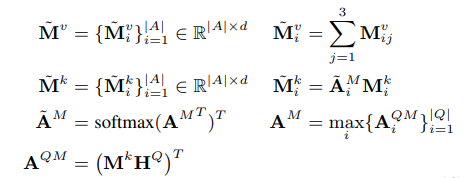最近刚好在看BAMnet 这篇做KBQA的实验,顺带把记忆网络的几篇经典文章看了一下做一下总结。另外就是 Facebook 7月份刚上传的一篇用 memory 来改进 BERT 结构的文章 Large Memory Layers with Product Keys Memory 这个概念的运用拓展。
MEMORY NETWORKS
记忆网络的提出主要是解决 RNN 的隐层无法保存长期记忆、能传达的记忆内容太少的问题。这里就引入了一种外部记忆模块就和 RAM 一样能保存大量历史信息,与一些读写模块一起组成了 Memory Network,如下图:
由图中可以看出一共有四个模块:
I: input feature mapG: generalizationO: outputR: response
具体来说,I模块是 embedding lookup,将原始文本转化为词向量,G模块将输入的向量存储在memory数组的下一个位置,不做其他操作,对老的记忆不做修改。O模块根据输入的问题向量在所有的记忆中选择出 topk 相关的记忆,具体选择方式为,先选记忆中最相关的memory:
o
1
=
O
1
(
x
,
m
)
=
arg
max
i
=
1
,
…
,
N
s
O
(
x
,
m
i
)
o_{1}=O_{1}(x, \mathbf{m})=\underset{i=1, \ldots, N}{\arg \max } s_{O}\left(x, \mathbf{m}_{i}\right)
o 1 = O 1 ( x , m ) = i = 1 , … , N arg max s O ( x , m i )
q
q
q
m
m
m
s
(
x
,
y
)
=
Φ
x
(
x
)
⊤
U
⊤
U
Φ
y
(
y
)
s(x, y)=\Phi_{x}(x)^{\top} U^{\top} U \Phi_{y}(y)
s ( x , y ) = Φ x ( x ) ⊤ U ⊤ U Φ y ( y )
o
1
o_1
o 1
x
x
x
o
2
o_2
o 2
o
2
=
O
2
(
x
,
m
)
=
arg
max
i
=
1
,
…
,
N
s
O
(
[
x
,
m
o
1
]
,
m
i
)
o_{2}=O_{2}(x, \mathbf{m})=\underset{i=1, \ldots, N}{\arg \max } s_{O}\left(\left[x, \mathbf{m}_{o_{1}}\right], \mathbf{m}_{i}\right)
o 2 = O 2 ( x , m ) = i = 1 , … , N arg max s O ( [ x , m o 1 ] , m i )
r
=
argmax
w
∈
W
s
R
(
[
x
,
m
o
1
,
m
o
2
]
,
w
)
r=\operatorname{argmax}_{w \in W} s_{R}\left(\left[x, \mathbf{m}_{o_{1}}, \mathbf{m}_{o_{2}}\right], w\right)
r = a r g m a x w ∈ W s R ( [ x , m o 1 , m o 2 ] , w )
k
=
2
k=2
k = 2
∑
f
‾
≠
m
o
1
max
(
0
,
γ
−
s
O
(
x
,
m
o
1
)
+
s
O
(
x
,
f
‾
)
)
+
∑
f
‾
′
≠
m
o
2
max
(
0
,
γ
−
s
O
(
[
x
,
m
o
1
]
,
m
o
2
]
)
+
s
O
(
[
x
,
m
o
1
]
,
f
‾
′
]
)
)
+
∑
r
⃗
≠
r
max
(
0
,
γ
−
s
R
(
[
x
,
m
o
1
,
m
o
2
]
,
r
)
+
s
R
(
[
x
,
m
o
1
,
m
o
2
]
,
r
‾
]
)
)
\begin{array}{c}{\sum_{\overline{f} \neq \mathbf{m}_{o_{1}}} \max \left(0, \gamma-s_{O}\left(x, \mathbf{m}_{o_{1}}\right)+s_{O}(x, \overline{f})\right)+} \\ {\sum_{\overline{f}^{\prime} \neq \mathbf{m}_{o_{2}}} \max \left(0, \gamma-s_{O}\left(\left[x, \mathbf{m}_{o_{1}}\right], \mathbf{m}_{o_{2}}\right]\right)+s_{O}\left(\left[x, \mathbf{m}_{o_{1}}\right], \overline{f}^{\prime}\right] ) )+} \\ {\sum_{\vec{r} \neq r} \max \left(0, \gamma-s_{R}\left(\left[x, \mathbf{m}_{o_{1}}, \mathbf{m}_{o_{2}}\right], r\right)+s_{R}\left(\left[x, \mathbf{m}_{o_{1}}, \mathbf{m}_{o_{2}}\right], \overline{r}\right]\right) )}\end{array}
