二、一些基础
上接: cuda并行编程基础(一)
(二)cuda基础:gridBlock.cu
4.总计算量与block、grid的关系
假设一维数组总计算量为total_c,怎么确定block与grid呢?
一维数组:
int cal_array[XX];
int thd_num=16;
dim3 block(thd_num);//一般block.x * block.y * block.z <=1024,1024这个值根据显卡性能确定
dim3 grid((XX + thd_num -1)/thd_num);//这里为何这么计算呢?
之所以grid.x = XX + thd_num - 1 /thd_num,原因是要保证block*grid >=XX
二维数组:
int cal_array[XX][YY];
int thd_x_num=16,thd_y_num=32;
dim3 block(thd_x_num,thd_y_num);//一般block.x * block.y * block.z <=1024,1024这个值根据显卡性能确定
dim3 grid((XX + thd_x_num -1)/thd_x_num,(YY + thd_y_num -1)/thd_y_num);//原因同一维数组
依次类推,读者可以确定三维数组的计算方法,至于思维数组怎么办?这个嘿嘿,自己想办法啦。
问题来了,这样的话,grid和block肯定有很多分配方法,对计算会有什么影响吗?答案是肯定的,别着急,以后再学啦,
5.内存管理
当然是GPU的内存,跟CPU一样,GPU的内存资源也有限制,申请内存太多会爆掉哦,
GPU内存分为共享内存和全局内存,所谓共享内存嘛,就是线程可以共享,全局嘛,所有都能访问咯
CPU:malloc memcpy memset free
GPU: cudaMalloc cudaMemcpy cudaMemset cudaFree
cudaError_t cudaMalloc(void **devPtr,size_t size);//只能对GPU数据
cudaError_t cudaMemcpy(void *dst,const void *src,size_t count,cudaMemcpyKind kind);//可以对GPU也可以对CPU或混合
cudaError_t cudaMemset(void *devPtr,int value,size_t count);//只能对GPU数据
cudaError_t cudaFree(void *devPtr);//只能对GPU数据
可以看到,GPU的内存管理函数相比CPU,无非加了“cuda”,还是很简单的。
cudaError_t:正确的话返回cudaSuccess,错误返回cudaErrorMemoryAllocation,你可以参看"cuda并行编程基础(一)",或者后面单独对错误处理的章节
cudaMemcpyKind可以有四个值哦:
cudaMemcpyHostToHost //CPU到CPU,相当与memcpy
cudaMemcpyHostToDevice //CPU到GPU
cudaMemcpyDeviceToHost //GPU到CPU
cudaMemcpyDeviceToDevice //GPU到GPU
第三个程序,比较重要但很简单
上接: cuda并行编程基础(一)
(二)cuda基础:gridBlock.cu
4.总计算量与block、grid的关系
假设一维数组总计算量为total_c,怎么确定block与grid呢?
一维数组:
int cal_array[XX];
int thd_num=16;
dim3 block(thd_num);//一般block.x * block.y * block.z <=1024,1024这个值根据显卡性能确定
dim3 grid((XX + thd_num -1)/thd_num);//这里为何这么计算呢?
