并行模式:稀疏矩阵-向量乘法
介绍并行算法中的压缩与规格化
背景
稀疏矩阵是很多元素是 0 的矩阵。下图是一个简单地例子。

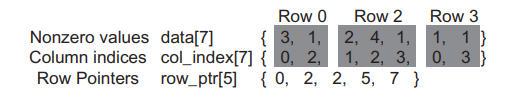
利用稀疏行压缩格式保存稀疏矩阵时不保存 0 元素。数组 data[ ] 保存非零元素。另外,还需要两个辅助数组来保留原本矩阵的结构。第一个是列索引数组 col_index[ ],这个数组记录原矩阵中非零元的纵向索引。第二个数组 row_ptr 记录了原矩阵每行的非零元素在数组 data[ ] 中的起始位置,元素个数比行数多一,多出来的元素往往用来作为行结束的标志。上面矩阵的 CSR 存储格式如下图所示:
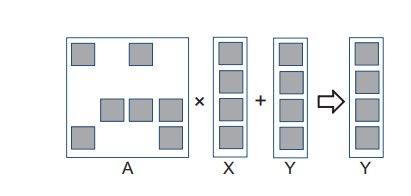
(五)中讨论过,矩阵通常用来解决形如 A × X + Y = 0 A \times X+Y=0 A×X+Y=0 的 N 元 N 次方程组,其中 A 是 N × N N \times N N×N 的矩阵, X 是 N 元向量,Y 是一个 N 维的常量向量。这个方程的直观解是 X = A − 1 × ( − Y ) X = A^{-1} \times (-Y) X=A−1×(−Y),还可以用高斯消元法。在使用稀疏矩阵的条件下,这两个方法都变得不直观,而且逆矩阵中往往会增加很多非零元,使逆稀疏矩阵变得很大。
稀疏线性方程组一般用迭代法更好。若稀疏矩阵 A 是正定矩阵(即对于属于 R n R^n Rn 的非零向量 x,都有 x T A x > 0 x^TAx>0 xTAx>0),使用共轭梯度法来迭代的求解线性方程组会得到一个收敛解。过程就是初始化一个解 X,计算 A × X + Y A \times X + Y A×X+Y,看结果是否接近 0,否则用梯度向量公式调整 X,接着用这个调整过的 X 进行下一次迭代。每次迭代产生的 Y 参与下一轮迭代计算。
串行实现 A × X + Y A \times X + Y A×X+Y代码如下:
for(int row = 0; row < num_rows; row++){
float dot = 0;
//row_start 与 row_end共同确定属于这一行的data元素的范围
int row_start = row_ptr[row], row_end = row_ptr[row + 1];
for(int elem = row_start; elem < row_end; elem++){
/*通过elem访问矩阵元素data[elem] 与 该元素的列索引 col_index[elem],
并通过列索引访问向量x元素。*/
dot += data[elem] * X[col_index[elem]];
}
y[row] += dot;
}
使用 CSR 格式的并行 SpMV
稀疏矩阵每一行的点积运算都与其他行无关,通过将上面代码的外层循环的每次迭代分给一个线程,就得到了 SPMV 的 kernel:
__global__ void SpMV_CSR(int num_rows, float *data, int *col_index, int *row_ptr, float *x, float *y)
{
int row = threadIdx.x + blockDim.x * blockIdx.x;
if (row < num_rows)
{
int row_start = row_ptr[row], row_end = row_ptr[row + 1];
float dot = 0;
for (int elem = row_start; elem < row_end; elem++)
{
dot += data[elem] * x[col_index[elem]];
