来自 https://blog.csdn.net/xiaoqu001/article/details/79350364
斯坦福大学的CS231n课程的主要内容是计算机视觉(computer vision),或者说是图像识别( visual recognition),算法主要关注CNN(convolutional neural network)或者说泛指的深度学习。计算机视觉是一门很强的交叉学科,生物学、心理学、物理学、工程和数学等等。
第一节课的主要内容有两个,一是研究计算机视觉的重要性,二是计算机视觉的发展简史。
计算机视觉的重要性
研究计算机视觉的重要性源自现在无处不在的摄像头以及大众对于视觉信息的青睐,视频和图像信息占据了互联网上流量的大部分,而且视频和图像信息增长迅速。讲者将互联网上的视频信息比喻成黑洞,意指体量大但是蕴涵其中的内容难以观测和分析。另外,计算机视觉也支撑着机器生产力的提高以及人工智能的普及。
计算机视觉简史
生物视觉(biological vision)的发展
大约543百万年前,地球上的古老生物还没有眼睛,在大海中张着嘴漫游,那时地球上可能只有几种生物。澳大利亚一位生物学家Anderw Parker在化石中发现了第一个拥有眼睛的生物,这个生物的时间大约在540百万年前,而后的一千万年间地球上的生物发生了指数式的增长,生物学家称之为生物进化的大爆炸(Big Bang of Revolution),此前关于此次生物大爆炸的猜测理论有很多,在发现了这只带眼睛的生物后,这位生物学家提出了一个理论:因为生物进化出眼睛,生物中的扑食者和猎物之间的活动开始变得更加积极(preactive),由此导致了生物进化速度的加快,生物数量从几个增长到千百万。