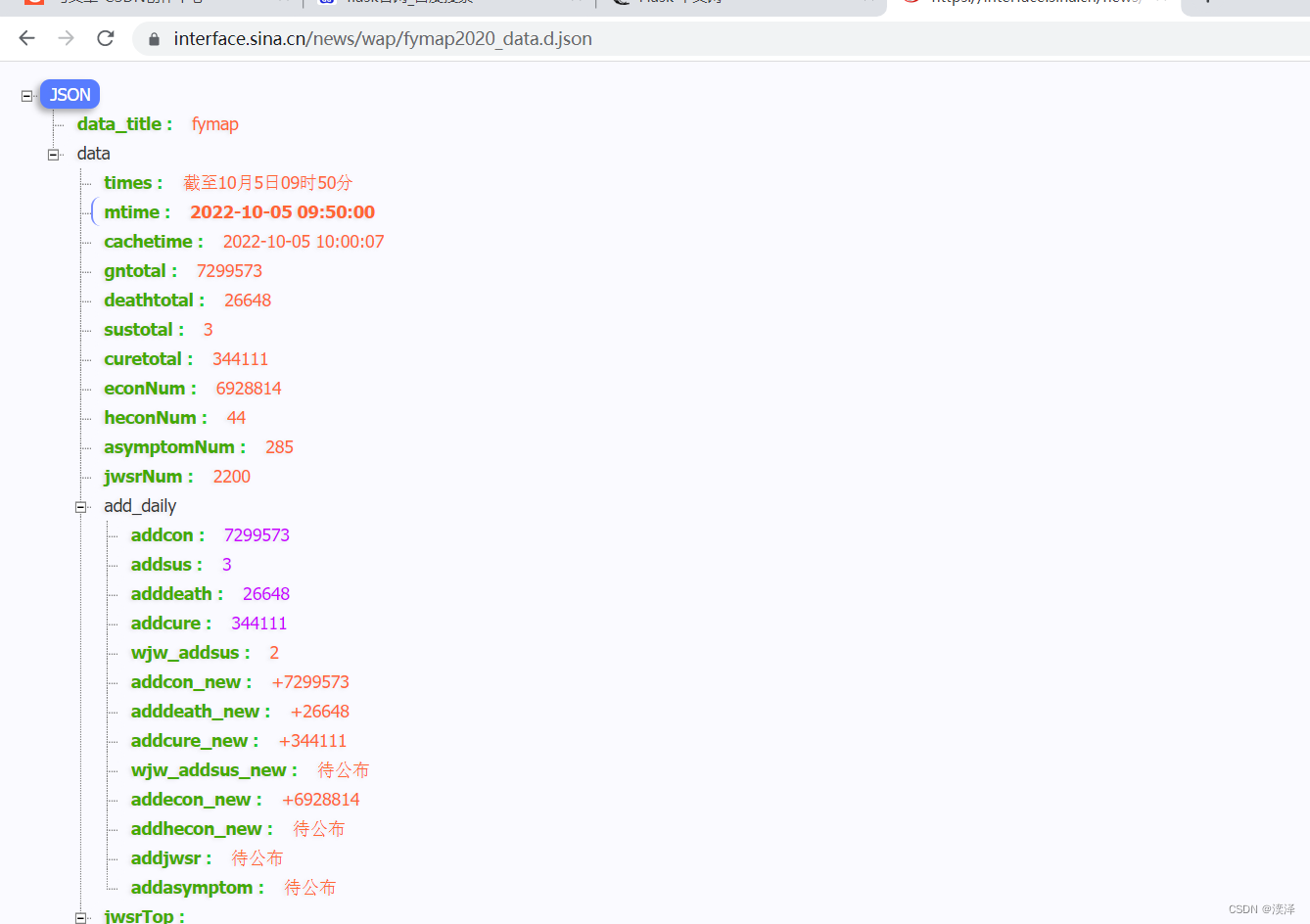
https://interface.sina.cn/news/wap/fymap2020_data.d.json
新浪疫情数据接口
代码分为两个模块 一个为数据表创建部分 一个为数据爬取存储部分
创建数据表
from peewee import *
db = MySQLDatabase("数据库名称", host="mysql地址", port=3306, user="用户", password="密码")
class BaseModel(Model):
class Meta:
database = db
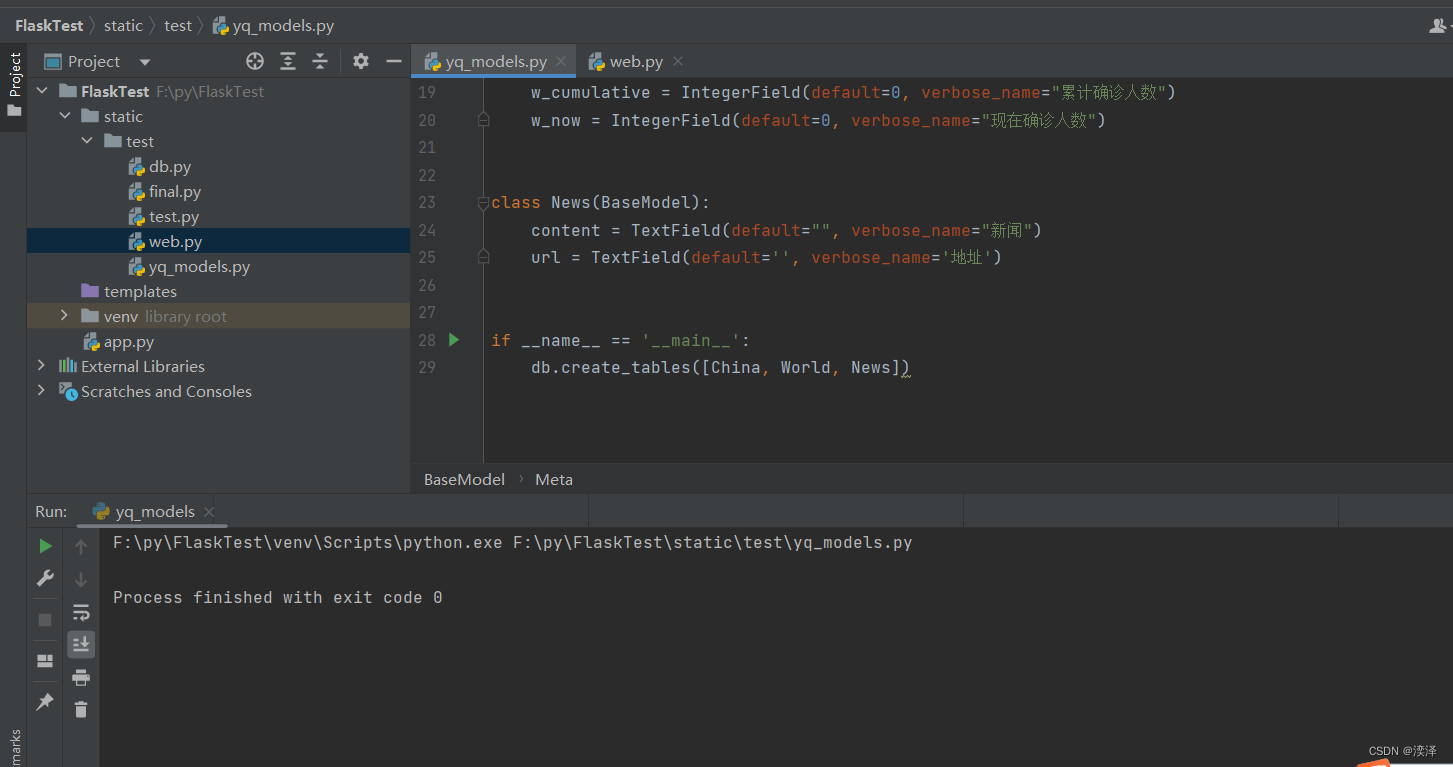
class China(BaseModel):
province = CharField(max_length=20, verbose_name="省份名称")
cumulative = IntegerField(default=0, verbose_name="累计确诊人数")
now = IntegerField(default=0, verbose_name="现在确诊人数")
class World(BaseModel):
country = CharField(max_length=30, verbose_name="国家名称")
w_cumulative = IntegerField(default=0, verbose_name="累计确诊人数")
w_now = IntegerField(default=0, verbose_name="现在确诊人数")
class News(BaseModel):
content = TextField(default="", verbose_name="新闻")
url = TextField(default='', verbose_name='地址')
if __name__ == '__main__':
