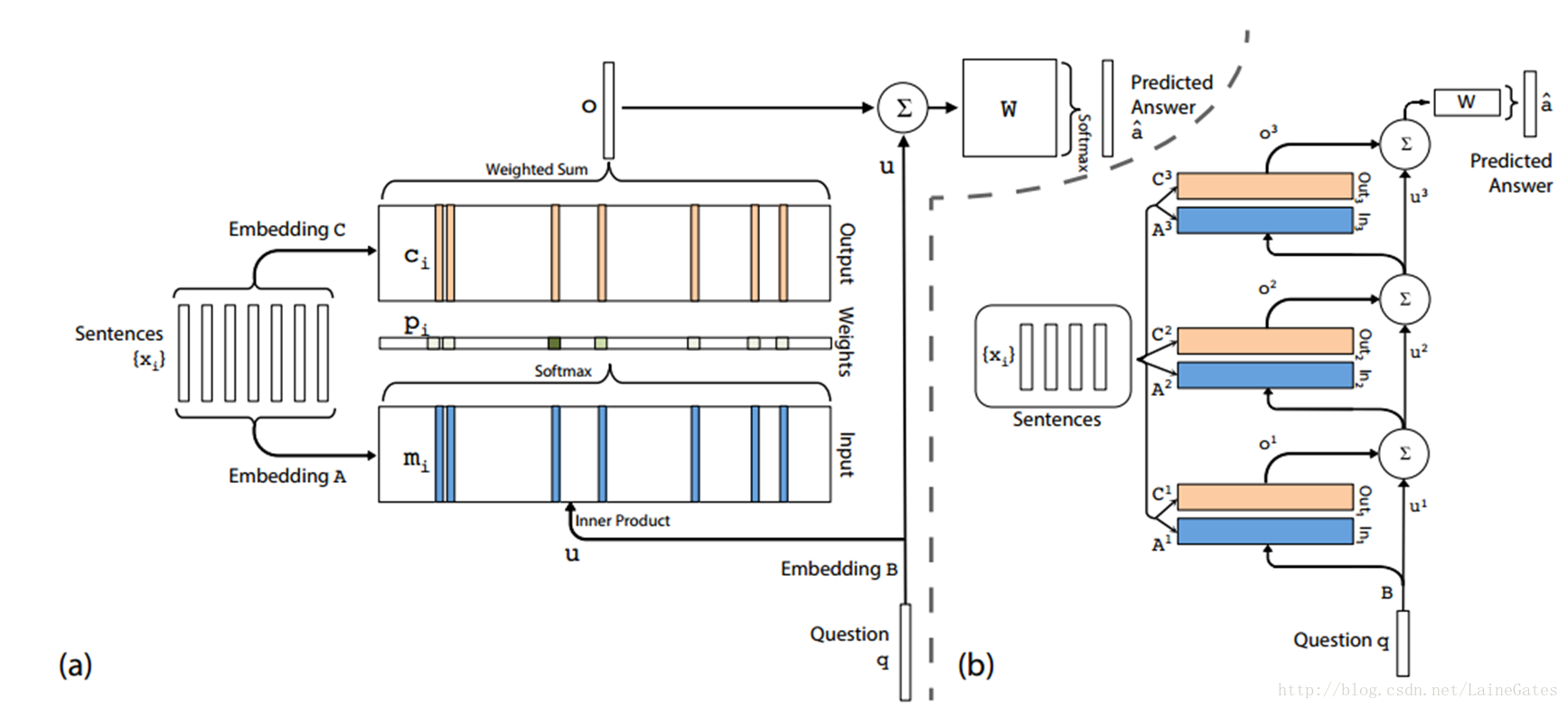
原图
加备注图
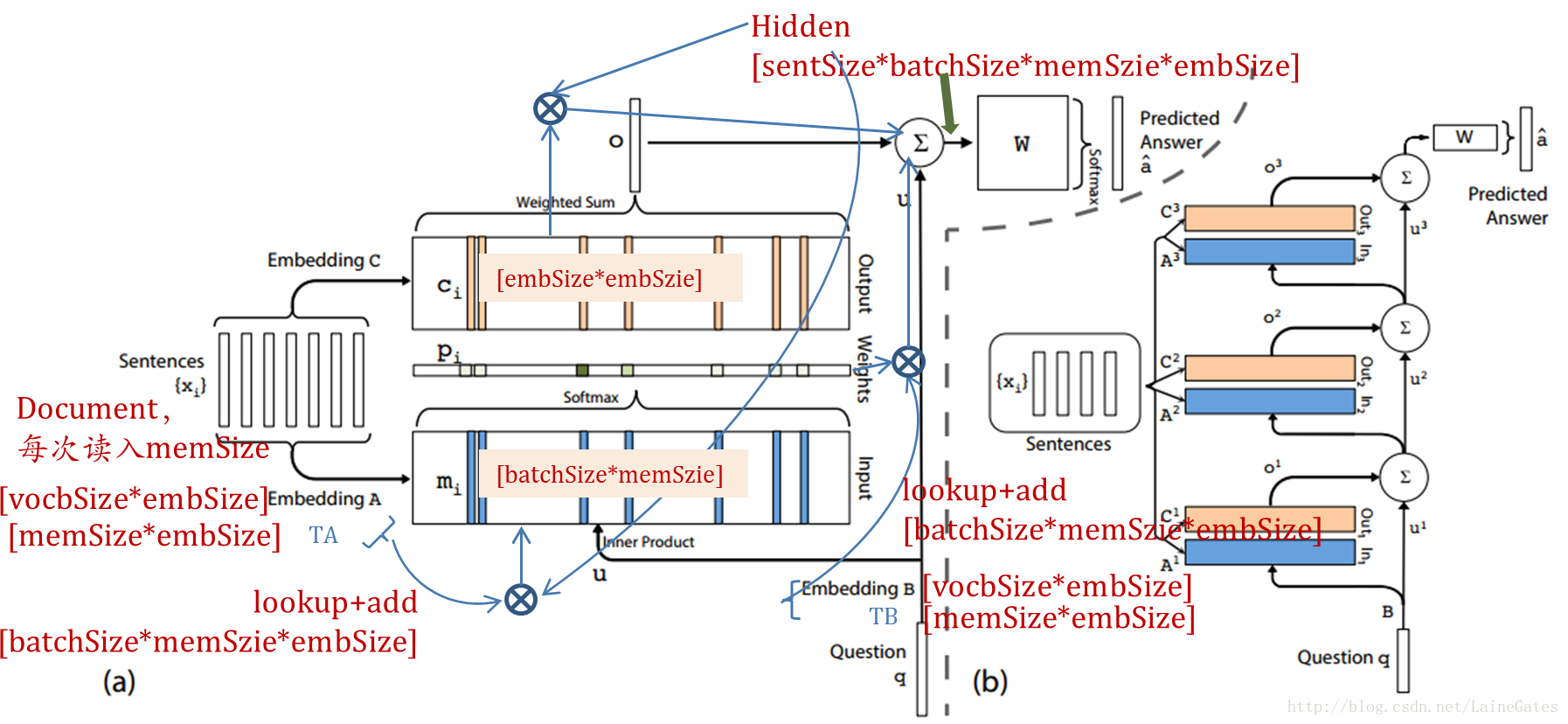
计算过程
按原图
lookup词表A获得句子向量表示,
计算attention,或者说计算输入的权重
将输出乘权重,得到最终的输出o
输出的嵌入向量
最终输出嵌入向量
查询的嵌入向量
预测结果
按实现代码
计算过程与原图不一致,我按论文的实现代码做了标注,参见备注图。
输入sentences和query时,都有矩阵TA和TB矩阵
即
最后,保存
多层网络
原文提供两种方式。
第一种是邻接,即
第二种是类似于 RNN 中共享权重的模式,
其余与单层网络一致。
参考代码
facebook实现,使用Lua语言
网友实现,使用tensorflow