到今天,在人类身上,视觉已经发展成为最大的感官系统(sensor system),视觉皮层(visual cortex)大约占据了大脑皮层的一半。可见视觉系统对于生物发展的重要性。

机器视觉(mechanical vision)的发展
Camera Obscura:六十年代文艺复兴时期开始有一些利用pinhole camera theory的相机诞生
人类在机器视觉上最早的尝试应该是暗箱成像,成像的原理是针孔成像,与生物眼睛的成像原理有相同之处。后来这种暗箱进一步发展,增加了双凸透镜、光圈和感光材料等等,经过几代技术革新就发展成今天的相机。

计算机视觉(computer vision)的发展
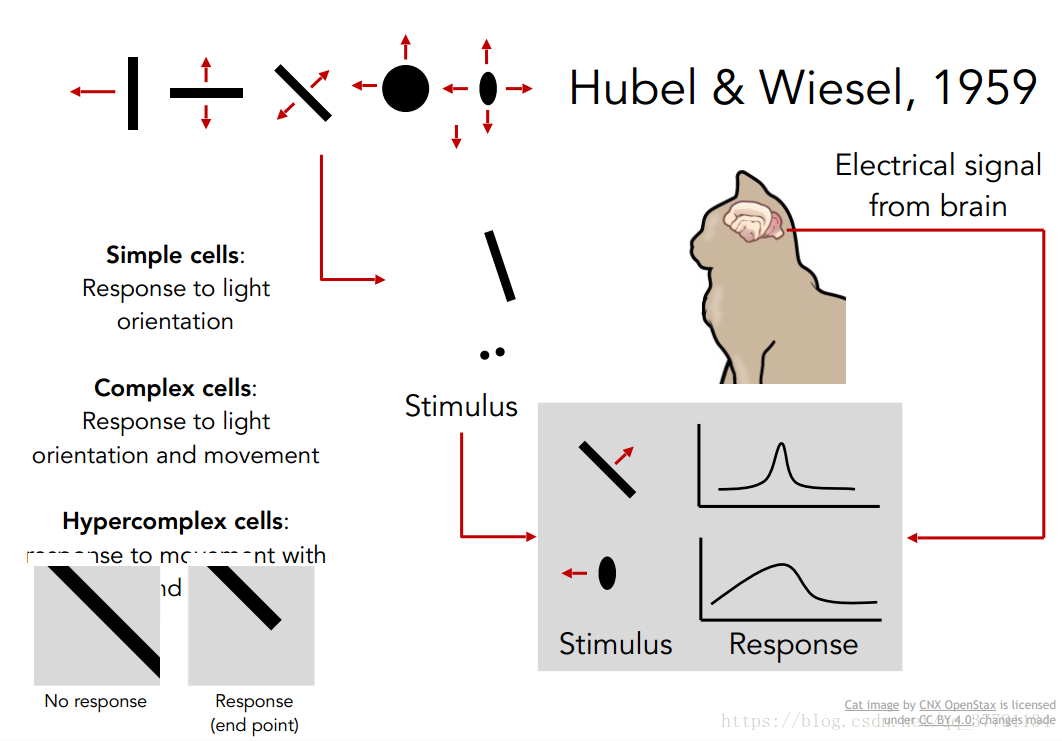
Huble和Wiesel于1959年
人类对于视觉形成原理的探索应该在很早就开始了,最早的一个具有里程碑意义的实验发生在1959年[1][2],生物学家Huble和Wiesel将电极植入猫的视觉皮层,并在猫的眼前投影各种线条和形状,他们发现猫的视觉平层中一些细胞会对特定的线条、形状或者角度敏感,他们将这些细胞称之为“small cell”,而还有一些“complex cell”可以检测特定的edge(与位置无关)或者特定的移动方向。后来这个实验的结论被不断总结为:视觉神经系统对事物复杂的表示来源于简单的特征,也就是一种层层抽象的表示方法。下图为原文中两个结论的截图。

