并行模式:直方图计算
介绍原子操作和私有化
前面讲的几个并行模式都是将计算元素的任务分配到各各线程,线程之间不会相互干扰。但在实践中,很多并行计算模式的输出会受到其他线程的影响,并行直方图计算就是其中的一个例子,它的输出结果可能会被所有线程修改。因此,在线程更新输出元素时,必须协调线程之间的关系。下面将介绍一种基线方法,它使用原子操作来序列化对每个元素的更新,但基线方法的效率很低。此外还有一种高效的私有化方法,可以显著提高执行速度。
背景
直方图以连续的数值间隔显示数据出现的频率。在最常见的直方图形式中,值区间沿横轴绘制,每个区间中数据项的频率表示为从横轴上升的矩形(或条形图)的高度。比如大规模并行处理器的英文:“programming massively parallel processors” 的字母统计如下图:
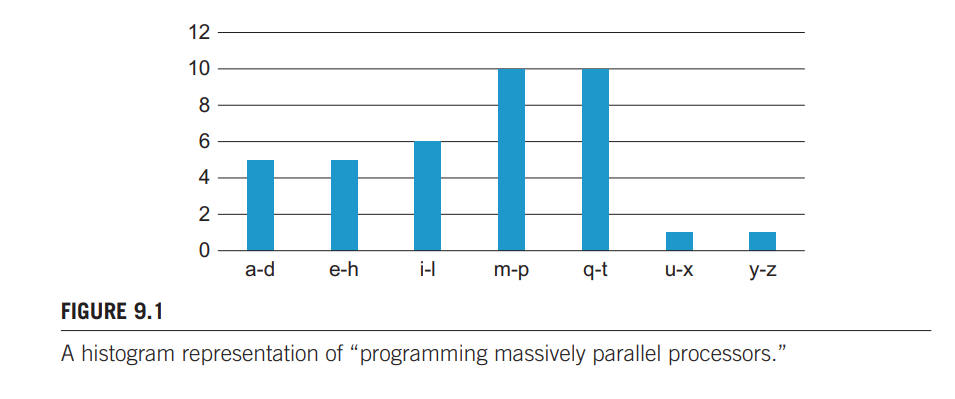
许多领域是靠直方图汇总数据集来做数据分析,比如计算机视觉,不同物体在直方图上的表现是不一样的。将图像分割后分析这些子区域的直方图,就可以大致判别图像中的物体对象。
可以使用下面的顺序代码实现字符串的直方图统计:
sequential_histogram(char *data, int length, int *histo){
for(int i = 0;i < length;i++){
int alphabet_position = data[i]-'a';
if(alphabet_potition >= 0 && alphabet_position < 26){
histo[alphabet_position/4]++;
}
}
}
由于现代 CPU L1缓存最少有几 KB,所以对 histo 数组的访问几乎全部都能命中高速缓存;但是对 data 的访问就会受到读取 DRAM 而受到限制。所以这段代码性能的限制主要来自对 data 的访问。
使用原子操作
一个直观并行统计字符文本的方法是,将一个数组分段,一个线程处理一段。但这种方法会遇到冲突,比如如下这种情况:
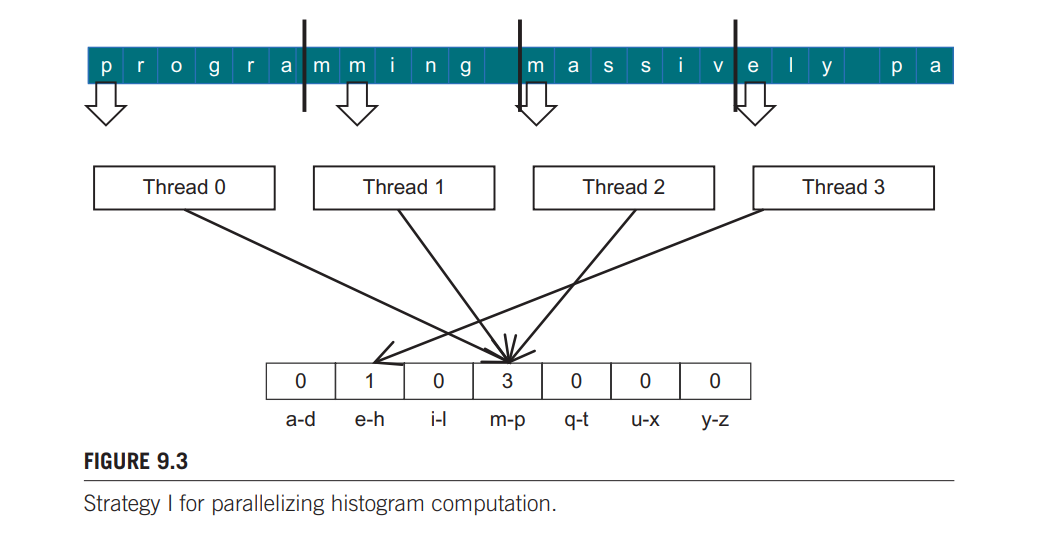
在第一轮循环中,线程0、1、2都会使 m-p 这个计数器加 1,这时候就发生冲突了,因为 histo 数组中元素的更新需要经过 3 个阶段:读-修改-写。可能 3 个线程同时读出 m-p 这个计数器,更新后写回,那么该计数器中的值就是 1,并不是 3。这就被称作紊乱情况。下图详细具体展示了这种情况:
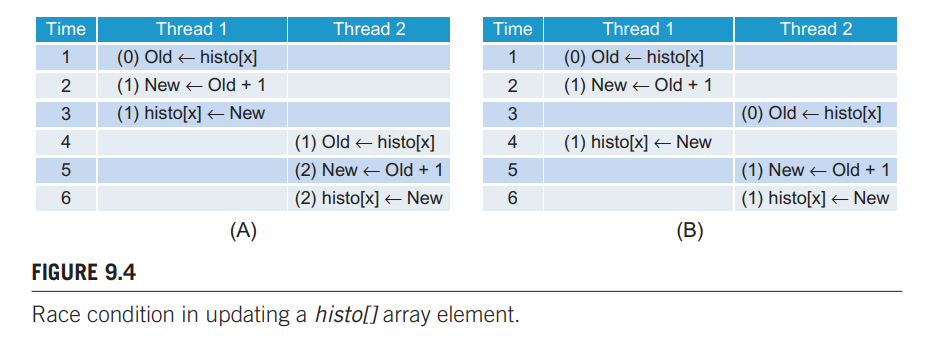
括号内是 histo[x] 的值。A 图的设想中,线程一的读-改-写连续进行,接着是线程二,那么最后的计算结果就是正确的。B 图的设想中,线程二在线程一写之前读取了 histo[x] 的值,线程一写后线程二再写,最后相当于线程一没写,结果是 1,计算错误。
下图类似:
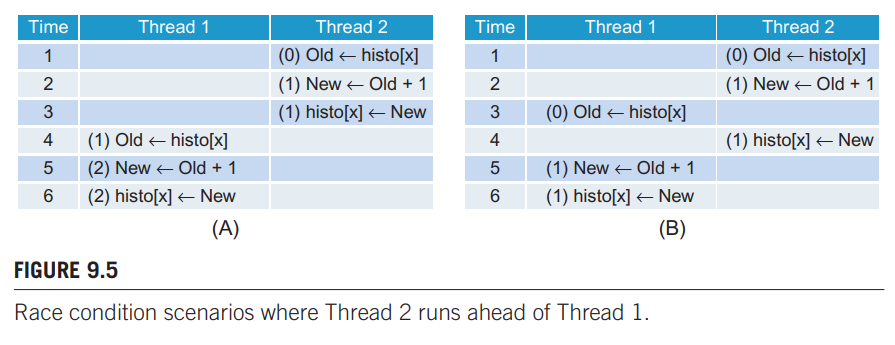
所以我们需要一个时间约束,来防止上两图 B 中发生的线程交错。通过原子操作可以强制执行时间约束。内存位置上的原子操作就是一个读-改-写操作发生在一个内存位置上时,不允许其他读改写操作重叠进行,也就是读-改-写操作是一体的,所以这种方法叫做原子操作。当一个读-改-写操作完成后,其他操作才能继续。另外,原子操作并未规定线程执行的先后,上两图的 A 图情况都有可能发生。
使用如下的内建函数可以执行原子加操作。
int atomicAdd(int *address, int val);
atomicAdd 接收两个参数,address 是指向 32 位字的地址,这个字可以在全局存储器中也可以在共享存储器中;val 是要加的数。将 address 指向的字加上 val 后,将新值写到同样的地址上,并返回地址 address 上原来的旧值。
代码如下:
#include<cuda.h>
#include<stdio.h>
#include<stdlib.h>
#define BLOCK_SIZE 16
#define HISTO_SIZE 7
__global__ void histo_kernel(unsigned char *buffer, long size, unsigned int *histo){
int i = threadIdx.x + blockIdx.x * blockDim.x;
int section_size = (size - 1)/(blockDim.x * gridDim.x) + 1;
int start = i*section_size;
//every threads handle section_size consecutive elements, may except the final thread.
