(三)线程管理(重新整理,前见基础一)
1.前面我们提到过网格,一个内核函数启动产生的所有线程称为网格,同一网格内线程可共享相同的全局内存空间。
2.多个线程块则组成网格,同一线程块内的的线程可以通过同步或共享内存来实现协作。
3.最后就是线程了,每个线程具有唯一的标识,通过blockIdx和threadIdx来区分。
gridIdx.x/gridIdx.y/gridIdx.z 理解为某线程块在网络的三维坐标
blockIdx.x/blockIdx.y/blockIdx.z 理解为某线程在线程块的三维坐标
有了他们,就可以在网格当中准确定位某线程了。
如果有必要的话,可以获取网格的维度gridDim和线程块的维度blockDim,那么容易知道blockIdx肯定要小于或等于gridDim,同样threadIdx要小于或等于blockDim。
一般情况下,我们会将网格组织为二数数组,而线程块且组织为三维数组,以上均为dim3类型,默认情况下,各维索引均为1.
(四)编写核函数
核函数定义:__global__ void kernel_name(argument list)
注意这里有几个限制:
- 只能访问GPU内存
- 必须具有void返回类型
- 参数不支持可变数量的数组
- 不支持静态变量
- 显示异步行为
- 从CPU中调用,在计算能力为3的GPU中,也可以通过GPU调用
除此以外,还有2个限定符:
- __device__ int device_function_name(argument list),此类函数只能通过GPU调用
- __host__ int host_function_name(argument list),此类函数只能通过CPU调用,跟平时程序一样,也可以忽略__host__限定符。
这里限定符__device__和__host__可以一起使用,这样的话,函数既可以用CPU调用,也可以在GPU里调用。
(五)错误处理
一般CUDA函数都会返回一个错误值,如函数:
cudaError_t cudaMemcpy(void *dst,const void *src,size_t count,cudaMemcpyKind kind);
它返回的是一个错误码:cudaError_t error,错误码如果不熟悉的话,我们可以通过以下函数获得具体错误信息:
Char *cudaGetErrorString(cudaError_t error);
其中error==cudaSucess或error==0代表运行成功。
(六)确定核函数性能
核函数运行后,我们怎么知道它要跑多长时间呢?前面我们知道核函数与CPU主程序之间并不处于一个线程,所以CPU主程序在计时后,可能核函数还在跑,所以并不能通过以下程序获得运行时间:
clock_t start = clock();
Kernel_function << <grid, block >> >(argument list);
printf("%d seconds\n", double(clock() - start) / CLOCKS_PER_SEC);
而是要加入一个同步函数cudaDeviceSynchronize():
clock_t start=clock();
Kernel_function<<<grid,block>>>(argument list);
cudaDeviceSynchronize();
cout << double(clock()-start)/CLOCKS_PER_SEC<<”seconds”;这样CPU程序必须在内核函数运行完才开始统计时间,这个同步函数很有用,有时候,我们必须在内核函数操作完后,才能进行下一步操作,就要用到该函数。
之所以需要这个测试性能的函数,是因为GPU根据网格和线程块的不同配置,可能出现不同的运行时间,为了最优化函数,就得相互对比。
(七)用nvprof工具计时
当你编译好程序后,也可以使nvprof对程序的内核函数进行测试,这样就省去你写计时函数的麻烦,nvprof会列出程序内所有内核函数的性能,需要指出的是,同一个程序在不同的GPU中nvprof,得到的结果也会不一样,但总体来说,耗时多的函数还是多,耗时少的还是少,不过也会有例外。

不过话说回来,如果你不是在做非常底层的工作,而是在做某个项目的优化,那几毫秒的差距完全没必要纠结,毕竟相对CPU已经很快了是吧?
(八)组织并行线程
我们以二维数组的矩阵加法为例,了解线程的组织,那么它有以下三种方法进行:
- 由二维线程块构成二维网络
- 由一维线程块构成一维网络
- 由一维线程块构成二维网络
怎么理解这三种方法呢,我们一个一个来分析,假设我们计算矩阵A+B=C,它们均是(5,6)大小矩阵,注意这里5是列数(colunm number)、6是行数(row number),这里与其它软件定义可能不同。
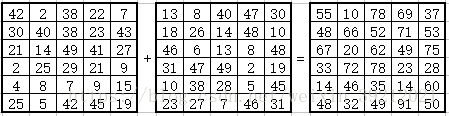
1.第一种方法,由二维线程块构成二维网格,即我们可以定义一个二维的网格和二维的线程块。
CPU主函数:
const int x = 5, y = 6;
dim3 grid(2, 2);
dim3 block((x + grid.x - 1) / grid.x, (y + grid.y - 1) / grid.y);
addKernel_grids << <grid, block >> >(dev_a, dev_b, dev_c, x, y);GPU内核函数:
__global__ void addKernel_grids(const int *a,const int *b,int *c,int x,int y)
{
int ix = threadIdx.x + blockIdx.x*blockDim.x;
int iy = threadIdx.y + blockIdx.y*blockDim.y;
if (ix < x && iy < y)
{
int index = iy*x + ix;
c[index] = a[index] + b[index];
}
}为何在内核函数里要有if (ix < x && iy < y)来做一判断呢,原因是grid(2,2)/block(3,3),从而使计算变成了6*6,即如下图:
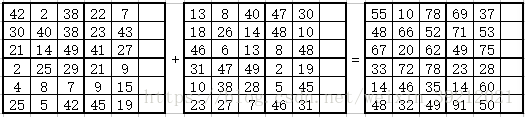
很明显,虽然GPU开了这么多线程数,但在GPU内存当中,并没有申请这么多内存,所以索引不到,因此我们要去掉空白区域。
2.第二种方法,由二维线程块构成一维网格,即我们可以定义一个一维的网格和一个二维线程块。
CPU主函数:
const int x=5,y=6;
dim3 grid(2);
dim3 block((x + grid.x - 1) / grid.x, y);
addKernel_grid1 << <grid, block >> >(dev_a, dev_b, dev_c, x, y);GPU内核函数:
__global__ void addKernel_grid1(const int *a, const int *b, int *c, int x, int y)
{
int ix = threadIdx.x + blockIdx.x*blockDim.x;
int iy = threadIdx.y;
if (ix < x)
{
int index = iy*x + ix;
c[index] = a[index] + b[index];
}
}这个时候,grid(2)/block(3,6),其关系如下图:

3.第三种方法,由一维线程块构成一维网格,即我们可以定义一个一维的网格和一个一维线程块。
CPU主函数:
dim3 grid(2);
dim3 block((x*y+grid.x-1)/grid.x);
addKernel_block1 << <grid, block >> >(dev_a, dev_b, dev_c, x, y);GPU内核函数:
__global__ void addKernel_block1(const int *a, const int *b, int *c, int x, int y)
{
int ix = threadIdx.x + blockIdx.x*blockDim.x;
if (ix < x*y)
{
c[ix] = a[ix] + b[ix];
}
}那这个时候,grid(2)/block(15),其关系图如下:

现将代码完整代码贴出:
#include "cuda_runtime.h"
#include "device_launch_parameters.h"
#include <stdlib.h>
#include <stdio.h>
#include<time.h>
const int x = 5, y = 6;
int calc_type = 3;
cudaError_t addWithCuda(int *c, const int *a, const int *b);
__global__ void addKernel_grids(const int *a,const int *b,int *c,int x,int y)
{
int ix = threadIdx.x + blockIdx.x*blockDim.x;
int iy = threadIdx.y + blockIdx.y*blockDim.y;
if (ix < x && iy < y)
{
int index = iy*x + ix;
c[index] = a[index] + b[index];
}
}
__global__ void addKernel_grid1(const int *a, const int *b, int *c, int x, int y)
{
int ix = threadIdx.x + blockIdx.x*blockDim.x;
int iy = threadIdx.y;
if (ix < x)
{
int index = iy*x + ix;
c[index] = a[index] + b[index];
}
}
__global__ void addKernel_block1(const int *a, const int *b, int *c, int x, int y)
{
int ix = threadIdx.x + blockIdx.x*blockDim.x;
if (ix < x*y)
{
c[ix] = a[ix] + b[ix];
}
}
void checkError(cudaError_t err)
{
if (err != cudaSuccess)
{
printf("error:%s\n",cudaGetErrorString(err));
exit(-1);
}
}
int main()
{
const int a[y*x] = { 42,2,38,22,7,30,40,38,23,43,21,14,49,41,27,2,25,29,21,9,4,8,7,9,15,25,5,42,45,19};
const int b[y*x] = { 13,8,40,47,30,18,26,14,48,10,46,6,13,8,48,31,47,49,2,19,10,38,28,5,45,23,27,7,46,31};
int c[y*x];
// Add vectors in parallel.
cudaError_t cudaStatus = addWithCuda(c, a, b);
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "addWithCuda failed!");
return 1;
}
for (int i = 0;i < y;i++)
{
for (int j = 0;j < x;j++)
{
printf("%d ",c[i*x+j]);
}
printf("\n");
}
// cudaDeviceReset must be called before exiting in order for profiling and
// tracing tools such as Nsight and Visual Profiler to show complete traces.
cudaStatus = cudaDeviceReset();
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "cudaDeviceReset failed!");
return 1;
}
return 0;
}
// Helper function for using CUDA to add vectors in parallel.
cudaError_t addWithCuda(int *c, const int *a, const int *b)
{
int *dev_a=NULL;
int *dev_b=NULL;
int *dev_c=NULL;
// Choose which GPU to run on, change this on a multi-GPU system.
checkError(cudaSetDevice(0));
// Allocate GPU buffers for three vectors (two input, one output) .
cudaMalloc((void **)&dev_a, x*y*sizeof(int));
cudaMalloc((void **)&dev_b, x*y*sizeof(int));
cudaMalloc((void **)&dev_c, x*y*sizeof(int));
cudaMemcpy(dev_a, a, x*y*sizeof(int), cudaMemcpyHostToDevice);
cudaMemcpy(dev_b, b, x*y*sizeof(int), cudaMemcpyHostToDevice);
//二维网格二维线程块
if (calc_type == 1)
{
dim3 grid(2, 2);
dim3 block((x + grid.x - 1) / grid.x, (y + grid.y - 1) / grid.y);
addKernel_grids << <grid, block >> >(dev_a, dev_b, dev_c, x, y);
}
//一维网格二维线程块
else if (calc_type == 2)
{
dim3 grid(2);
dim3 block((x + grid.x - 1) / grid.x, y);
addKernel_grid1 << <grid, block >> >(dev_a, dev_b, dev_c, x, y);
}
//一维网格一维线程块
else
{
dim3 grid(2);
dim3 block((x*y+grid.x-1)/grid.x);
addKernel_block1 << <grid, block >> >(dev_a, dev_b, dev_c, x, y);
}
cudaMemcpy(c,dev_c,x*y*sizeof(int),cudaMemcpyDeviceToHost);
cudaFree(dev_a);
cudaFree(dev_b);
cudaFree(dev_c);
return cudaSuccess;
}