Larry Roberts于1963年
他是第一篇计算机视觉博士论文的作者。在他的论文中,世界被简化为简单的几何图形,研究的目标是识别这些几何图形并且重组出这些图形(the world is simplified into simple geometric shapes and the goal is to able to recognize them and reconstruct what these shapes are)。
MIT于1966年
MIT(Massachusa Institute of Technology)的summer project,成立人工智能实验室,旨在希望在几个月内研究出视觉感知的机理,当然了这个目标很激进,至今我们都没将这一问题参透。

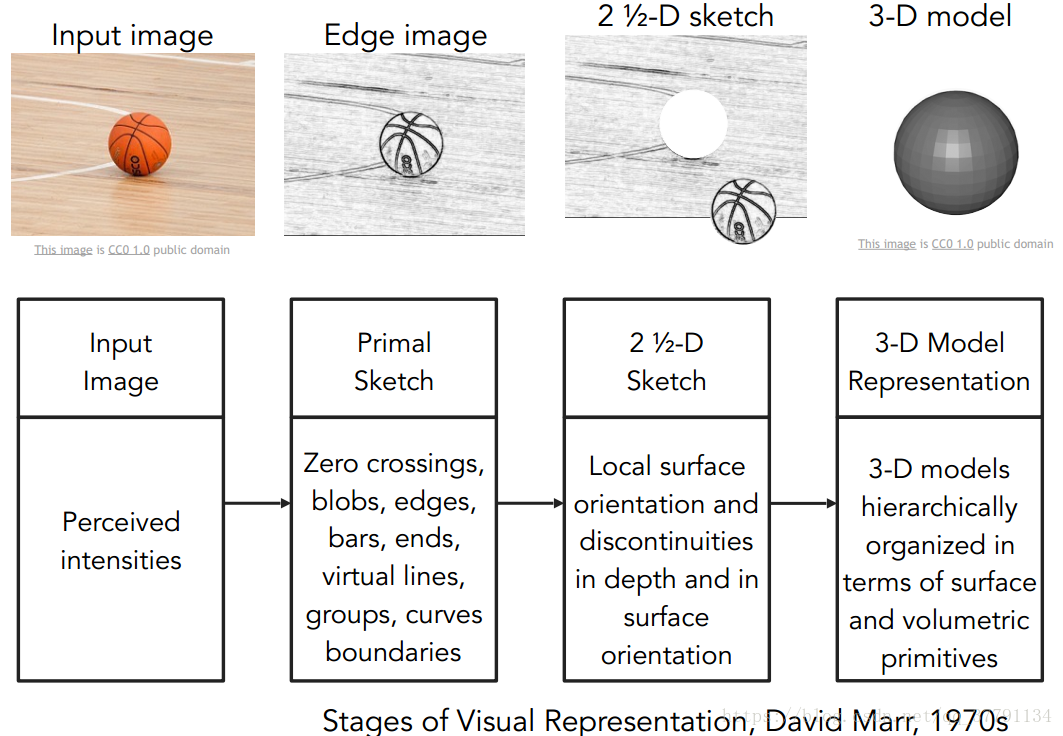
David Marr于1970
David Marr提出了视觉神经系统认知的过程,第一阶段是primal sketch,包含边缘、线条、条纹、界限和线条等等,第二阶段是2+1/2D,第二阶段可以分清整块的表面、深度和层次等等(piece together the surfaces, the depth information, the layers, or the discontinuities of the