db.create_tables([China, World, News])运行成功没有错误
查看自己的数据库

数据解析阶段
import json
import numpy as np
import requests
import scrapy
import sys # 导入sys模块
from matplotlib import pyplot as plt
from static.test.yq_models import World, China, News
sys.setrecursionlimit(3000) # 将默认的递归深度修改为3000
url = 'https://interface.sina.cn/news/wap/fymap2020_data.d.json'
res = requests.get(url)
res.encoding = 'utf-8'
data = json.loads(res.text)
url = "https://interface.sina.cn/news/wap/fymap2020_data.d.json"
headers = {
'user-agent':
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.107 Safari/537.36'
}
def init():
req = requests.get(url, headers)
req_json = req.json()
return req_json
data_json = init()
other_nation_list = data_json['data']['otherlist']
def is_key():
for i in range(10):
if len(other_nation_list) > 1:
break
else:
init()
# 世界地区
def world_nation_list():
for item in other_nation_list:
nation_name = item['name']
# 现在确诊
cure_num = item['cureNum']
con_num = item['conNum']
world = World()
world.country = nation_name
world.w_now = cure_num
world.w_cumulative = con_num
world.save()
province_list = []
province_now_list = []
# 中国地区
def china_details():
china_list = data_json['data']['list']
for info in china_list:
province_name = info['name']
province_value = info['value']
province_econ_um = info['econNum']
province = China()
province.province = province_name
province.cumulative = province_value
province.now = province_econ_um
province.save() ## 保存到数据库
# 绘制图形
# province_list.append(province_name)
# province_now_list.append(province_value)
#Chaintux(province_list, province_now_list)
// 绘制图形
def Chaintux(province_list,province_now_list):
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
y =province_list
x =province_now_list
