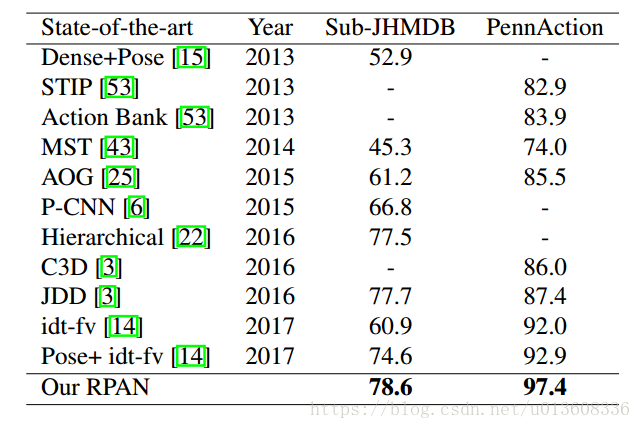
这是一篇视频动作识别的论文,但值得注意的是,他利用了pose estimation的信息,即视频中人物的关节点的信息。论文没有在常见的HMDB和UCF101上测试,而是在两个带有关节点信息的小数据集上进行了测试, Sub-JHMDB and PennAction。
一、文章框架
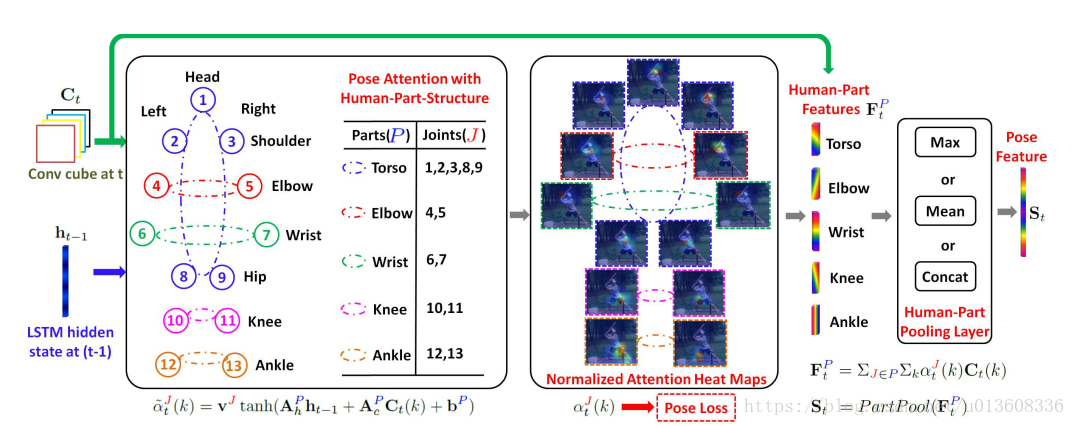
1.卷积特征
本文首先用TSN提取每帧图片的feature map, 9×15×1024。即上图中的Ct,TSN并没有画出来
2.attention mechanism.
将feature map 以及上一时刻lstm的隐藏特征
送入attention模块,得到attention map, 9*15
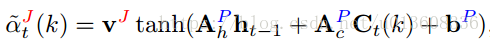
文中最后分析了,这个attention 机制最后能使lstm捕捉到更多的运动特征,所以attention主要是帮助lstm.
(在什么情况下attention能帮助CNN,使它只提取想要的位置的特征?位为什么不联合TSN的卷积层一起训练?)
3. bodyPart特征
再将feature map和attention按照一定的方式相乘,得到每个body part 的特征Ft,p再拼接得到整个图片的特征St
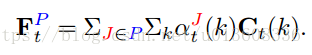
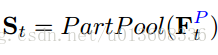
4.LSTM时序记忆
将St送入lstm,记忆整个视频的信息,最后得出分类
损失函数包含两部分,一部分是类别的交叉熵损失函数,另一个是结合attention的pose loss
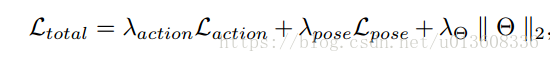
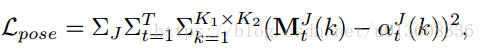
本人认为最重要的就是这个pose loss ,用它来控制attention更加关注于各个关节点。不同于之前的attention 方法,只有类别loss。
这里的
就是attention heat map
这里的
就是所谓的pose guidance , 即ground truth heat map.
以关节点中心加上高斯分布,然后再resize到和attention heat map 相同大小。
二、对比其他方法
- 双流网络,其中光流只能获取短时间上的信息
- CNN+LSTM,其中CNN由全连接层中提取出的特征,不能表示精细的动作
- 之前的attention+lstm方法,loss只涉及了分类的交叉熵损失函数,缺乏temporal guidance(本文加了joints guidance以及pose loss ),并不能很好的训练LSTM
三、关节点&feature map