visual scene) ,第三阶段是3D抽象,层次化的表面和体积元信息(hierarchically organized in terms of surface and volumetric primitives)
写了本书,同时他提出了分层的概念:edge->sketch->3D model

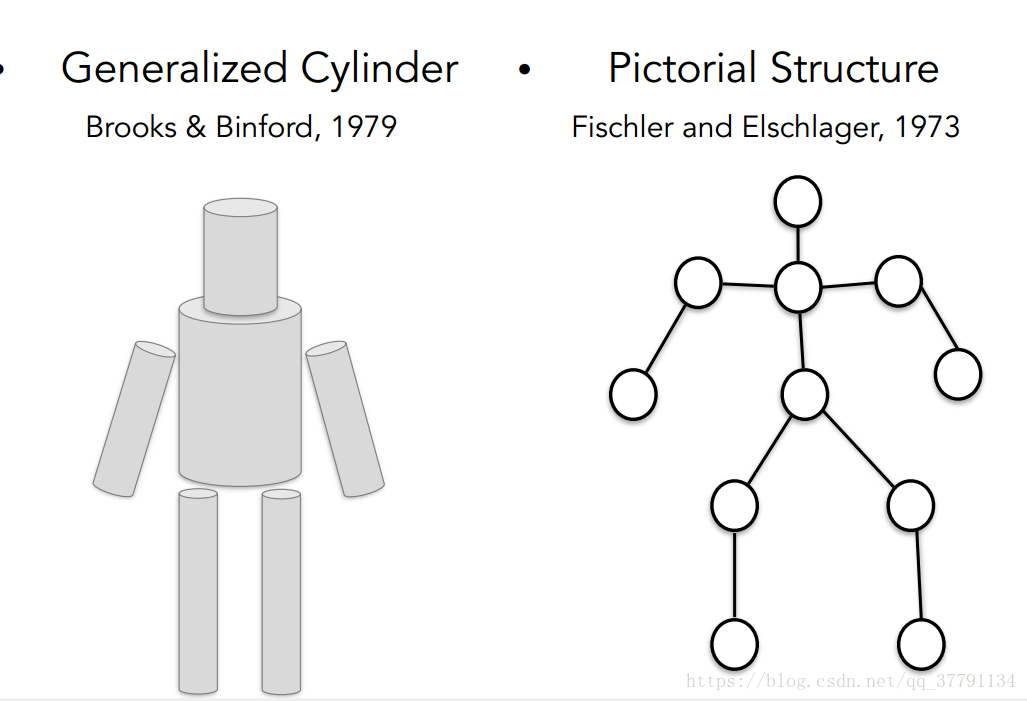
Brook和Binford于1979年以及Fischler and Elschlager于1973年
分别提出对复杂物体的抽象描述的理论,分别为:generalized cylinder和pictorial structure。他们指出每一个物体都是有简单的几何形状构成的。
David Lowe于1980s
David Lowe尝试运用线条和线条的组合来重组所见的图形 ,80年的David Lowe识别了一组剃刀的图片,指出物体可以由线和线的组合来表示
以上从60s-80s年代,计算机视觉的发展主要体现在理论猜想上,还是基于人的所见来分析神经系统的处理过程, 不是对相机拍摄得到图像数据的分析(当然了,那个时间也没有数字的图片信息),后来还有人提出图像分割的理论,试图通过色彩信息先进行图像分割再进行识别,这也基本停留在猜想阶段。
机器学习的发展
1997年Shi & Malik提出Normalized Cut,告诉我们如果直接识别物体太困难就先做图片的分割,分割成有意义的部分。

