文章目录
0. 前言
YOLO v1~v3都是由YOLO之父Joseph Redmon大神提出,YOLO v1首次将检测问题制定为回归问题,在此之前都是采用分类的方式来解决目标检测问题(例如RCNN系列),YOLO v1的最大优势就是速度快;v2在v1的基础上针对检测精度进行改进,v3结合当时一些新颖的技术对v2做了一些重要的改进,被作者谦虚地戏称为TECH REPORT。
1. [YOLO v1] You Only Look Once:Unified, Real-Time Object Detection
1.1 亮点
- 将目标检测制定为回归问题。输入一张完整图像,单个网络直接预测出边界框和类别概率
- 速度快。base yolo 45fps,fast yolo 155fps
- 背景误检率低。因为能够结合上下文信息做预测
- 学习的是泛化表示,能够从自然图像推广到其他领域
1.2 算法细节
1.2.1 如何将目标检测转换为回归问题?
在yolo v1提出之前,RCNN系列的检测步骤大体为:“生成候选区域–>特征提取–>分类器判断类别–>非极大值抑制筛选–>边界框位置精修”,步骤比较繁琐,相应的推理速度也比较慢。YOLO v1开创性地使用单个神经网络直接预测边界框和物体类别,整体流程只包含“图像resize–>神经网络预测–>非极大值抑制”三个步骤,检测速度极快。

将目标检测指定为回归问题的主要思想如下图所示:

简单点说,就是将输入图像划分为 S × S S×S S×S个网格,如果物体的中心落在某个网格内,那么这个网格就负责检测该物体。每个网格预测B个边界框和一个类别概率,其中每个边界框预测x,y,w,h,confidence共5项,因此最终的预测为size为 S × S × ( B ∗ 5 + C ) S×S×(B*5+C) S×S×(B∗5+C)的tensor。
1.2.2 网络结构
YOLO v1所使用的网络结构如下,输入图像尺寸为448×448,经过一系列卷积层、池化层和全连接层后得到4096的特征向量,然后重排为7×7×30的tensor,即7×7×(2×5+20),表示将图像划分为7×7个grid,每个grid预测B=2个边界框和20个类别概率

1.2.3 损失函数
损失函数由位置损失、置信度损失和类别损失三部分组成:

需要注意的点如下:
-
大边界框和小边界框产生的宽高误差需要区别看待,因为同样的误差(10个像素),对于大边框(200×100像素)来说可能偏差很小,但是对于小边界框(20×10像素)来说偏差会比较大。因此,在求宽高损失时使用了平方根,尽可能地消除大尺寸边界框与小尺寸边界框之间的差异。
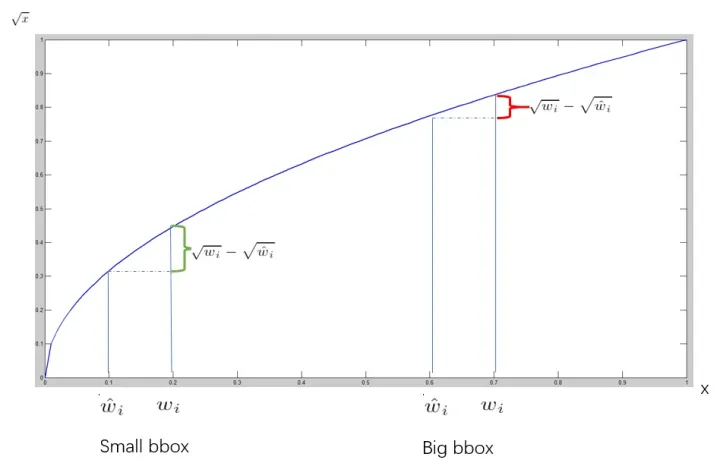
(图片来源:https://zhuanlan.zhihu.com/p/115759795) -
由于图像中大多数grid不包含待检测物体,包含待检测物体的grid占比很小,因此需要增大其损失的比重。论文中设置 λ c o o r d = 5 \lambda_{coord}=5 λcoord=5, λ n o o b j = 0.5 \lambda_{noobj}=0.5 λnoobj=0.5
-
根据图像的宽度和高度将边界框的宽度w和高度h归一化到0~1之间,回归偏移量代替直接回归坐标,使得预测的x,y也落在0到1之间。将参数限制在0到1之间能够降低网络学习难度,加快网络收敛速度。
-
每个grid会预测两个或多个边界框,但是在训练时,只对和gt最接近的边界框计算损失,这样设置后每个grid预测的多个边界框会出现功能分化,倾向于预测不同大小和宽高比。
1.3 不足
- 每个grid只预测两个bbox,导致密集的小物体检测能力差
- 模型从训练数据中学习预测边界框,因此难以推广到新的宽高比
- 网络中存在多个下采样层,最终使用较为粗糙的特征图进行预测,可能会导致小物体的检测效果不好
- 损失函数中对大边界框和小边界框的误差的处理方式是相同的,因此yolo v1主要误差来源是定位误差
2. [YOLO v2] YOLO9000:Better, Faster, Stronger
v2在v1的基础上引入了各种trick,做到better,faster和stronger
2.1 Better