1.首先,frame被resize到和feature map一样大小,9×15
2.然后找到关节点在feature map中的对应位置,
3.在所有的feature map 中找到每个关节点的最高激励, highest-activated feature map
4.将这个feature map 重新resize到原frame大小,找到80X80的loaction
这样就取出了feature中最高激励对应的关节点的的位置.
我猜这个找到80X80的location可能只是作者想说明一下resize的过程。和最后pose estimation 中的attention heat map 不是一个东西。
四、关于文章的一些问题
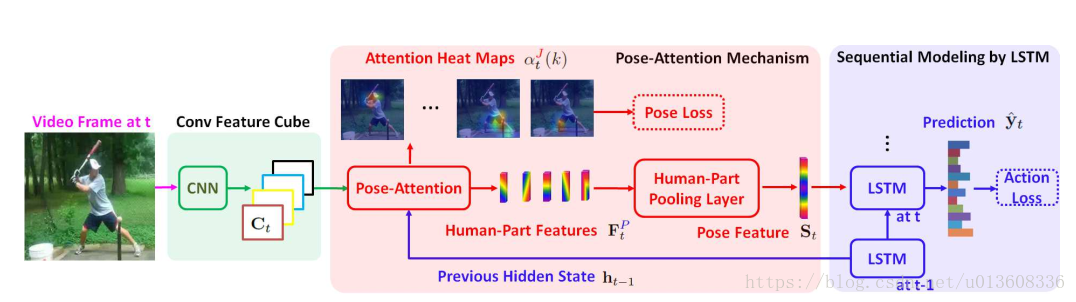
1.文中的bodypart P 具体是对应feature map的哪些像素呢,还是对应哪些feature map?难道是fig.1中 highest-activated feature map的组合?
具体的是哪些,还需要看代码
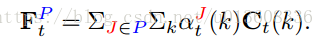
2.在训练的时候知道关节点的位置,在预测的时候不知道关节点的信息, 那在测试的时候,我猜已经没有这个
了
For a testing frame, we use the estimated heatmaps of all joints (Eq. 2 - 3) to summarize the convolutional cube as a pose feature
这句话的意思是test时没有
了,只是把所有的part加起来构成一个整体的feature 用于分类?
4.TSN是双流网络,你的一个流用的是RGB,另一个流用的光流吗?
但是TSN的RGB流输入的是一张图片,怎么用LSTM呢
In this case, we perform our RPAN separately on the convolution cubes from different streams, similar to two-stream fashion of TSN.
这句话也不太理解
5. byproduct论文中说本文的一个副产品是可以用来做pose estimation , 在测试阶段 ,将估计出来的attention heat map中,attention score最高的作为关节点的位置。
attention heat map 不是只有一个9X15的 map吗,这里attention score最高,是指局部最高吗(因为有很多关节点)? 每个关节点的局部最高是怎么确定的呢
6.关于feature map Ct 的维度,dc ==1024?
五、实验部分
1.attention 机制
without :不加attention
share all:没有关节点信息的attention
Separate-Joint:attention mechanism with guidance of separate joints
Human-Part: pose-attention mechanism with human-part-structure
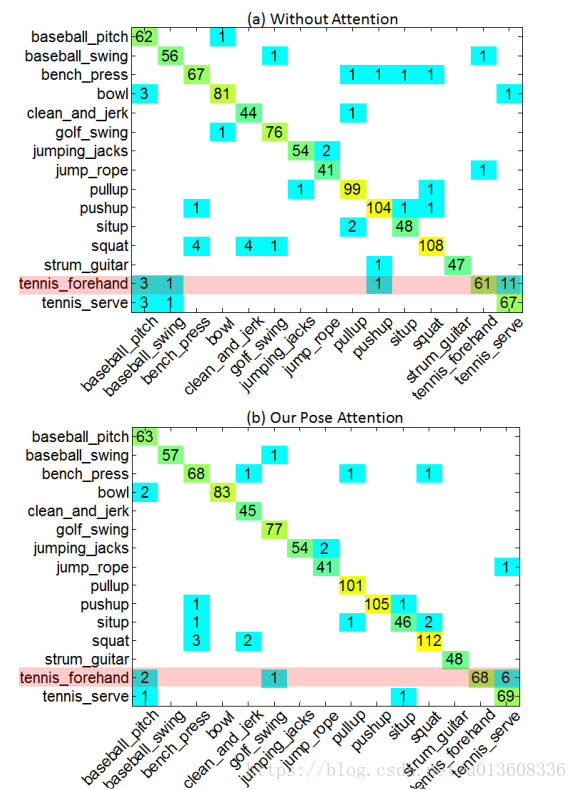
四种方法的效果依次增加,加attention的比不加好,将关节点组合成bodyPart比关节点分开要好。文中给出了在PennAction数据集上的confusion matrx,感觉每个类别的差距并不大,也可能是数据集太小?
2. Huamn part pooling
文章对比了三种拼接body part 特征的方法,其中拼接是最好的

3.提取CNN 的网络
文章中对比了两种用来提特征的网络,TSN比较好一些

TSN本身已经是视频动作识别中一种比较好的方法了,不过TSN的时序记忆并没有采用LSTM,而是分成了两个网络, Temporal 和 Spatial stream. Temporal输入的是多张光流图片,Spatial输入的是单张RGB图片。RPAN的每一个流的效果在这两个数据集上都要比TSN好。也可能是数据集的原因。
本文还用TSN在这两个数据集上做了验证,看来也是花了不少功夫。