1990s到2010s之间机器学习算法的发展尤其是统计机器学习(statistical machine learning),比如支持向量机SVM、boosting和graphical models等,机器学习在计算机视觉领域一个成功的案例就是人脸识别,Paul Viola和Michael Jones于2001年提出运用Adaboost算法进行实时的人脸识别,并且FujiFilm公司运用这一算法在2006年产出了可以实时识别人脸的相机,实现了快速的成果转化。另外指的一提的是当时卷积神经网络已经被提出了,是在1998年由Yan Lecun等人提出,用来对邮票上的字符进行识别,当时神经网络在功能上根本无法与传统的机器学习算法抗衡,几乎奄奄一息。经过Yan Lecun等人的不懈坚持,神经网络算法终于迎来了丰富快速的计算资源以及大量的数据集,在2012年通过AlexNet(另外有个名字是supervision)打了一场翻身仗,自此开始迎来了蓬勃发展的时代。

David Lowe于1999年
提出了基于特征的图像识别,也就是SIFT(scale-invariant feature transform),尺度不变特征转换。基于特征的图像识别的内涵是一种事物的图像无论在角度、光线、变形和遮挡等变量影响下还会有一些典型特征(critical feature)是不变的(some features that tend to remain diagnostic and invariant to changes),通过将图像的这些典型特征提取出来进行特征对比要优于对整个图像进行模式对比(pattern comparison)
