什么是并行规约
并行归约(Reduction)是一种很基础的并行算法,简单来说,我们有N个输入数据,使用一个符合结合律的二元操作符作用其上,最终生成1个结果。
并行规约的适用对象
数据特点:
(1)对于数据集中的元素没有顺序要求。
(2)可将数据分为若干小集合,每个线程处理一个集合。
例如:求最大值、求最小值、求和、求乘等操作。
未优化并行规约
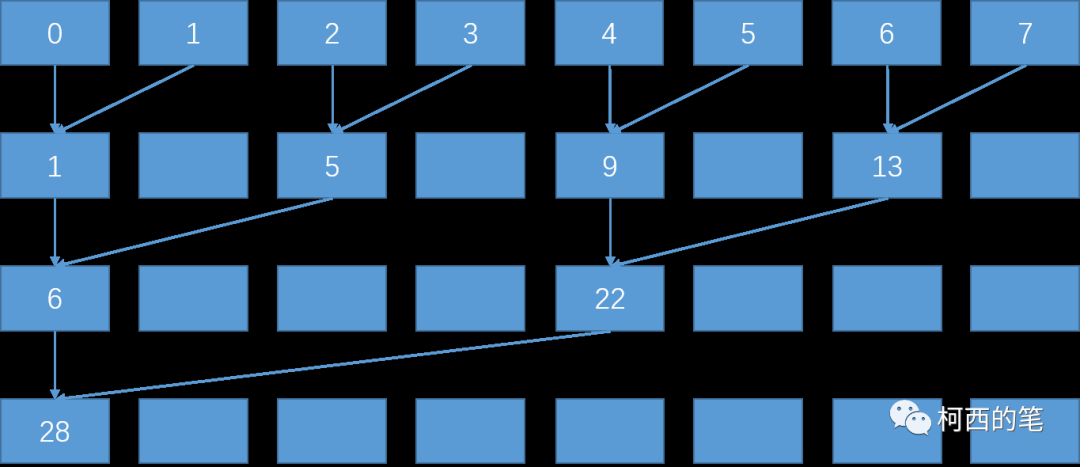
首先开辟一个8个int的存储空间,如下图第一行所示。将相邻的两个数相加,结果写入第一个数的存储空间内。第二轮迭代时我们再将第一次的结果两两相加得出下一级结果,一直重复这个过程最后直到我们得到最终的结果。相比于串行计算时间复杂度由O(N)变为O(logN)。(可以缩短计算时间,但是数据量要在几十万个以上,否则不一定会有串行求和快)。
//相当于计算每个block结果然后返回
__global__ void Reducetion(int* in, int* outs, int sizes)
{
int tid = threadIdx.x;
//boundary check
if (tid >= sizes) return;
int myid = blockIdx.x * blockDim.x + threadIdx.x;
//in-place reduction in global memory
for (int stride = 1; stride < blockDim.x; stride *= 2)
{
if ((tid % (2 * stride)) == 0)
{
in[myid] += in[myid + stride];
}
__syncthreads();
}
if (tid == 0)
outs[blockIdx.x] = in[myid];
}
int main()
{
int allnum = 8;
int* data = new int[allnum];
for (int i = 0; i < allnum; i++)
{
data[i] = i;
}
cudaError_t cudaStatus;
bool label = true;
//设置cuda device
cudaStatus = cudaSetDevice(0);
if (cudaStatus != cudaSuccess)
{
cout << "cudaSetDevice failed!" << endl;
label = false;
}
//定义grid和block的维度(形状)
dim3 threadsPerBlock(1024, 1);//[x,y,z]
dim3 blocksPerGrid((allnum + threadsPerBlock.x - 1) / threadsPerBlock.x, 1);
//申请指针并指向它指向GPU空降
int* InGpu = nullptr;
int* OutGpu = nullptr;
cudaStatus = cudaMalloc((void**)&InGpu, sizeof(int) * allnum);
if (cudaStatus != cudaSuccess)
{
cout << "cudaMalloc InGpu failed!" << endl;
label = false;
}
cudaStatus = cudaMalloc((void**)&OutGpu, sizeof(int) * blocksPerGrid.x);
if (cudaStatus != cudaSuccess)
{
cout << "cudaMalloc OutGpu failed!" << endl;
label = false;
}
//将数据从cpu传输到gpu
cudaStatus = cudaMemcpy(InGpu, data, sizeof(int) * allnum, cudaMemcpyHostToDevice);
if (cudaStatus != cudaSuccess)
{
cout << "cudaMemcpy InGpu failed!" << endl;
label = false;
}
//调用在gpu上运行的核函数
Reducetion << <blocksPerGrid, threadsPerBlock>> > (InGpu, OutGpu, allnum);
cudaStatus = cudaGetLastError();
if (cudaStatus != cudaSuccess)
{
cout << "addKernel launch failed:" << cudaGetErrorString(cudaStatus) << endl;
label = false;
}
cudaStatus = cudaDeviceSynchronize();
if (cudaStatus != cudaSuccess)
{
