背景
前缀和(prefix sum)也叫扫描(scan),闭扫描(inclusive scan)操作对 n 元数组[x0, x1, x2, …, xn-1] 进行二元运算#,返回输出数组 [x0, (x0#x1),…, (x0#x1#x2# …# xn-1)]。开扫描(exclusive scan) 与闭扫描类似,返回数组 [0, x0, (x0#x1),…, (x0#x1#x2# …# xn-2)]。将闭扫描输出数组全部右移一位,第 0 个数组赋 0 即得到开扫描的输出数组。
闭扫描算法的串行实现:
void sequential_scan(float *x, float *y, int Max_i){
y[0] = x[0];
for(int i=1;i < Max_i;i++){
y[i] = y[i-1]+x[i];
}
}
也就是一个简单的动态规划。
简单并行扫描
下面是通过归约树实现的原地扫描算法:
- 在共享内存中声明数组XY,并将长度为 n 的 x 数组中的值赋给 XY 数组。
- 进行迭代,在第 n 次迭代时,后 n − 2 n − 1 n-2^{n-1} n−2n−1 个数分别加上它前面第 2 n − 1 2^{n-1} 2n−1个数。
- 当 2 n − 1 2^{n-1} 2n−1 大于n时,停止迭代。
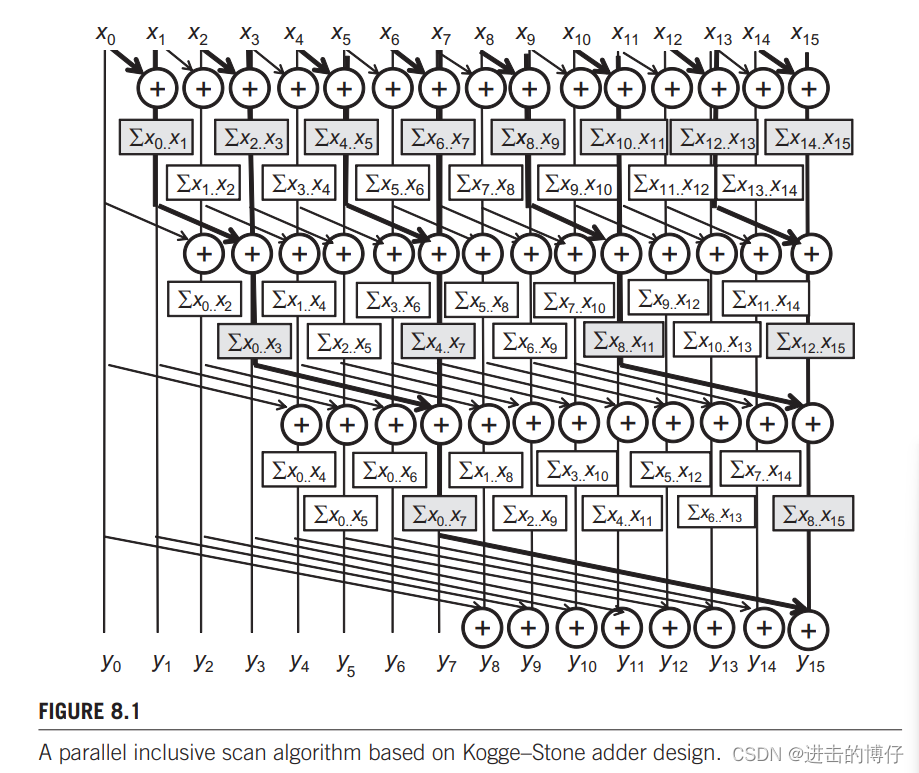
上面的算法处理元素的数量不能超过一个 block 的线程数。
代码:
#include<cuda.h>
#include<stdio.h>
#include<stdlib.h>
#define SECTION_SIZE 256
__global__ void work_inefficient_scan_kernel(float *X, int input_size){
__shared__ float XY[SECTION_SIZE];
int i = blockIdx.x*blockDim.x + threadIdx.x;
//将数组加载到共享寄存器。
if(i < input_size){
XY[threadIdx.x] = X[i];
}
//进行闭扫描
for(unsigned int stride = 1;stride <= threadIdx.x;stride*=2){
__syncthreads();
XY[threadIdx.x] += XY[threadIdx.x - stride];
}
__syncthreads();
X[i] = XY[threadIdx.x];
}
void test(float *A, int n){
float *d_A, *d_B;
int size = n * sizeof(float);
cudaMalloc(&d_A, size);
cudaMemcpy(d_A, A, size, cudaMemcpyHostToDevice);
//用SECTION_SIZE作为block大小启动kernel。
work_inefficient_scan_kernel<<<ceil((float)n/SECTION_SIZE), SECTION_SIZE>>>(d_A, n);
cudaMemcpy(A, d_A, size, cudaMemcpyDeviceToHost);
cudaFree(d_A);
}
int main(int argc, char **argv){
int n = atoi(argv[1]); //n 不能大于SECTION_SIZE