2006年Lazebnik et al.
提出了Spatial Pyramid Matching来识别整个图片的场景。他们发现实际图片中,无论是什么场景,都可以通过features,然后用SVM来进行分类。
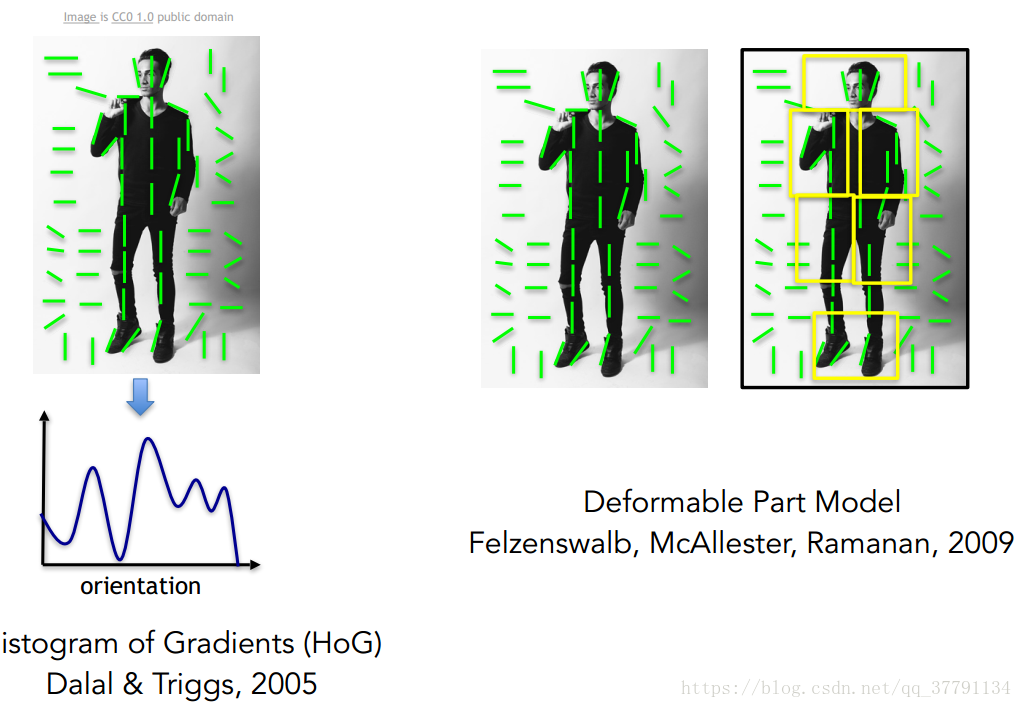
人体识别:Histogram of Gradients/Deformable Part Model
数据集的发展
为了评估计算机视觉的发展,以及得益于互联网的发展,开始出现作为计算机视觉算法测试激励的数据集。从2007-2012比较有影响的是PASCAL visual object challenge,后来就是李飞飞教授带领团队完成的ImageNet数据集。课程中李飞飞教授讲了两点制作这个数据集的目的,一是测试机器学习算法能否识别世界万物;二是将机器学习算法拉回来面对过拟合的问题。
-
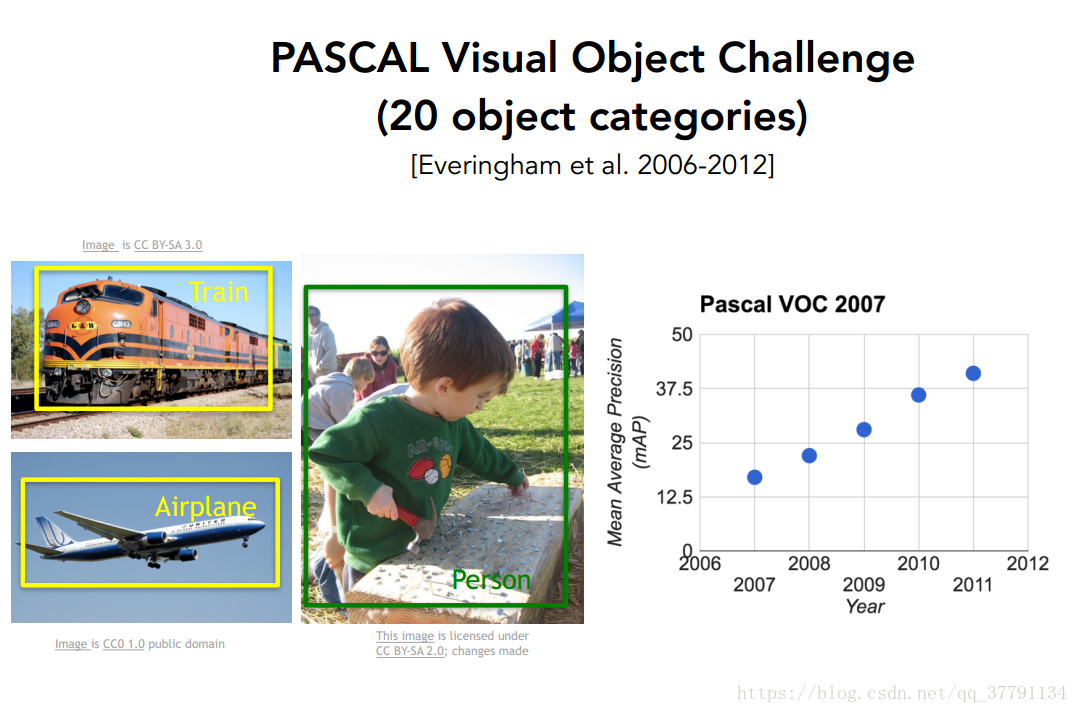
PASCAL Visual Object Challenge:20种物体图片
-
IMAGENET:1400万张图片,2.2万种类
-
ImageNet图片识别大赛:
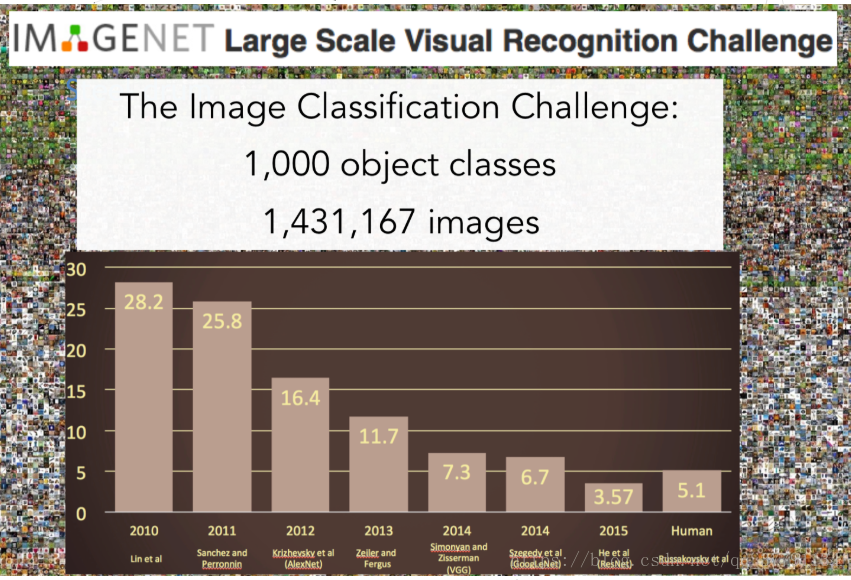
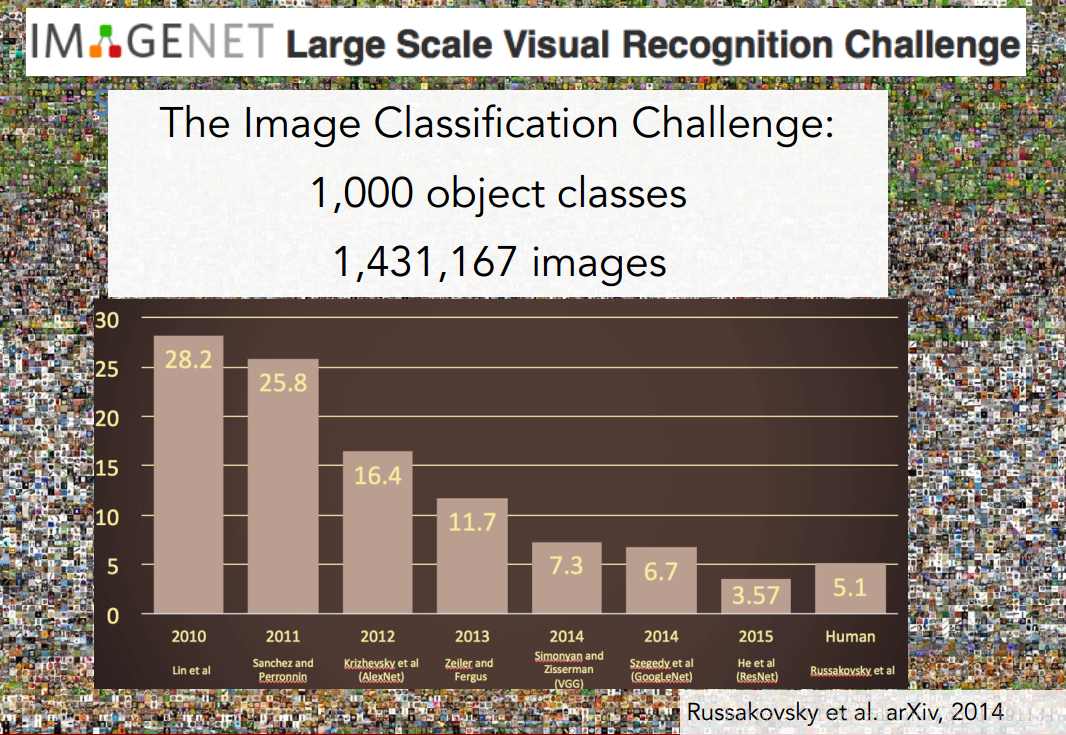