brah_height = 0.3
tick_label = province_list
plt.barh(y, x, height=brah_height, tick_label=tick_label)
plt.show()
news_content1=[]
def xpath():
url = "http://covid-19.lzu.edu.cn/xwbd.htm"
req = requests.get(url)
req.encoding = "utf-8"
# print(req.text)
sel = scrapy.Selector(text=req.text)
div_list = sel.xpath("//div[@class='list-wrap']/ul/li")
for li in div_list:
content = li.xpath('./a/text()').extract_first()
url = li.xpath('./a/@href').extract_first()
news = News()
news.url = url
news.content = content
news.save()
# print("文本 : ", content, " urL: ", url)
news_content1.append(content)
# ciyun(news_content1)
if __name__ == '__main__':
china_details()
world_nation_list()
#Chaintux()
# world_nation_list()
xpath()
扫描二维码关注公众号,回复:
16968409 查看本文章

其中还有一个网页是xpath爬取的内容
查看数据表
news表
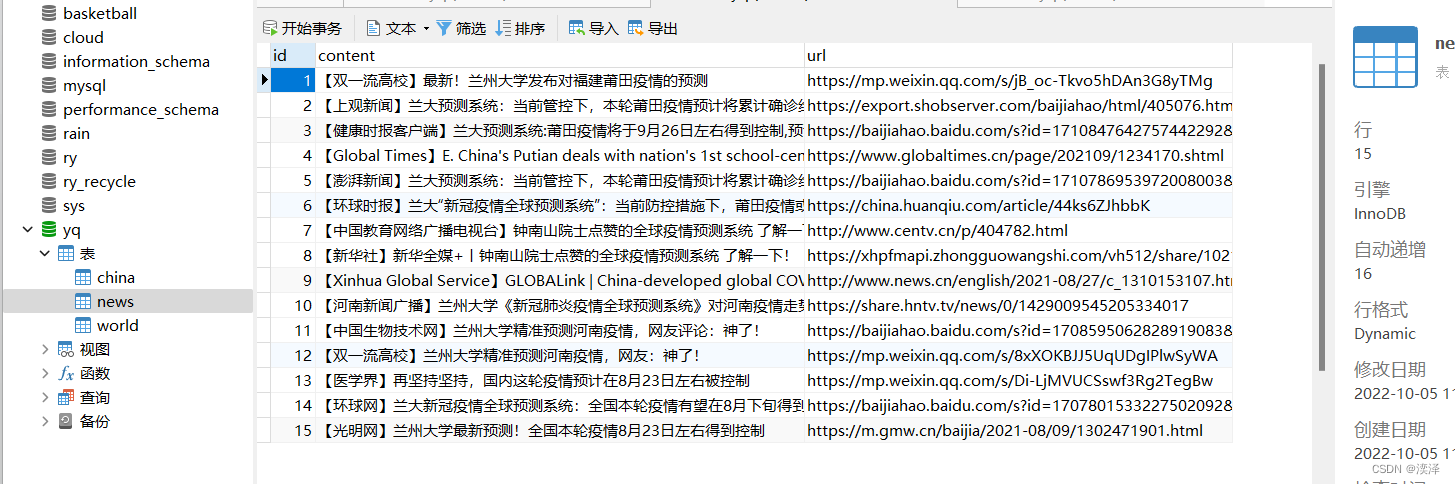
china表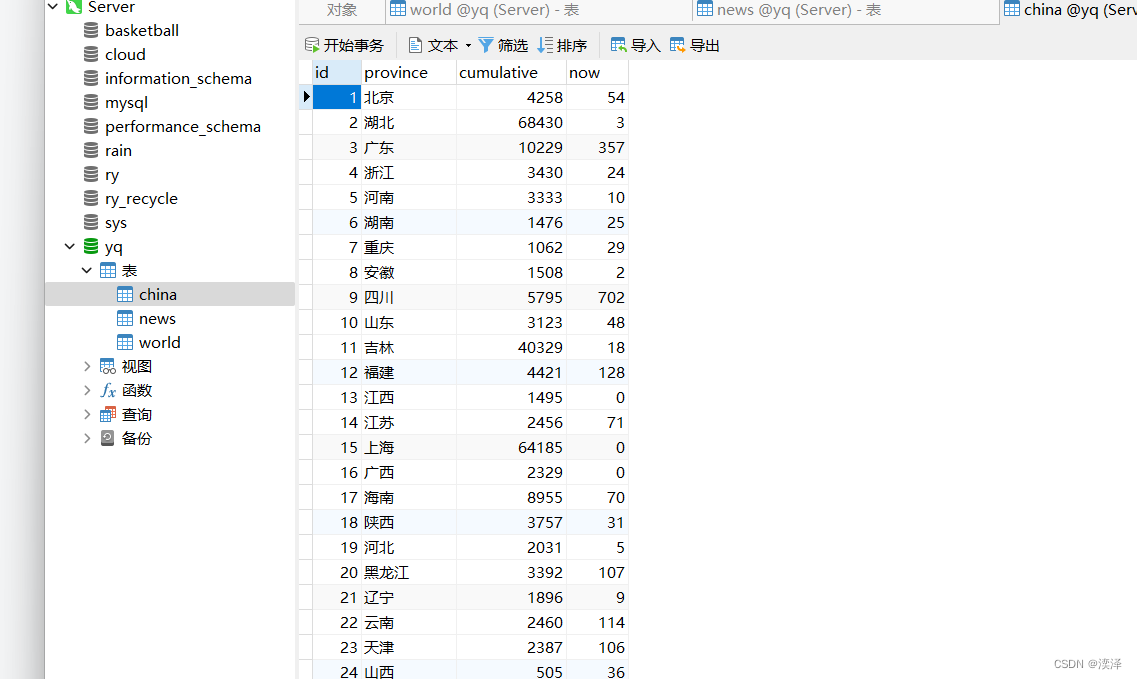
world 表