∑ f = m o 1 max ( 0 , γ − s O ( x , m o 1 ) + s O ( x , f ) ) + ∑ f ′ = m o 2 max ( 0 , γ − s O ( [ x , m o 1 ] , m o 2 ] ) + s O ( [ x , m o 1 ] , f ′ ] ) ) + ∑ r
= r max ( 0 , γ − s R ( [ x , m o 1 , m o 2 ] , r ) + s R ( [ x , m o 1 , m o 2 ] , r ] ) )
总结
奠定了记忆网络的基础模型,里面所有模块都是可以用其它算法的
还没有做成端到端的形式
End to End MEMORY NETWORKS
上文的损失函数可以看出O和R模块承担了主要的任务并且都需要监督,我们需要知道O选择的supporting fact 是否正确,R生成的 response 是否正确。这篇其实就是用了soft attention 来估计每一个 supporting fact 的相关程度,实现了端到端的 BP 过程。论文中提出了单层和多层两种架构,多层其实就是将单层网络进行stack。
1、输入模块的主要作用是将输入的文本转化成向量并保存在memory中,本文中的方法是将每句话压缩成一个向量对应到memory中的一个slot(上图中的蓝色或者黄色竖条)。其实就是根据一句话中各单词的词向量得到句向量。论文中提出了两种编码方式,BoW和位置编码。BoW就是直接将一个句子中所有单词的词向量求和表示成一个向量的形式,这种方法的缺点就是将丢失一句话中的词序关系,进而丢失语义信息;而位置编码的方法,不同位置的单词的权重是不一样的,然后对各个单词的词向量按照不同位置权重进行加权求和得到句子表示。位置编码公式如下:
l
k
j
=
(
1
−
j
/
J
)
−
(
k
/
d
)
(
1
−
2
j
/
J
)
l_{k j}=(1-j / J)-(k / d)(1-2 j / J)
l k j = ( 1 − j / J ) − ( k / d ) ( 1 − 2 j / J )
m
i
=
∑
j
l
j
⋅
A
x
i
j
m_{i}=\sum_{j} l_{j} \cdot A x_{i j}
m i = j ∑ l j ⋅ A x i j
m
i
m_i
m i
T
a
T_a
T a
T
c
T_c
T c
m
i
=
∑
j
l
j
⋅
A
x
i
j
+
T
A
(
i
)
m_{i}=\sum_{j} l_{j} \cdot A x_{i j}+T_{A}(i)
m i = j ∑ l j ⋅ A x i j + T A ( i )
第一部分将Question经过输入模块编码成一个向量u,与mi维度相同,然后将其与每个mi点积得到两个向量的相似度,在通过一个softmax函数进行归一化:
p
i
=
Softmax
(
u
T
m
i
)
p_{i}=\operatorname{Softmax}\left(u^{T} m_{i}\right)
p i = S o f t m a x ( u T m i )
p
i
p_i
p i
q
q
q
m
i
m_i
m i
c
i
c_i
c i
p
i
p_i
p i
o
o
o
3、输出模块根据Question产生了各个memory slot的加权求和,也就是记忆中有关Question的相关知识,Response模块主要是根据这些信息产生最终的答案。其结合o和q两个向量的和与W相乘在经过一个softmax函数产生各个单词是答案的概率,值最高的单词就是答案。并且使用交叉熵损失函数最为目标函数进行训练。
4、多层结构(K hops)也很简单,相当于做多次 addressing、 attention,每次 focus 不同的 memory 上,不过在第 k+1 次 attention 时 query 的表示需要把之前的 context vector 和 query 拼起来,其他过程几乎不变,也就是说上面几层的输入就是下层o和u的和
u
k
+
1
=
u
k
+
o
k
u^{k+1}=u^{k}+o^{k}
u k + 1 = u k + o k
a
^
=
Softmax
(
W
u
K
+
1
)
=
Softmax
(
W
(
o
K
+
u
K
)
)
\hat{a}=\operatorname{Softmax}\left(W u^{K+1}\right)=\operatorname{Softmax}\left(W\left(o^{K}+u^{K}\right)\right)