cout << "cudaDeviceSynchronize failed:" << cudaGetErrorString(cudaStatus) << endl;
label = false;
}
//将计算结果传回cpu内存
int* outs = new int[blocksPerGrid.x];
cudaStatus = cudaMemcpy(outs, OutGpu, sizeof(int) * blocksPerGrid.x, cudaMemcpyDeviceToHost);
if (cudaStatus != cudaSuccess)
{
cout << "cudaMemcpy OutGpu failed!" << endl;
label = false;
}
//释放gpu内存空间
cudaFree(InGpu);
cudaFree(OutGpu);
cudaDeviceReset();
for (int i = 0; i < blocksPerGrid.x; i++)
{
cout << outs[i] << endl;
}
cout << "柯西的笔" << endl;
return 0;
}仔细观察后,会发现第一轮计算中只有一半的线程是活跃的,而且每进行一轮计算后,活跃线程的数量会减少一半,但是整个线程束还是会被调用。由于硬件设计,这种访问方式会影响效率。
优化并行规约
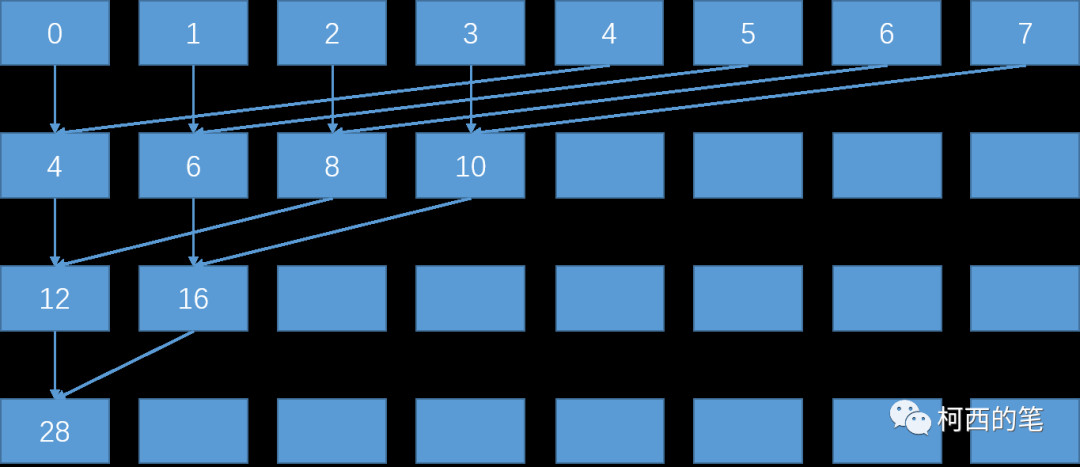
修改内存访问方式,下图所示:
__global__ void Reduction2(int* in, int* outs, int sizes)
{
unsigned int tid = threadIdx.x;
unsigned idx = blockIdx.x * blockDim.x + threadIdx.x;
if (idx >= sizes)
return;
//in-place reduction in global memory
for (int stride = blockDim.x / 2; stride > 0; stride >>= 1)//右移相当于/2
{
if (tid < stride)
{
in[idx] += in[idx + stride];
}
__syncthreads();
}
if (tid == 0)
outs[blockIdx.x] = in[idx];
} 优化内存访问方式可以显著提升程序的运行速度,特别是要尽量使用联合式内存访问和存储。此外,使用共享内存技术可以进一步提高程序的性能。相比于未缓存的全局内存,共享内存的访问延迟要低大约100倍,因此共享内存也很珍贵,每块显卡只有很少的数量可用。然而,如何充分利用共享内存是对工程师技术水平的考验。
共享内存并行规约
当线程之间共享数据时,我们需要小心避免争用情况(race conditions),因为虽然块中的线程逻辑上是并行运行的 ,但并非所有线程都可以同时执行 。为了保证并行线程协作时的正确结果,必须同步线程。CUDA 提供了__syncthreads()。__shared__指定说明符在 CUDA C / C ++设备代码中声明共享内存。
__global__ void Reduction2_share(int* in, int* outs, int sizes)
{
extern __shared__ int sharem[];
unsigned int tid = threadIdx.x;
unsigned idx = blockIdx.x * blockDim.x + threadIdx.x;
sharem[tid] = in[idx];
__syncthreads(); //保证 block 内的所有线程都已经运行到调用__syncthreads()的位置
for (int stride = blockDim.x / 2; stride > 0; stride >>= 1)//右移相当于/2
{
if (tid < stride)
{
sharem[tid] += sharem[tid + stride];
}
__syncthreads();
}
if (tid == 0)
outs[blockIdx.x] = sharem[0];
}本例中当编译时共享内存的数量未知时,在这种情况下,必须使用可选的第三个执行配置参数指定每个线程块的共享内存分配大小(以字节为单位),如下所示:
Reduction2_share <<<blocksPerGrid, threadsPerBlock ,1024*sizeof(int)>>> (InGpu, OutGpu, allnum);小结
CUDA并行规约优化可以显著提高并行程序的性能,它通过将数据分组以减少全局内存访问并使用共享内存加速计算来实现。此外,使用适当的线程块大小和优化共享内存访问模式也可以进一步提高性能。
参考资料
https://link.zhihu.com/?target=https%3A//developer.download.nvidia.cn/assets/cuda/files/reduction.pdf