float *A = (float *)malloc(n * sizeof(float));
for(int i = 0; i < n;++i){
A[i] = 1.0;
}
test(A, n);
for(int i = 0;i < n; ++i){
printf("%f ", A[i]);
}
free(A);
return 0;
}
效率
现在我们来分析一下上面 kernel 的工作效率。所有线程将迭代 log(SECTION_SIZE) 步。每次迭代中不需要做加法的线程数量等于 stride ,所以我们可以这样计算算法完成的工作量:
∑ ( N − s t r i d e ) , f o r s t r i d e s 1 , 2 , 4 , . . . , N / 2 \sum(N-stride), for \, strides \, 1,2,4,...,N/2 ∑(N−stride),forstrides1,2,4,...,N/2
每一项的第一个部分和跨步无关,因此他们的和是: N × l o g 2 ( N ) N \times log_2(N) N×log2(N);第二部分类似等比数列,他们的和为 N − 1 N-1 N−1。所以加法操作的总数是: N × l o g 2 ( N ) − ( N − 1 ) N \times log_2(N)-(N-1) N×log2(N)−(N−1)
串行扫描算法完成的加法总数为 N − 1 N-1 N−1,串行并行不同 N 值的加法次数:
| N | 16 | 32 | 64 | 128 | 256 | 512 | 1024 |
|---|---|---|---|---|---|---|---|
| N − 1 N-1 N−1 | 15 | 31 | 63 | 127 | 255 | 51 | 1023 |
| N × l o g 2 ( N ) − ( N − 1 ) N \times log_2(N)-(N-1) N×log2(N)−(N−1) | 49 | 129 | 321 | 769 | 1793 | 4097 | 9217 |
元素个数为 1024 时,并行比串行多做了 9 倍的加法。随着 N 的增大,这个系数会继续增长。
高效的并行扫描
这个算法由两部分组成,第一部分是归约求和,第二部分是用倒置的树分发部分和。
把一个长度为 N 的数组归约求和(下图的上半部分),一般需要 (N/2) + (N/4) + … + 2 + 1 = N - 1 次操作。
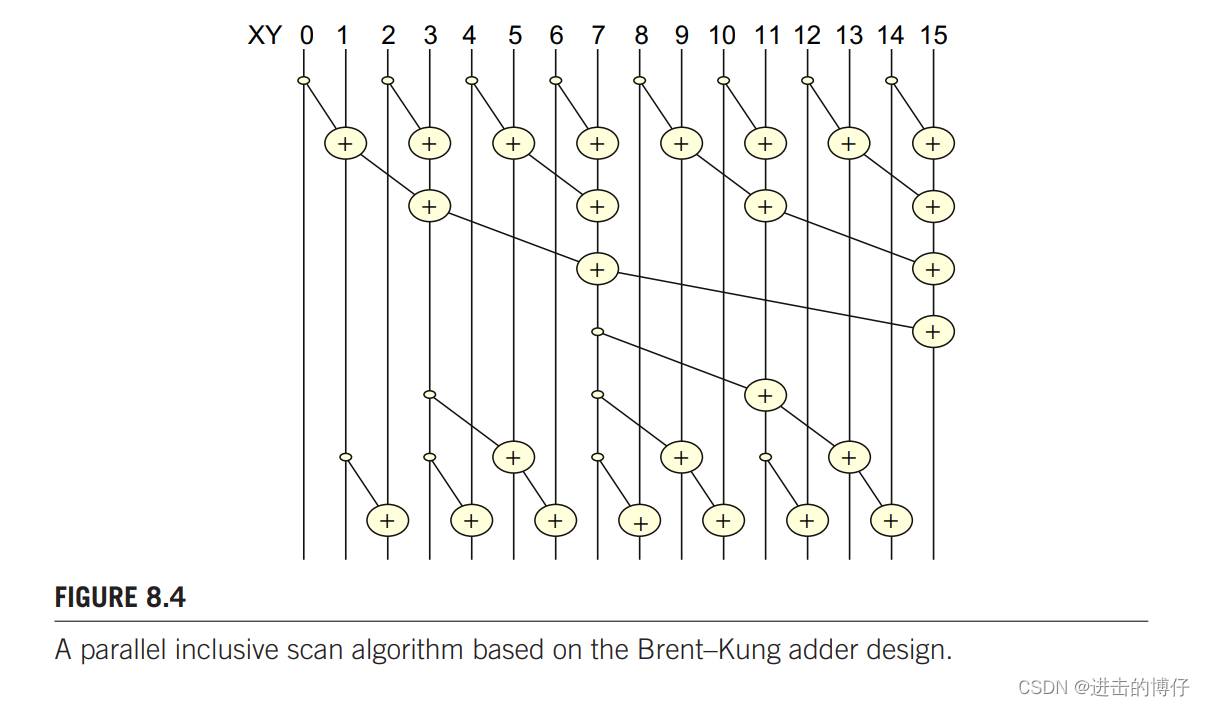
归约求和:
没有控制流分支的版本:
for(unsigned int stride = 1;stride <= blockDim.x;stride *= 2){
__syncthreads();
int index = (threadIdx.x + 1)*stride*2 - 1;
if(index < SECTION_SIZE)
XY[index] += XY[index - stride];
}
归约后数组中的值如下图的第一行:

从倒置树可以看出,第一次将 XY[7] 加到 XY[11] 上,第二次分别将 XY[3], XY[7], XY[11] 加到 XY[5] , XY[9], XY[13] 上,第三次除 XY[0] 偶数位元素加前面元素。
可以看出,相加的 stride 从 SECTION_SIZE/4 下降到 1。我们需要将位置为 stride 的倍数 - 1 的 XY 元素相加到相距一个 stride 位置上的元素上。具体代码如下:
for(unsigned int stride = SECTION_SIZE/4; stride > 0; stride /= 2){
__syncthreads();
int index = (threadIdx.x + 1)*stride*2 - 1;
if(index + stride < SECTION_SIZE)
XY[index + stride] += XY[index];
}
无论在归约阶段还是在分发阶段,线程数都没有超过 SECTION_SIZE/2。所以可以启动一个只有SECTION_SIZE/2 个线程的 block。因为一个 block 中可以有 1024 个线程,所以每个扫描部分中最多可以有 2048 个元素。所以一个线程就要加载 2 个元素。
完整Brent_Kung_scan代码:
#include<cuda.h>
#include<stdio.h>
#include<stdlib.h>
#define SECTION_SIZE 2048
__global__ void Brent_Kung_scan_kernel(float *X, int input_size){
__shared__ float XY[SECTION_SIZE];
//将数组加载到共享寄存器,一个线程加载两个元素。
int i = 2 * blockIdx.x * blockDim.x + threadIdx.x;
if(i < input_size) XY[threadIdx.x] = X[i];
else XY[threadIdx.x] = 0.0f;
if(i + blockDim.x < input_size) XY[threadIdx.x + blockDim.x] = X[i + blockDim.x];
else XY[threadIdx.x + blockDim.x] = 0.0f;
//不带控制流的归约求和
for(unsigned int stride = 1;stride <= blockDim.x;stride *= 2){
__syncthreads();
int index = (threadIdx.x + 1)*stride*2 - 1;
if(index < SECTION_SIZE)
XY[index] += XY[index - stride];
}
//分发部分和
for(unsigned int stride = SECTION_SIZE/4; stride > 0; stride /= 2){
__syncthreads();
int index = (threadIdx.x + 1)*stride*2 - 1;
if(index + stride < SECTION_SIZE)
XY[index + stride] += XY[index];
}
__syncthreads();
if(i < input_size) X[i] = X[threadIdx.x];
if(i + blockDim.x < input_size) X[i + blockDim.x] = XY[threadIdx.x + blockDim.x];
}
void test(float *A, int n){
float *d_A;
int size = n * sizeof(float);
cudaMalloc(&d_A, size);
cudaMemcpy(d_A, A, size, cudaMemcpyHostToDevice);
Brent_Kung_scan_kernel<<<ceil((float)n/(SECTION_SIZE/2)), SECTION_SIZE/2>>>(d_A, n);