a ^ = S o f t m a x ( W u K + 1 ) = S o f t m a x ( W ( o K + u K ) )
Adjacent:这种方法让相邻层之间的A=C。也就是说
A
k
+
1
=
C
k
A^{k+1}=C^k
A k + 1 = C k
Layer-wise (RNN-like):与RNN相似,采用完全共享参数的方法,即各层之间参数均相等。
A
1
=
A
2
=
…
=
A
K
A^{1}=A^{2}=\ldots=A^{K}
A 1 = A 2 = … = A K
C
1
=
C
2
=
…
=
C
K
C^{1}=C^{2}=\ldots=C^{K}
C 1 = C 2 = … = C K
u
k
+
1
=
H
u
k
+
o
k
u^{k+1}=H u^{k}+o^{k}
u k + 1 = H u k + o k
总结
Key-Value Memory Networks for Directly Reading Documents
其实看到key-value我第一反应就是之前看的self-attention,看完论文个人感觉其实还是挺相近的,key做寻址value做后续的加权求和。这里的KV-MemNN将memory存入(key,value)键值对,并且引入了Wiki、KB、IE三种知识库,整体框架如下:Key hashing :根据输入的问题从知识源中用倒排索引检索出与问题相关的facts存入memory,从而减小后续的进一步匹配数据量Key addressing :利用hashing的得到的 candidate memories 去和 query 线性变换后的结果计算一个相关概率:
p
h
i
=
Softmax
(
A
Φ
X
(
x
)
⋅
A
Φ
K
(
k
h
i
)
)
p_{h_{i}}=\operatorname{Softmax}\left(A \Phi_{X}(x) \cdot A \Phi_{K}\left(k_{h_{i}}\right)\right)
p h i = S o f t m a x ( A Φ X ( x ) ⋅ A Φ K ( k h i ) ) Value Reading :得到相关概率后对 value 进行加权求和得到输出向量
o
o
o
o
=
∑
i
p
h
i
A
Φ
V
(
v
h
i
)
o=\sum_{i} p_{h_{i}} A \Phi_{V}\left(v_{h_{i}}\right)
o = i ∑ p h i A Φ V ( v h i )
q
2
=
R
1
(
q
+
o
)
q_{2}=R_{1}(q+o)
q 2 = R 1 ( q + o )
p
h
i
=
Softmax
(
q
j
+
1
⊤
A
Φ
K
(
k
h
i
)
)
p_{h_{i}}=\operatorname{Softmax}\left(q_{j+1}^{\top} A \Phi_{K}\left(k_{h_{i}}\right)\right)
p h i = S o f t m a x ( q j + 1 ⊤ A Φ K ( k h i ) )
B
Φ
Y
(
y
i
)
B \Phi_{Y}\left(y_{i}\right)
B Φ Y ( y i )
a
^
=
argmax
i
=
1
,
…
,
C
Softmax
(
q
H
+
1
⊤
B
Φ
Y
(
y
i
)
)
\hat{a}=\operatorname{argmax}_{i=1, \ldots, C} \operatorname{Softmax}\left(q_{H+1}^{\top} B \Phi_{Y}\left(y_{i}\right)\right)
a ^ = a r g m a x i = 1 , … , C S o f t m a x ( q H + 1 ⊤ B Φ Y ( y i ) ) 总结
Bidirectional Attentive Memory Networks for Question Answering over Knowledge Bases
之前看的记忆网络全是为了这篇19年做KBQA的做铺垫,也算是对KBQA的理解性试验,代码作者也已经开源,这里主要还是关注文章中如何利用MemNN解决关系检测的问题。下图就是整体框架:1、Input module
H
Q
H^Q
H Q 2、Memory module
{
A
i
}
i
=
1
∣
A
∣
\left\{A_{i}\right\}_{i=1}^{|A|}
{ A i } i = 1 ∣ A ∣