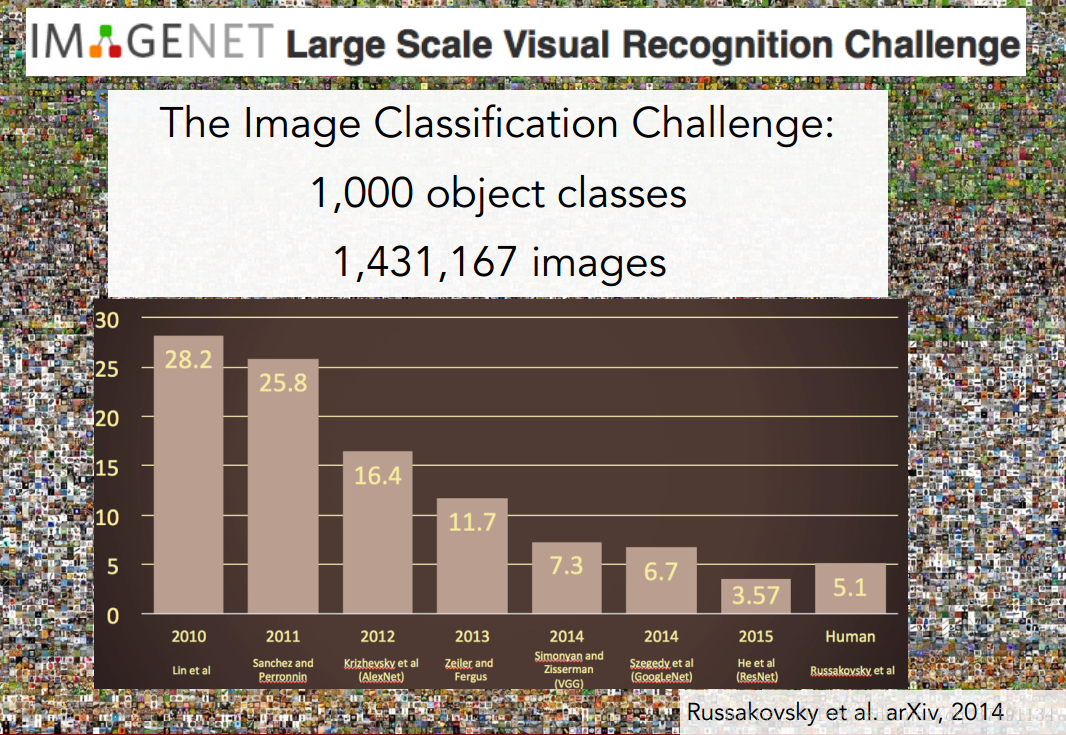
从2010年到2015年图识别的错误率逐渐降低,但是在2010和2011年错误率还在25%上下徘徊。
在2012年显著的下降了接近10%。获得冠军的就是Hinton提出的7层CNN,这也是这门课的重点。
https://www.kaggle.com/c/cifar-10/leaderboard Imaginet的排名,可看下。
计算机视觉的发展任重道远
在CNN的推动下,计算机视觉在某些情况下的识别精度和速率已经可以和人类不相上下,但是计算机视觉还处在初级阶段,计算机视觉在对图像信息的理解上还与人类有较大差距,人类看见一幅图可以产生很多符合情境的猜测,但是计算机还不能,相比于人类,计算机视觉要显得呆板很多,另外计算机视觉在识别中的功耗以及必须的计算资源也是一个问题。
CS231n OVERVIEW
课程重点
-
cs231n focuses on one of the most important problems of visual recognition – image classification
-
There is a number of visual recognition problemsthat are related to image classification:
object detection:利用画框标记物体在图片中的位置,并识别画框内的物体
image captioning:用自然语言来描述图片