cudaMemcpy(A, d_A, size, cudaMemcpyDeviceToHost);
cudaFree(d_A);
}
int main(int argc, char **argv){
int n = atoi(argv[1]);
float *A = (float *)malloc(n * sizeof(float));
for(int i = 0; i < n;++i){
A[i] = 1.0;
}
test(A, n);
for(int i = 0;i < n; ++i){
printf("%f ", A[i]);
}
free(A);
return 0;
}
对于 N 个元素的数组,操作总数为 (N/2) + (N/4) + … + 4 + 2 -1 约为 N - 2,所以最终的操作数为 2 × N − 3 2 \times N-3 2×N−3。下表比较了不同 N 下的执行的操作数。
| N | 16 | 32 | 64 | 128 | 256 | 512 | 1024 |
|---|---|---|---|---|---|---|---|
| N − 1 N-1 N−1 | 15 | 31 | 63 | 127 | 255 | 51 | 1023 |
| N × l o g 2 ( N ) − ( N − 1 ) N \times log_2(N)-(N-1) N×log2(N)−(N−1) | 49 | 129 | 321 | 769 | 1793 | 4097 | 9217 |
| 2 × N − 3 2 \times N-3 2×N−3 | 29 | 61 | 125 | 253 | 509 | 1021 | 2045 |
由于操作数量现在与 N 成正比,而不是与 N × l o g 2 ( N ) N \times log_2(N) N×log2(N) 成正比,所以高效的算法执行的总操作数不会超过串行的两倍。只要有至少两倍的执行单元,并行算法的性能就能比串行更好。
更大长度的并行扫描
上面的算法最多只能处理 2048 个元素,我们需要一种能处理更多元素的并行算法,下面的层级扫描就是其中一种方法。
- 首先对整个数组使用上一节的 Brent_Kung_scan_kernel 进行处理,每个块内都会进行扫描,扫描后结果数组中仅保留了块内扫描的结果,我们称这些段为扫描块。
- 将每个块最后一个数保留到长度为 m 的辅助数组 S 中,对 S 进行扫描。
- 将 S 的前 m - 1 个元素分别加到结果数组的后 m - 1 个扫描块的每个元素中。
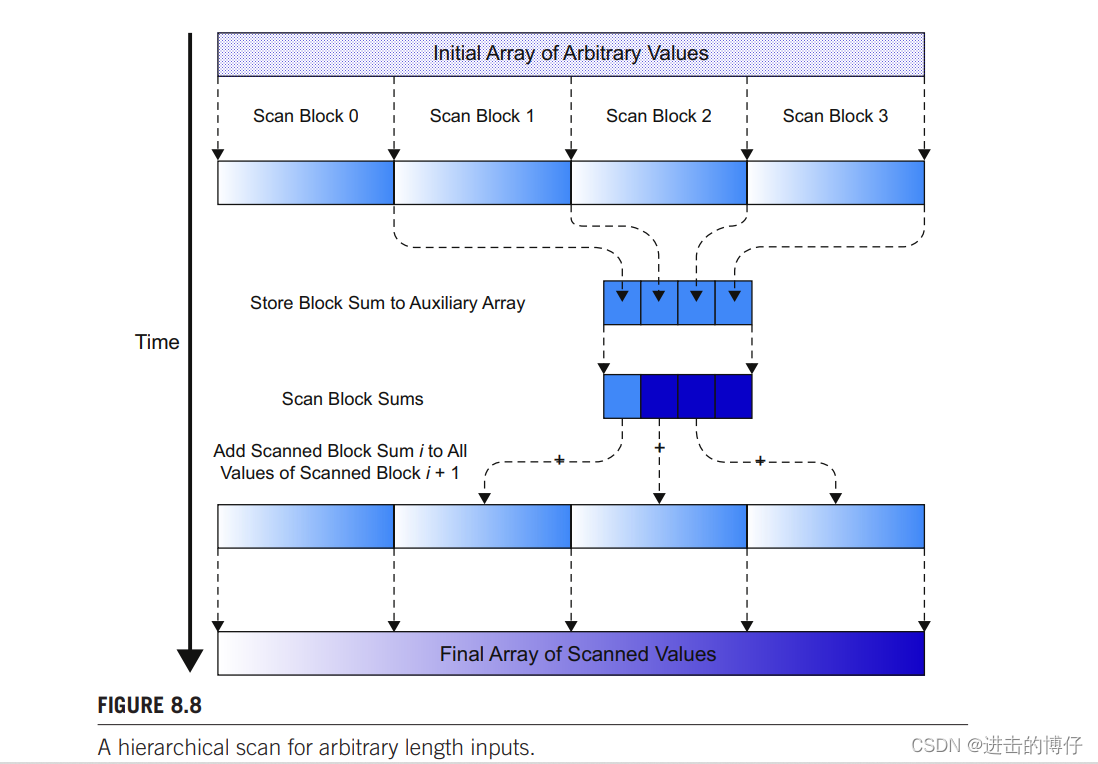
当前的 CUDA 设备每个 block 中有1024个线程,每个 block 最多能处理 2048 个元素,grid x 维中有 65536 个线程块,最多可以处理 134217728 个元素。
完成上图的工作我们设计 3 个 kernel。
-
第一个 kernel 使用块的第一个线程,将扫描块的最后一个元素加载到 S 数组上。可以使用 Brent_Kung_scan_kernel 然后在其后面加上:
__syncthreads(); if(threadIdx.x == 0) S[blockIdx.x] = XY[SECTION_SIZE - 1]; -
第二个 kernel 对 S 进行扫描。可以使用 Brent_Kung_scan_kernel。
-
第三个 kernel 将 S 回写到原本数组上。