for(int k = 0;k < section_size;k++){
//判断要处理的元素是否超过buffer的长度
if(start+k < size){
int alphabet_position = buffer[start+k] - 'a';
//判断是否是小写字母
if(alphabet_position >= 0 && alphabet_position < 26)
//使用atomicAdd进行原子加法,这里是最重要的
atomicAdd(&(histo[alphabet_position/4]), 1);
}
}
}
void histogram(unsigned char *arr, long n, unsigned int * histo){
unsigned char *d_arr;
unsigned int *d_histo;
int size = n * sizeof(char);
cudaMalloc(&d_arr, size);
cudaMemcpy(d_arr, arr, size, cudaMemcpyHostToDevice);
cudaMalloc(&d_histo, HISTO_SIZE*sizeof(int));
histo_kernel<<<ceil((float)n/(BLOCK_SIZE)), BLOCK_SIZE>>>(d_arr, n, d_histo);
cudaMemcpy(histo, d_histo, HISTO_SIZE*sizeof(int), cudaMemcpyDeviceToHost);
cudaFree(d_arr);
cudaFree(d_histo);
}
int main(){
unsigned char arr[] = {
"i am happy today, because i wrote a csdn blog and get many likes"};
long n = 64;
unsigned int *histo = (unsigned int *)malloc(HISTO_SIZE*sizeof(int));
histogram(arr, n, histo);
for(int i = 0; i < HISTO_SIZE;i++){
printf("%d\n", histo[i]);
}
free(arr);
free(histo);
return 0;
}
字符串:"i am happy today, because i wrote a csdn blog and get many likes"的输出结果:

块分区与交错分区
上一个方法中,我们将buffer[]中的元素划分为连续的元素块,并将每个块分配给一个线程。这种分区被称为块分区。在CPU上,并行执行通常只涉及少量线程,块分区通常是最佳的执行策略,因为每个线程的顺序访问模式可以很好地利用缓存行。每从主存加载一个元素都会将其后面几个元素一起加载到高速缓存行中,后几次访问直接可以命中高速缓存。由于每个CPU缓存通常只支持少量线程,因此不同线程对缓存使用的干扰很小。
但是块分区应用于 GPU 时,因为对全局存储器的访问不能合并,所以程序的性能很大程度上制约于全局存储器的宽带。所以我们需要修改 buffer 数组的划分方式,达到同一个 warp 中访问连续位置的线程可以实现内存合并。
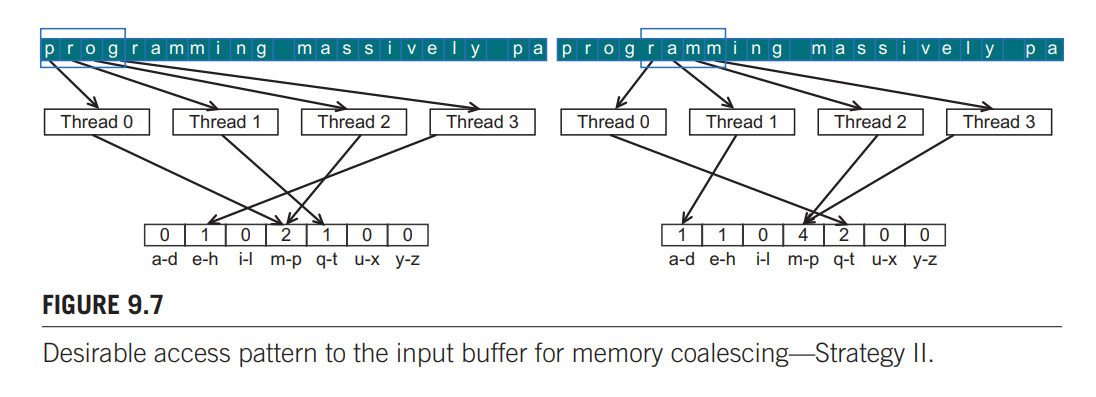
上图仅作为示例,有一个 block,一个 block 有 4 个线程。一般来说,所有线程第一次迭代处理 buffer 的前 blockDim.x * gridDim.x 个元素,第二次迭代处理紧接着的 blockDim.x * gridDim.x 个元素,以此类推。
kernel 函数如下:
__global__ void histo_kernel(unsigned char *buffer, long size, unsigned int *histo){
unsigned int tid = threadIdx.x + blockIdx.x * blockDim.x;