- BN:在所有卷积层后添加BN,mAP提升了2%,并且BN起到了正则化的作用,可以移除网络中的Dropout
- 高分辨率分类器:yolo v1中训练backbone时的输入分辨率为224×224,在训练检测部分时将分辨率提高至448×448,因此网络需要适应新的分辨率;v2中以448×448的分辨率在imagenet上微调backbone,使卷积参数适应高分辨率输入,然后在检测数据集上微调网络,该操作提高了接近4%的mAP。
- 删除全连接层,使用Anchor box预测边界框:yolo v1中通过全连接层预测边界框的坐标偏移量,v2中删除全连接层,利用卷积的输出直接预测与anchor box的偏移量,最接近ground truth的才参与计算loss。由于没有全连接层,将网络的输入分辨率更改为416×416,经过32倍的下采样后正好能够得到13×13尺寸的特征图。
- 通过聚类产生Anchor box的尺寸:Faster RCNN中通过手工设定3种不同面积的anchor box,每种面积由3种宽高比,分别为1:1,1:2,2:1,一共有9个anchor box。在yolo v2中,作者将训练集中的矩形框全部取出,通过kmeans聚类得到更具有代表性的先验框,使网络更容易拟合到gt。在VOC 2007和COCO数据集上的实验表明,使用5个anchor box即聚类中心为5时,能够在召回率和模型复杂度之间取得权衡。

- 绝对位置预测:
bounding box的中心位置 ( b x , b y ) (b_x,b_y) (bx,by)是通过预测相对于grid cell左上角顶点的偏差而得到的,通过sigmoid将偏差限制到0~1之间, bounding box的宽高 b w b_w bw和 b h b_h bh是根据预测的 t w t_w tw和 t h t_h th对先验框的宽高 p w p_w pw和 p h p_h ph进行缩放而得。

- 细粒度特征:13×13的特征图用于检测大物体是足够的,但是更加精细的特征有助于检测小物体,作者引入了一个pass through层,将26×26×512的特征图重新排列为13×13×1024,这样就不会损失细粒度信息,再与原先的13×13做concat,从而提升小物体的检测能力。
- 多尺度训练:yolo v2网络的预测结果是卷积层的输出,为了使网络能够适应不同尺寸的输入,在训练过程中每10个batch更换一次输入分辨率,由于下采样倍数为32,因此设置可选的分辨率为{320,352,…,608}。

推理时,输入分辨率越低FPS越高,输入分辨率越高FPS越低,但是mAP越高。
2.2 Faster
提出了一个新的backbone–Darknet-19,对于224×224的输入,FLOPs为8.52 billion,相比VGG的30.69 billion要快得多。

2.3 Stronger
分类与检测联合训练:当输入是检测数据集时,整个loss执行反向传播;当输入是分类数据集时,只计算分类loss并进行反向传播。
由于检测数据集中包含的都是狗或猫这样的大类,但是分类数据集中包含了不同品种的猫狗,因此作者提出了WorldTree来合并类别。
3. [YOLO v3] An Incremental Improvement
参考文献
[1] You Only Look Once: Unified, Real-Time Object Detection
[2] YOLO9000:Better, Faster, Stronger
[3] YOLOv3: An Incremental Improvement