最终代码如下:
#include<cuda.h>
#include<stdio.h>
#include<stdlib.h>
#define SECTION_SIZE 2048
__global__ void Brent_Kung_scan_kernel_1(float *X, float *S, int input_size){
__shared__ float XY[SECTION_SIZE];
//将数组加载到共享寄存器,一个线程加载两个元素。
int i = 2 * blockIdx.x * blockDim.x + threadIdx.x;
if(i < input_size) XY[threadIdx.x] = X[i];
else XY[threadIdx.x] = 0.0f;
if(i + blockDim.x < input_size) XY[threadIdx.x + blockDim.x] = X[i + blockDim.x];
else XY[threadIdx.x + blockDim.x] = 0.0f;
//不带控制流的归约求和
for(unsigned int stride = 1;stride <= blockDim.x;stride *= 2){
__syncthreads();
int index = (threadIdx.x + 1)*stride*2 - 1;
if(index < SECTION_SIZE)
XY[index] += XY[index - stride];
}
//分发部分和
for(unsigned int stride = SECTION_SIZE/4; stride > 0; stride /= 2){
__syncthreads();
int index = (threadIdx.x + 1)*stride*2 - 1;
if(index + stride < SECTION_SIZE)
XY[index + stride] += XY[index];
}
__syncthreads();
if(i < input_size) X[i] = XY[threadIdx.x];
if(i + blockDim.x < input_size) X[i + blockDim.x] = XY[threadIdx.x + blockDim.x];
__syncthreads();
if(threadIdx.x == 0){
S[blockIdx.x] = XY[SECTION_SIZE - 1];
}
}
__global__ void Brent_Kung_scan_kernel_2(float *X, int input_size){
__shared__ float XY[SECTION_SIZE];
//将数组加载到共享寄存器,一个线程加载两个元素。
int i = 2 * blockIdx.x * blockDim.x + threadIdx.x;
if(i < input_size) XY[threadIdx.x] = X[i];
if(i + blockDim.x < input_size) XY[threadIdx.x + blockDim.x] = X[i + blockDim.x];
//不带控制流的归约求和
for(unsigned int stride = 1;stride <= blockDim.x;stride *= 2){
__syncthreads();
int index = (threadIdx.x + 1)*stride*2 - 1;