Answer type : 每个实体都有一定的描述信息,利用这些描述信息体现实体类别可以有效的缩小检索范围,这里用BiLSTM进行编码Answer path :就是三元组中的关系信息,这里用了关系词向量的BiLSTM编码以及relation embedding的平均值拼接作为这一层面的信息Answer context :利用 candidate answer 周边的信息来约束答案,比如 Jon A. Husted 周围的government position titlesecretary of state 和 starting date 2011-01-09 ,这是解决有些question有指代歧义的问题的,比如问到“石头记”就可能指代电视剧或者书两种实体,他们附近的答案信息可以有效反馈约束信息。但是对于简单的问题这样反而会引入噪声,论文使用了两种解决方案:importance module(下面讲)和如果question和候选答案周围信息有重叠的情况下使用。
Key-value memory module 使用了一个 key-value memory network来存储候选答案。将以上三种编码信息按
d
∗
3
d*3
d ∗ 3
3、Reasoning module
KB-aware attention module
H
Q
H^Q
H Q
A
Q
Q
=
softmax
(
(
H
Q
)
T
H
Q
)
\mathbf{A}^{Q Q}=\operatorname{softmax}\left(\left(\mathbf{H}^{Q}\right)^{T} \mathbf{H}^{Q}\right)
A Q Q = s o f t m a x ( ( H Q ) T H Q )
q
=
BiLSTM
(
[
H
Q
A
Q
Q
T
,
H
Q
]
)
\mathbf{q}=\operatorname{BiLSTM}\left(\left[\mathbf{H}^{Q} \mathbf{A}^{Q Q^{T}}, \mathbf{H}^{Q}\right]\right)
q = B i L S T M ( [ H Q A Q Q T , H Q ] )
m
=
[
m
t
;
m
p
;
m
c
]
\mathbf{m}=\left[\mathbf{m}_{t} ; \mathbf{m}_{p} ; \mathbf{m}_{c}\right]
m = [ m t ; m p ; m c ]
H
Q
H^Q
H Q
q
q
q
q
i
q_i
q i
a
~
Q
\tilde{\mathbf{a}}^{Q}
a ~ Q
q
i
q_i
q i
t
y
p
e
,
p
a
t
h
,
c
o
n
t
e
x
t
type, path, context
t y p e , p a t h , c o n t e x t
Importance module
A
Q
M
A^{QM}
A Q M
q
q
q
A
~
M
\tilde{\mathbf{A}}^{M}
A ~ M
M
~
k
\tilde{\mathbf{M}}^{k}
M ~ k
Enhancing module
q
q
q
q
q
q
A
M
Q
=
max
k
{
A
.
.
.
,
k
Q
M
}
k
=
1
3
\mathbf{A}_{M}^{Q}=\max _{k}\left\{\mathbf{A}_{ . . ., k}^{Q M}\right\}_{k=1}^{3}
A M Q = max k { A . . . , k Q M } k = 1 3
A
~
M
Q
\tilde{\mathbf{A}}_{M}^{Q}
A ~ M Q
H
~
Q
=
H
Q
+
a
~
Q
⊙
(
A
~
M
Q
M
~
v
)
T
\tilde{\mathbf{H}}^{Q}=\mathbf{H}^{Q}+\tilde{\mathbf{a}}^{Q} \odot\left(\tilde{\mathbf{A}}_{M}^{Q} \tilde{\mathbf{M}}^{v}\right)^{T}
H ~ Q = H Q + a ~ Q ⊙ ( A ~ M Q M ~ v ) T
q
~
=
H
~
Q
a
~
Q
\tilde{\mathbf{q}}=\tilde{\mathbf{H}}^{Q} \tilde{\mathbf{a}}^{Q}
q ~ = H ~ Q a ~ Q
M
‾
k
\overline{\mathbf{M}}^{k}
M k
M
‾
k
=
M
~
k
+
a
~
M
⊙
(
A
~
Q
M
(
H
~
Q
)
T
)
a
~
M
=
(
A
~
M
Q
)
T
a
~
Q
∈
R
∣
A
∣
×
1
A
~
Q
M
=
softmax
(
A
M
Q
T
)
∈
R
∣
A
∣
×
∣
Q
∣
\begin{aligned} \overline{\mathbf{M}}^{k} &=\tilde{\mathbf{M}}^{k}+\tilde{\mathbf{a}}^{M} \odot\left(\tilde{\mathbf{A}}_{Q}^{M}\left(\tilde{\mathbf{H}}^{Q}\right)^{T}\right) \\ \tilde{\mathbf{a}}^{M} &=\left(\tilde{\mathbf{A}}_{M}^{Q}\right)^{T} \tilde{\mathbf{a}}^{Q} \in \mathbb{R}^{|A| \times 1} \\ \tilde{\mathbf{A}}_{Q}^{M} &=\operatorname{softmax}\left(\mathbf{A}_{M}^{Q^{T}}\right) \in \mathbb{R}^{|A| \times|Q|} \end{aligned}