/*第一次循环线程索引作为数组索引,往后每次循环数组索引加 blockDim.x * gridDim.x,
每次循环处理 blockDim.x * gridDim.x 个元素。*/
for (unsigned int i = tid; i < size; i += blockDim.x * gridDim.x ) {
int alphabet_position = buffer[i] - 'a';
if(alphabet_position >= 0 && alphabet_position < 26)
atomicAdd(&(histo[alphabet_position/4]), 1);
}
}
这个交错分区的 kernel 就比块分区的 kernel 效率提升了几倍。
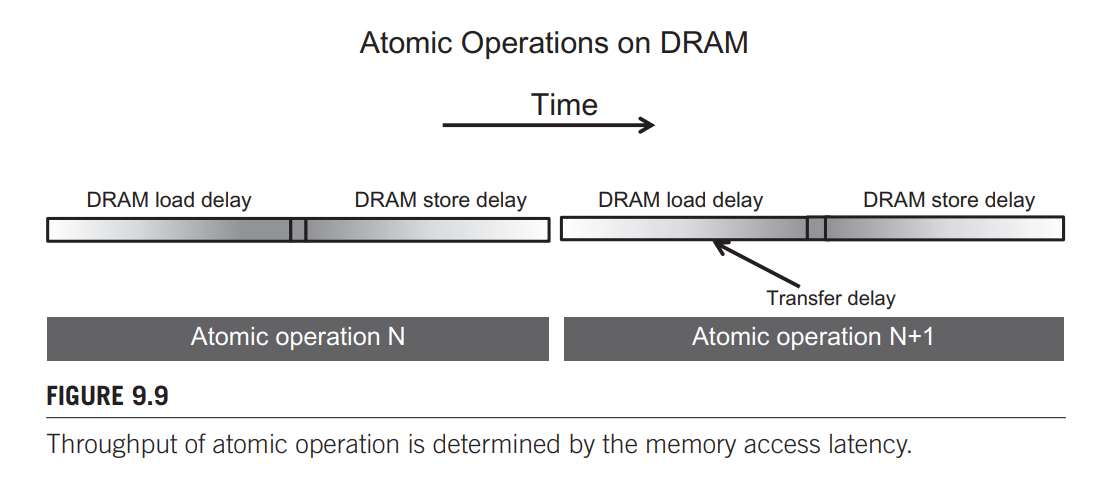
原子操作的延迟与吞吐量
如下图所示,对同一内存位置执行原子操作时只有一个操作在进行。每个原子操作的持续时间大约是一次内存读取的延迟时间(原子操作时间的左边部分)加上一次内存写入的延迟时间(原子操作时间的右边部分)。每个读-改-写操作的这些时间段的长度(通常为数百个时钟周期)是每个原子操作的最小时间量,从而限制了吞吐量或原子操作的执行速度。
缓存中的原子操作
上一节中指出在同一位置上执行原子操作时,长时间的内存访问会转化为低吞吐量。所以改善原子操作吞吐量的一个明显方法是减少对同一位置的访问延迟。缓存是减少内存访问延迟的主要工具。最近的gpu允许在最后一级缓存中执行原子操作,这在所有 SM 之间共享。在原子操作期间,如果更新的变量在最后一级缓存中找到,则在缓存中更新它。如果不能在上一级缓存中找到它,它就会触发缓存不命中,并被带到更新它的缓存中。由于原子操作更新的变量往往会被许多线程大量访问,所以这些变量一旦从DRAM中引入,就会保留在缓存中。由于对最后一层缓存的访问时间是几十个周期而不是几百个周期,因此只要允许在最后一层缓存中执行原子操作,其吞吐量至少可以提高一个数量级。然而,对于许多应用程序来说,改进的吞吐量仍然不够。
利用共享存储器——私有化
由于共享内存的访问延迟非常短,减少延迟就可以直接提高吞吐量。一种称为私有化的技术通常用于解决并行计算中的输出干扰问题。其思想是将高度竞争的输出数据结构复制到私有副本中,以便每个线程子集可以更新其私有副本。这样可以以更低的延迟访问私有副本。这些私有副本可以极大地提高更新数据结构的吞吐量。缺点是,在计算完成后,私有副本需要合并到原始数据结构中。必须仔细权衡竞争程度和合并成本。因此,在大规模并行系统中,私有化通常是针对线程子集而不是单个线程。
代码如下:
#include<cuda.h>
#include<stdio.h>
#include<stdlib.h>
#define BLOCK_SIZE 16
#define NUM_BINS 7
__global__ void histogram_privatized_kernel(unsigned char *buffer, unsigned int *histo, unsigned int num_elements){
unsigned int tid = blockIdx.x * blockDim.x + threadIdx.x;
extern __shared__ unsigned int histo_s[];
/*initialize private array in shared memory, each iteration initialize blockDim.x elements
in shared memory, until reaching the final element.*/
for(unsigned int binIdx = threadIdx.x; binIdx < NUM_BINS; binIdx +=blockDim.x) {
histo_s[binIdx] = 0u;
}
__syncthreads();
//histogram. similar to interleaved method, but store result in shared memory.