}
y[row] += dot;
}
}
这个 kernel 与上面的串行代码几乎一样,也很简单,但是它有两个缺点:
- 不能合并访存,不能有效利用存储器带宽。
- 所有 warp 都有控制流分支。每个线程执行循环的次数由分配给那一行中元素的数量,数量很可能不同,就会造成控制流分支。
填充与转置
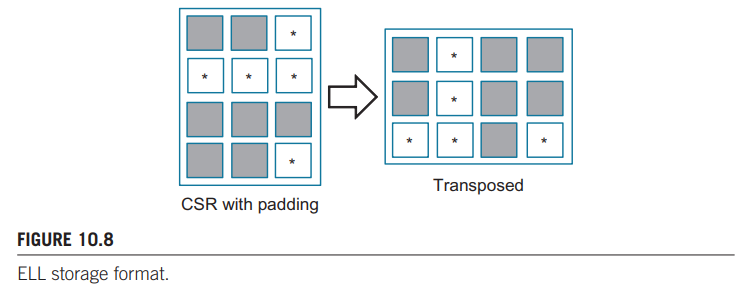
无法合并访存和控制分支的问题可以通过数据填充和矩阵转置来解决。ELL 存储格式使用了这种思想。根据 CSR 格式,先确定哪一行非 0 元素最多,然后在其他非零元后加 0 元素,让他们的行长与最长行一样。下图左侧图片就是上面所用实例稀疏矩阵填充 0 后的的结构。
然后对其转置,那么每行存储的元素就是转置前矩阵的一列,所有线程每次迭代访问相邻的内存位置,这样就可以达到合并访存的目的。又因为每个线程需要循环访问的元素个数相同,也就不会出现控制流分支的问题。
同样 col_index 也要用相同方法填充转置:
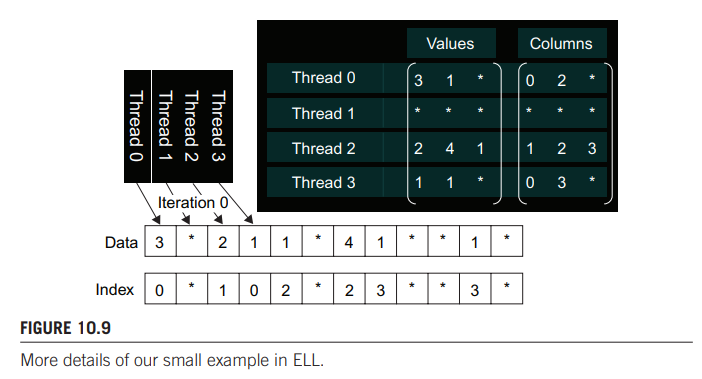
通过上图可以设计出 kernel:
__global__ void SpMV_ELL(int num_rows, int total_elems, float *data, int *col_index, float *x, float *y){
int row = threadIdx.x + blockIdx.x * blockDim.x;
if(row < num_rows){
float dot = 0;
for(int i = row; i < num_elems; i+=num_rows){
dot += data[i] * y[col_index[i]];
}
y[row] = dot;
}
}
其中,num_rows 是原矩阵的行数,total_elems 是填充后矩阵的元素个数。
使用混合方法来控制填充
ELL 格式的填充元素过多的问世是因为有一行或几行大量非 0 元素。如果将这几行中的元素“拿走”一些,就可以减少 ELL 格式中填充元素的数量。为此可以使用协调(coordinate,COO)格式。
如下图所示,COO 格式使用 col_index 和 row_index 辅助 data 数组来对稀疏矩阵进行存储。

混合方法就是将含有大量非 0 元素的行中取出部分元素放在 COO格式中。用 CSR 或 ELL 格式对其余元素进行 SpMV 操作。然后再用 SpMV/COO 来计算存储在 COO 中的元素。
在设备端使用 ELL 格式计算完后再传回主机端,利用串行 SpMV/COO 计算后加到 y 上就能得到正确的结果。使用串行COO可以利用 CPU 的大容量高速缓存。
串行COO:
//num_elem 是COO格式中元素的数目
for(int i = 0;i < num_elem;row++)
y[row_index[i]] += data[i] * x[col_index[i]];
或者直接在设备端利用原子加操作对 COO 格式计算并加到 y 上。
kernel COO:
__global__ void COO_kernel(int num_elem, float * y, float *data, int *row_index, int *col_index){
int i = threadIdx.x + blockDim.x * blockId.x;
if(i < num_elem){
atomicAdd(&(y[row_index[i]]), data[i]*x[col_index[i]]);
}
}
通过排序和划分来规则化
学到这一节有点把持不住了(学不会了),后面学会了再更。