前言:
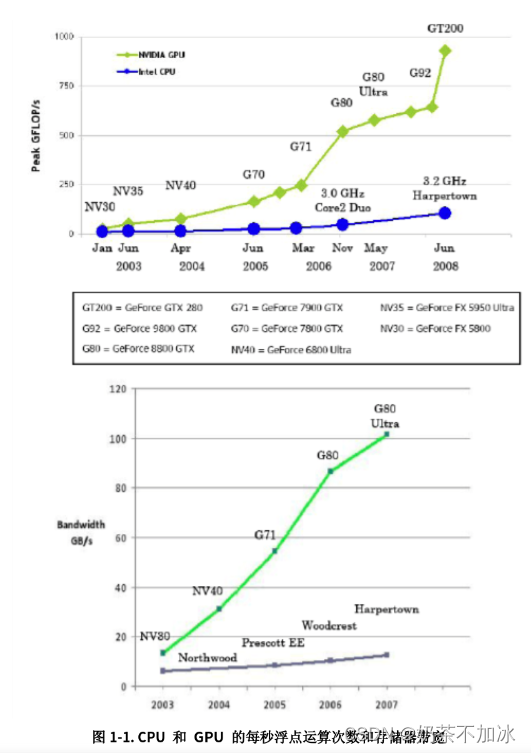
CUDA的全称是Computer Unified Device Architecture(计算机统一设备架构),它是NVIDIA在2007年推向市场的并行计算架构。CUDA作为NVIDIA图形处理器的通用计算引擎,提供给我们利用NVIDIA显卡进行GPGPU(General Purpose Graphics Process Unit)开发的全套工具。
1.GPU与CPU
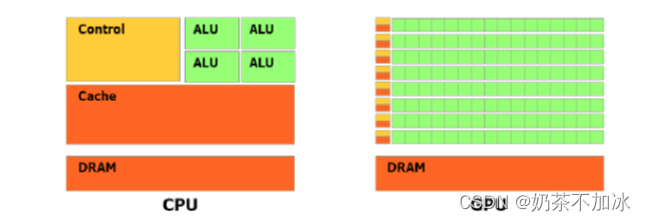
绿色是计算单元,橙红色是存储单元,橙黄色是控制单元
GPU是高度并行化,多线程,多核处理器。GPU的结构设计了更多的晶体管用于数据计算,而不是CPU的数据流缓存和流控制。
2.GPU的内存层次结构
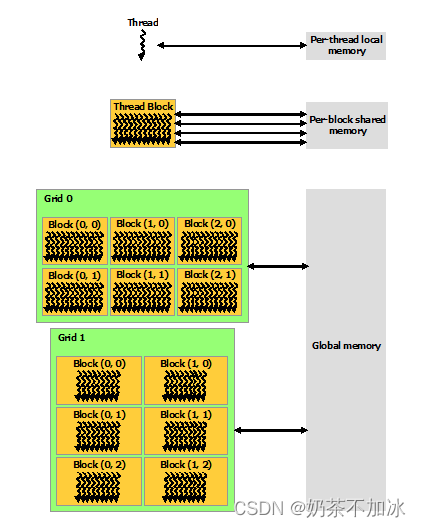
2.1硬件角度
每个线程thread都有自己的一份寄存器register和局部内存local memory。同一个线程块block中的每一个线程thread都共享一份share memory。所有的thread线程(包括不同block的thread)都共享一份全局global memory。不同的grid则有各自的global memory。
2.2 软件角度
设备端(device)-> grids -> 内核 ,可自定义大小
多核处理器(SM)-> Block -> 线程块 ,由线程组成
线程处理器(SP) ->Thread -> 线程, 最小单元
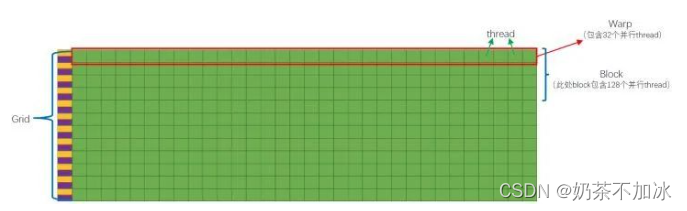
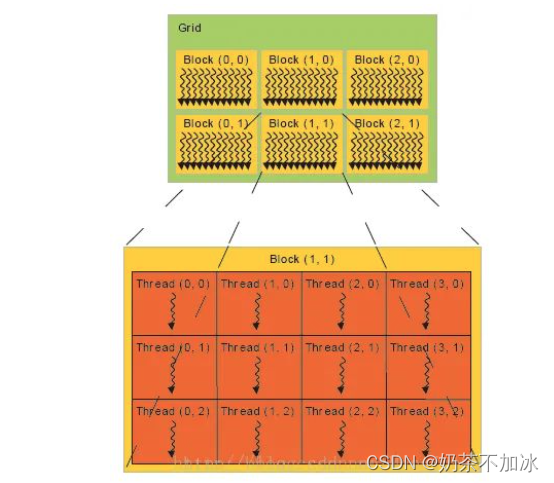
grids,blocks,thread三个变量之间的关系
3.CUDA软件体系
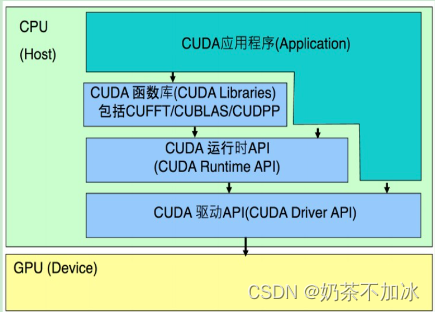
CUDA函数库(CUDA Library)
CUDA runtimeAPI(Runtime API)
CUDA驱动API(Driver API)
4.异步编程
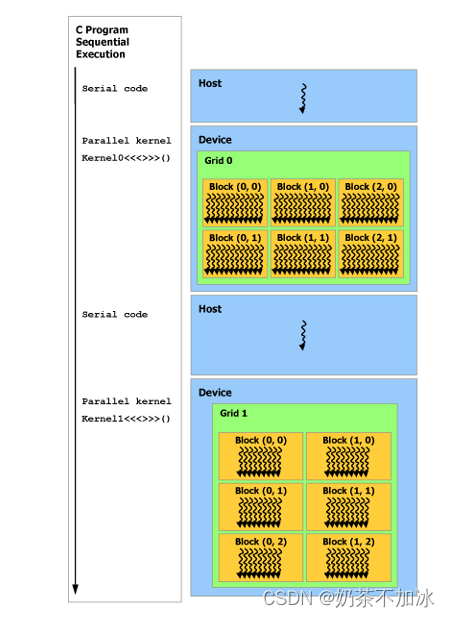
CUDA编程模型假定CUDA线程在物理上独立的设备(GPU)上执行,GPU设备作为运行程序的主机协处理器。如:内核部分在GPU上执行,而程序的其余部分在CPU上执行。
tips:串行代码在主机CPU上执行,而并行代码在设备GPU上执行
简单的 加法demo:
// Device code
global void VecAdd(float* A, float* B, float* C, int N)
{
int i = blockDim.x * blockIdx.x + threadIdx.x;
if (i < N)
C[i] = A[i] + B[i];
}
// Host code
int main()
{
int N = …;
size_t size = N * sizeof(float);
// Allocate input vectors h_A and h_B in host memory
float* h_A = (float*)malloc(size);
float* h_B = (float*)malloc(size);
float* h_C = (float*)malloc(size);
// Initialize input vectors
...
// Allocate vectors in device memory
float* d_A;
cudaMalloc(&d_A, size);
float* d_B;
cudaMalloc(&d_B, size);
float* d_C;
cudaMalloc(&d_C, size);
// Copy vectors from host memory to device memory
cudaMemcpy(d_A, h_A, size, cudaMemcpyHostToDevice);
cudaMemcpy(d_B, h_B, size, cudaMemcpyHostToDevice);
// Invoke kernel
int threadsPerBlock = 256;
int blocksPerGrid =
(N + threadsPerBlock - 1) / threadsPerBlock;
VecAdd<<<blocksPerGrid, threadsPerBlock>>>(d_A, d_B, d_C, N);
// Copy result from device memory to host memory
// h_C contains the result in host memory
cudaMemcpy(h_C, d_C, size, cudaMemcpyDeviceToHost);
// Free device memory
cudaFree(d_A);
cudaFree(d_B);
cudaFree(d_C);
// Free host memory
...
}
5.CUDA程序步骤
第一部分:从主机(host)端申请device memory,把要拷贝的内容从host memory拷贝到申请到的device memory中;
第二部分:设备(device)端的核函数对拷贝进来的东西进行计算,来得到和实现运算的结果,kernel就是指在GPU上运行的函数;
第三部分:把结果从device memory拷贝到申请的host memory中,并释放设备端的显存以及主机端的内存
6.应用程序编程接口
6.1 函数类型的限定符号
6.1.1 device
使用_device_限定符申明函数有下面特性:
在设备device上执行
仅可通过设备进行调用
6.1.2 global
使用_global_有下面特性:
在设备device上执行
仅可通过主机调用
3.1.3 host
使用_host_有下面特性:
在主机上执行
仅可通过主机调用
_host_限定符也可以与 _device_一起使用
6.1.4 限定符号的限制