if(index < SECTION_SIZE)
XY[index] += XY[index - stride];
}
//分发部分和
for(unsigned int stride = SECTION_SIZE/4; stride > 0; stride /= 2){
__syncthreads();
int index = (threadIdx.x + 1)*stride*2 - 1;
if(index + stride < SECTION_SIZE)
XY[index + stride] += XY[index];
}
__syncthreads();
if(i < input_size) X[i] = XY[threadIdx.x];
if(i + blockDim.x < input_size) X[i + blockDim.x] = XY[threadIdx.x + blockDim.x];
}
__global__ void kernel_3(float *X, float *S, int input_size){
//一个线程处理两个元素。
int i = 2*blockDim.x*blockIdx.x + threadIdx.x;
if(blockIdx.x > 0){
X[i] += S[blockIdx.x - 1];
X[blockDim.x + i] += S[blockIdx.x - 1];
}
}
void test(float *A, int n){
float *d_A, *S;
int size = n * sizeof(float);
cudaMalloc(&d_A, size);
cudaMalloc(&S, ceil((float)n/SECTION_SIZE)*sizeof(float));
cudaMemcpy(d_A, A, size, cudaMemcpyHostToDevice);
Brent_Kung_scan_kernel_1<<<ceil((float)n/(SECTION_SIZE)), SECTION_SIZE/2>>>(d_A, S, n);
Brent_Kung_scan_kernel_2<<<ceil((float)(ceil((float)n/SECTION_SIZE))/(SECTION_SIZE)), SECTION_SIZE/2>>>(S, n);
kernel_3<<<ceil((float)n/(SECTION_SIZE)), SECTION_SIZE/2>>>(d_A, S, n);
cudaMemcpy(A, d_A, size, cudaMemcpyDeviceToHost);
cudaFree(d_A);
}
int main(int argc, char **argv){
int n = atoi(argv[1]);
float *A = (float *)malloc(n * sizeof(float));
for(int i = 0; i < n;++i){
A[i] = 1.0;
}
test(A, n);
// for(int i = 0;i < n; ++i){
// printf("%f ", A[i]);
// }
printf("%f ", A[n-1]);
free(A);
return 0;
}
运行结果:
由于打印速度太慢,所以直接打印最后一个元素,等于输入长度即为正确。

长度为一千万的时候计算结果错误。

查找一下最多能正确计算的长度约为 4125000,这可能跟硬件有关,但具体跟什么有关也不清楚。后面学的多了再来补充一下。