第四章 数据并行执行模型
《大规模并行处理器编程实战》学习,其他章节关注专栏 CUDA C
CUDA C 编程友情链接:
- 第三章 CUDA 简介-CUDA C编程向量加法
- 第四章 CUDA数据并行执行模型
- 第五章 CUDA 存储器
- 第六章 CUDA性能优化(内附原书链接)
- 核函数:CUDA编程入门(一)-以图片运算看线程的组织和核函数的使用
- 拓展:CUDA卷积计算及其优化——以一维卷积为例
线程组成线程块,线程块组成线程网格,线程网格就是kernel。一个kernel中的所有线程都执行相同的代码,区别在于不同的线程属于不同的块(有不同的blockIdx),拥有其在块中的唯一位置(threadIdx),因此每个线程在kernel中有唯一的坐标,访问的数据可以被独立控制。
相同的执行过程+不同的数据来源=并行的数据处理
4.1 CUDA 线程组织
网格中的线程块,块中的线程,都是三维位置的。

在组织时也可以动态规定kernel的大小,由n控制,在addKernel时根据n的大小被确定。

快捷启动一维网格和线程:

具体实例:

注意,dimBlock(2,2,1)指的是一个网格中的块是221结构。dimGrid指一个块中的线程是16*16的
4.2 线程与多维数据的映射
根据数据的形式,选择合适的线程组织。图片 = 二维等等。
一个线程块1616,对于7664的图片,则需要76/16 * 64/16 = 5*4个线程块。n,m表示图片的x,y的最大值;d_Pin/d_Pout是图片数据的源地址和目的地址指针,则:


如果要进行三维的位置定位,则需要额外加上空间z信息:

4.3 矩阵乘法
在图片处理时,线程对应待处理的像素点(源数据),对每个像素点进行操作,得到并行过程。而在矩阵乘法中,线程对应目的矩阵的数值(目的数据),对每个待计算的矩阵值Vi,j进行相同的 ∑ d i , k 1 ∗ d k , j 2 \sum{d^1_{i,k}*d^2_{k,j}} ∑di,k1∗dk,j2,从而达到并行的效果。

具体实现如:

4.4 线程同步和透明的可扩展性
_syncthreads() 栅栏同步(即同一个线程块中的快的等慢的,两个)
栅栏死锁:

不同的线程块间不能栅栏同步,可以任意顺序执行。
透明的可扩展性:

4.5 线程块的资源分配
执行资源被组织成多核流处理器(Streaming Multiprocessor, SM)。多个线程块会被分配到一个SM上,每个设备对一个SM上的线程块也有限制,比如一个SM允许64个线程,和2个块,则SM只能分配2块包括32个线程的线程块,不能分配4个包含16分线程的线程块。
4.6 查询设备属性

查询所有设备的属性

查询对应的其他参数

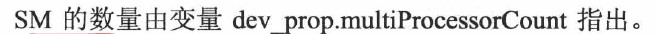
4.7 线程调度和容许时延
线程块一旦分配给SM,则会被划分为由32个线程组成的Warp单元。Warp是SM中的线程调度单元。
SM按照单指令多数据(Single Instruction Multiple Data, SIMD)模式执行一个 warp 的所有线程。任何时刻,warp 中的所有线程都只能取一条指令执行。
一个SM包含多个流处理器(Streaming Processor, SP),SP是真正执行指令的部件。一般情况,SM中的SP少于分配到的线程数目,SM中的硬件只执行所有warp的一部分。当SM被分配多个warp时,虽然每个时刻只执行一部分,但是SM会将需要“长延迟”的warp指令放在一边,执行短延迟的指令,从而不浪费硬件。这种利用其他线程的执行来覆盖延迟时间的机制被称为“容许延迟”或“延迟隐藏”。
这也是多warp被送入一个SM的原因,即使SP少于warp或线程数量。
延迟隐藏”**。
这也是多warp被送入一个SM的原因,即使SP少于warp或线程数量。