6.2 变量类型的限定符
device

constant

shared

6.3 执行配置

6.4 内置变量
6.4.1 gridDim
网格的维度,数据类型为dim3(一种整形向量,用于指定维度的uint3)
6.4.2 blockIdx
网格内的线程块索引,数据类型为uint3
6.4.3 blockDim
块的维度,数据类型为dim3
6.4.4 threadIdx
线程的索引,数据类型为uint3

7.常用函数
1.cudaMalloc() – 申请显存(设备内存)
2.cudaMemcpy() – 设备(device)和主机(host)之间进行数据复制
3.cudaFree() – 设备内存释放(显存释放)
8.kernel 函数线程块与线程索引
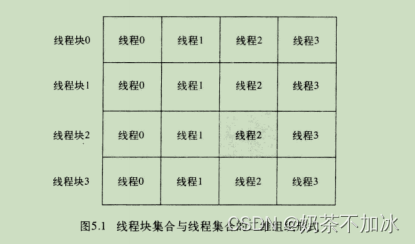
tid = threadIdx.x + blockIdx.x * blockDim.x; // 当前线程索引的起始位置
threadIdx为线程索引,blockIdx.x为线程块的索引,blockDim.x为线程块的大小(包含线程的数量)
tid += blockDim.x * gridDim.x;
每个线程计算完当前索引tid的任务后,我们再对索引进行递增,其中递增的步长为线程格中正在运行的线程数量
———————————————————————————————————————————————————————
1.pytorch 调用自定义CUDA算子的过程
1.首先是CUDA算子和对应的调用函数
2.然后是 torch.cpp函数建立pytorch与CUDA之间的联系,用pybind11封装
3.最后是用PyTorch的cpp扩展库进行编译和调用
https://godweiyang.com/2021/03/18/torch-cpp-cuda/