Action classification
-
Convolutional Neural Networks (CNN) have become an important tool for object recognition
CNN的历史
刚才提到的ImageNetd大赛,从2012年之后,获胜的算法都是深度神经网络,在此之前,都是识别特征然后用SVM进行分类的。在2015年微软的团队MSRA甚至用到了152层的nn。
但是CNN并非2012才被发明的,早在1998年LeCun在贝尔实验室就使用了这种神经网络来识别手写钞票中的数字。
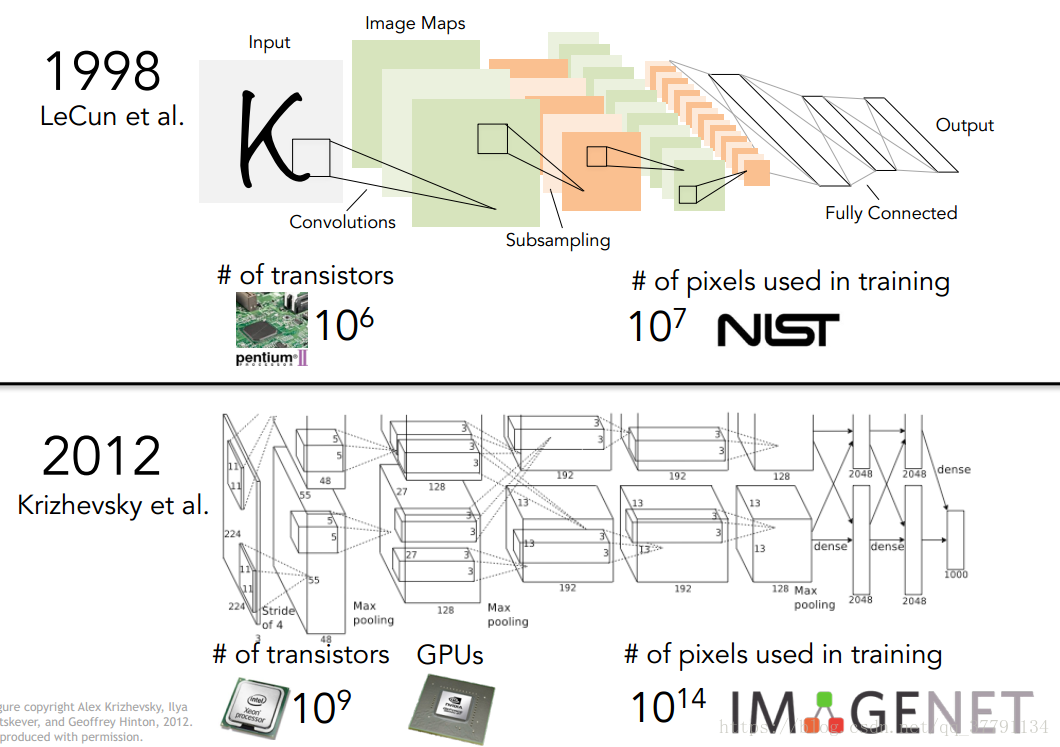
为什么直到现在CNN和深度神经网络才流行起来呢?主要是有两方面的原因:
一是CPU和GPU的计算能力不断加强,尤其是GPU的并行能力对于神经网络中的计算很有帮助。
二是大数据,无论是什么样的机器学习算法,没有足够的数据量都容易overfitting,而现在有了足够大的有标记的数据库
其他的问题
- 3D重建
- Activity Recognition
- 机器人视觉等
[1]: Receptive fields of single neurons in the cat’s striate cortex
[2]: Receptive fields, binocular interaction and functional architecture in the cat’s visual cortex