for (unsigned int i = tid; i < num_elements; i += blockDim.x*gridDim.x) {
int alphabet_position = buffer[i] - 'a';
if (alphabet_position >= 0 && alphabet_position < 26) atomicAdd(&(histo_s[alphabet_position/4]), 1);
}
__syncthreads();
//congragate results in shared memory to global memory.
for(unsigned int i = threadIdx.x; i < NUM_BINS;i += blockDim.x){
atomicAdd(&(histo[i]), histo_s[i]);
}
}
void histogram(unsigned char *arr, long n, unsigned int * histo){
unsigned char *d_arr;
unsigned int *d_histo;
int size = n * sizeof(char);
cudaMalloc(&d_arr, size);
cudaMemcpy(d_arr, arr, size, cudaMemcpyHostToDevice);
cudaMalloc(&d_histo, NUM_BINS*sizeof(int));
histogram_privatized_kernel<<<ceil((float)n/(BLOCK_SIZE)), BLOCK_SIZE, sizeof(int)*NUM_BINS>>>(d_arr, d_histo, n);
cudaMemcpy(histo, d_histo, NUM_BINS*sizeof(int), cudaMemcpyDeviceToHost);
cudaFree(d_arr);
cudaFree(d_histo);
}
int main(){
unsigned char arr[] = {
"i am happy today, because i wrote a csdn blog and get many likes"};
long n = 64;
unsigned int *histo = (unsigned int *)malloc(NUM_BINS*sizeof(int));
histogram(arr, n, histo);
for(int i = 0; i < NUM_BINS;i++){
printf("%d\n", histo[i]);
}
free(arr);
free(histo);
return 0;
}
私有化方法的 kernel 主要分为三个部分:
- 在每个线程块内分配私有的动态共享数组。
- 使用交错分区中的方法进行统计,并将统计结果存储在每个块内的共享数组中。
- 将所有块内的共享数组中的结果集中到一个全局数组中。
关于共享存储器中动态数组的原理与使用方法参考这篇博客
聚合原子操作
在图片处理中,像天空这种图片,有大量相同的元素,这会导致原子操作的拥挤,从而导致并行直方图的计算吞吐量降低。解决这种问题的方法就是将多次的共享存储器访问缩减到一次访问。
kernel如下
__global__ void histogram_privatized_kernel(unsigned char *buffer, unsigned int *histo, unsigned int num_elements){
unsigned int tid = blockIdx.x * blockDim.x + threadIdx.x;
//initialize private array in shared memory
extern __shared__ unsigned int histo_s[];
for(unsigned int binIdx = threadIdx.x; binIdx < NUM_BINS; binIdx +=blockDim.x) {
histo_s[binIdx] = 0u;
}
__syncthreads();
//histogram
int prev_index = -1;
unsigned int accumulator = 0;
unsigned int curr_index;
for(unsigned int i = tid; i < num_elements; i += blockDim.x*gridDim.x) {
int alphabet_position = buffer[i] - 'a';
if (alphabet_position >= 0 && alphabet_position < 26) {
curr_index = alphabet_position/4;
if(prev_index != curr_index){
if(accumulator > 0)
atomicAdd(&(histo_s[prev_index]), accumulator);
prev_index = curr_index;
accumulator = 1;
}else{
accumulator++;
}
}
}
if(accumulator > 0)
atomicAdd(&(histo_s[prev_index]), accumulator);
__syncthreads();
//congragate to global memory
for(unsigned int i = threadIdx.x; i < NUM_BINS;i += blockDim.x){
atomicAdd(&(histo[i]), histo_s[i]);
}
}
上面代码多维护了3个寄存器变量 curr_index, prev_index, accumulator。当某一线程接收到的元素与上一个元素相同时,即 curr_index 等于 prev_index,accumulator自增;不同时,则把 accumulator 加到 histo 数组的 prev_index 索引处,将 curr_index 赋给 prev_index,accumulator 赋 1。
这样,就可以在大量元素相同的情况下减少使用原子加操作的次数,从而提高了吞吐量。