之所以grid.x = XX + thd_num - 1 /thd_num,原因是要保证block*grid >=XX
二维数组:
int cal_array[XX][YY];
int thd_x_num=16,thd_y_num=32;
dim3 block(thd_x_num,thd_y_num);//一般block.x * block.y * block.z <=1024,1024这个值根据显卡性能确定
dim3 grid((XX + thd_x_num -1)/thd_x_num,(YY + thd_y_num -1)/thd_y_num);//原因同一维数组
依次类推,读者可以确定三维数组的计算方法,至于思维数组怎么办?这个嘿嘿,自己想办法啦。
问题来了,这样的话,grid和block肯定有很多分配方法,对计算会有什么影响吗?答案是肯定的,别着急,以后再学啦,
5.内存管理
当然是GPU的内存,跟CPU一样,GPU的内存资源也有限制,申请内存太多会爆掉哦,
GPU内存分为共享内存和全局内存,所谓共享内存嘛,就是线程可以共享,全局嘛,所有都能访问咯
CPU:malloc memcpy memset free
GPU: cudaMalloc cudaMemcpy cudaMemset cudaFree
cudaError_t cudaMalloc(void **devPtr,size_t size);//只能对GPU数据
cudaError_t cudaMemcpy(void *dst,const void *src,size_t count,cudaMemcpyKind kind);//可以对GPU也可以对CPU或混合
cudaError_t cudaMemset(void *devPtr,int value,size_t count);//只能对GPU数据
cudaError_t cudaFree(void *devPtr);//只能对GPU数据
可以看到,GPU的内存管理函数相比CPU,无非加了“cuda”,还是很简单的。
cudaError_t:正确的话返回cudaSuccess,错误返回cudaErrorMemoryAllocation,你可以参看"cuda并行编程基础(一)",或者后面单独对错误处理的章节
cudaMemcpyKind可以有四个值哦:
cudaMemcpyHostToHost //CPU到CPU,相当与memcpy
cudaMemcpyHostToDevice //CPU到GPU
cudaMemcpyDeviceToHost //GPU到CPU
cudaMemcpyDeviceToDevice //GPU到GPU
第三个程序,比较重要但很简单
//gridBlock.cu:block和grid的分配方法,一维数组
/*Authored by alpc40*/
int main(int argc, char **argv)
{
// 定义总计算量
int nElem = 1024;
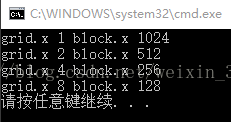
// 第一种分配法
dim3 block (1024);
dim3 grid ((nElem + block.x - 1) / block.x);
printf("grid.x %d block.x %d \n", grid.x, block.x);
// 第二种分配法
block.x = 512;
grid.x = (nElem + block.x - 1) / block.x;
printf("grid.x %d block.x %d \n", grid.x, block.x);
// 第三种分配法
block.x = 256;
grid.x = (nElem + block.x - 1) / block.x;
printf("grid.x %d block.x %d \n", grid.x, block.x);
// 第四种分配法
block.x = 128;
grid.x = (nElem + block.x - 1) / block.x;
printf("grid.x %d block.x %d \n", grid.x, block.x);
// 恢复GPU
CHECK(cudaDeviceReset());
return(0);
}
第四个程序,很重要哦
//memoryManage.cu:内存管理
/*Authored by alpc40*/
#define NUM 9//数组大小
//内核函数定义
__global__ void sumArrayOnGpu(int *d_arrayA, int *d_arrayB, int *d_result)
{
int i = blockDim.x * blockIdx.x + threadIdx.x;
if (i < NUM)//为什么要加这句呢?因为i的取值范围是[0,11](grid*block=12),要养成良好习惯,防止内存溢出
d_result[i] = d_arrayA[i] + d_arrayB[i];
}
int main()
{
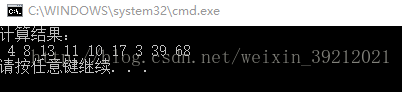
int arrayA[NUM] = { 3,4,6,7,8,9,1,19,35 };
int arrayB[NUM] = { 1,4,7,4,2,8,2,20,33 };
int result[NUM];//记录CPU结果
int *d_arrayA, *d_arrayB,*d_result;
int nBytes=NUM * sizeof(int);//注意拷贝的是字节数,不是个数
CHECK(cudaMalloc((int **)&d_arrayA, nBytes));//如果觉得CHECK比较烦人,而你不认为这个函数会出错,那么删掉又何妨
CHECK(cudaMalloc((int **)&d_arrayB, nBytes));//注意申请GPU内存的方法
CHECK(cudaMalloc((int **)&d_result, nBytes));
CHECK(cudaMemcpy(d_arrayA, arrayA, nBytes, cudaMemcpyHostToDevice));//注意拷贝的方法
CHECK(cudaMemcpy(d_arrayB, arrayB, nBytes, cudaMemcpyHostToDevice));
int thd_num = 4;
dim3 block(thd_num);//block与grid的定义,结果为(4,1,1),即每个内存块有线程4个
dim3 grid((NUM + thd_num -1)/thd_num);//结果为(3,1,1),即内存块为3个
sumArrayOnGpu << <grid, block >> > (d_arrayA,d_arrayB,d_result);//内核函数
CHECK(cudaMemcpy(result, d_result, nBytes, cudaMemcpyDeviceToHost));
printf("计算结果:\n");
for (int i = 0; i < NUM; i++)
printf(" %d",result[i]);
printf("\n");
cudaFree(d_arrayA);//回收GPU内存,一般申请时立马写回收函数,防止忘记导致内存泄露
cudaFree(d_arrayB);
cudaFree(d_result);
cudaDeviceReset();//GPU恢复
return 0;
}