M k a ~ M A ~ Q M = M ~ k + a ~ M ⊙ ( A ~ Q M ( H ~ Q ) T ) = ( A ~ M Q ) T a ~ Q ∈ R ∣ A ∣ × 1 = s o f t m a x ( A M Q T ) ∈ R ∣ A ∣ × ∣ Q ∣
Generalization modul
q
^
\hat{\mathbf{q}}
q ^
a
=
Att
a
d
d
G
R
U
(
q
~
,
M
‾
k
)
\mathbf{a}=\operatorname{Att}_{\mathrm{add}}^{\mathrm{GRU}}\left(\tilde{\mathbf{q}},\overline{\mathbf{M}}^{k}\right)
a = A t t a d d G R U ( q ~ , M k )
m
~
=
∑
i
=
1
∣
A
∣
a
i
⋅
M
~
i
v
\tilde{\mathbf{m}}=\sum_{i=1}^{|A|} a_{i} \cdot \tilde{\mathbf{M}}_{i}^{v}
m ~ = i = 1 ∑ ∣ A ∣ a i ⋅ M ~ i v
q
′
=
GRU
(
q
~
,
m
~
)
\mathbf{q}^{\prime}=\operatorname{GRU}(\tilde{\mathbf{q}}, \tilde{\mathbf{m}})
q ′ = G R U ( q ~ , m ~ )
q
^
=
B
N
(
q
~
+
q
′
)
\hat{\mathbf{q}}=\mathrm{BN}\left(\tilde{\mathbf{q}}+\mathbf{q}^{\prime}\right)
q ^ = B N ( q ~ + q ′ )
4、Answer module
S
(
q
,
a
)
=
q
T
⋅
a
S(\mathbf{q}, \mathbf{a})=\mathbf{q}^{T} \cdot \mathbf{a}
S ( q , a ) = q T ⋅ a
q
^
\hat{\mathrm{q}}
q ^
损失函数还是基于 hinge loss:
ℓ
(
y
,
y
^
)
=
max
(
0
,
1
+
y
^
−
y
)
\ell(y, \hat{y})=\max (0,1+\hat{y}-y)
ℓ ( y , y ^ ) = max ( 0 , 1 + y ^ − y )
g
(
q
,
M
)
=
∑
a
+
∈
A
+
ℓ
(
S
(
q
,
M
a
+
)
,
S
(
q
,
M
a
−
)
)
g(\mathbf{q},\mathbf{M})=\sum_{a^{+} \in A^{+}} \ell\left(S\left(\mathbf{q}, \mathbf{M}_{a^{+}}\right), S\left(\mathbf{q}, \mathbf{M}_{a^{-}}\right)\right)
g ( q , M ) = a + ∈ A + ∑ ℓ ( S ( q , M a + ) , S ( q , M a − ) )
o
=
g
(
H
Q
a
~
Q
,
∑
j
=
1
3
M
⋅
,
j
k
)
+
g
(
q
~
,
M
‾
k
)
+
g
(
q
^
,
M
‾
k
)
+
g
(
q
w
,
H
t
2
)
\begin{aligned} o=g\left(\mathbf{H}^{Q} \tilde{\mathbf{a}}^{Q}\right.&, \sum_{j=1}^{3} \mathbf{M}_{\cdot, j}^{k} )+g\left(\tilde{\mathbf{q}}, \overline{\mathbf{M}}^{k}\right) \\ &+g\left(\hat{\mathbf{q}}, \overline{\mathbf{M}}^{k}\right)+g\left(\mathbf{q}^{w}, \mathbf{H}^{t_{2}}\right) \end{aligned}
o = g ( H Q a ~ Q , j = 1 ∑ 3 M ⋅ , j k ) + g ( q ~ , M k ) + g ( q ^ , M k ) + g ( q w , H t 2 )
总结
记忆网络能很好地针对QA任务中的Multi-hop特性,如阅读理解中的上下文推理、多篇章的答案抽取,如KBQA中的多关系多实体的问题,如对话系统中的状态跟踪、多轮对话,最近facebook还用memory嵌入BERT体系大大提高BERT的效率,更多运用个人认为还是可以继续跟进的。知乎专栏-记忆网络