文章目录
一、微博网页分析
可以看见微博数据加载需要滑动滚轮,想要更多数据那么就需要使用到Selenium操纵滑轮
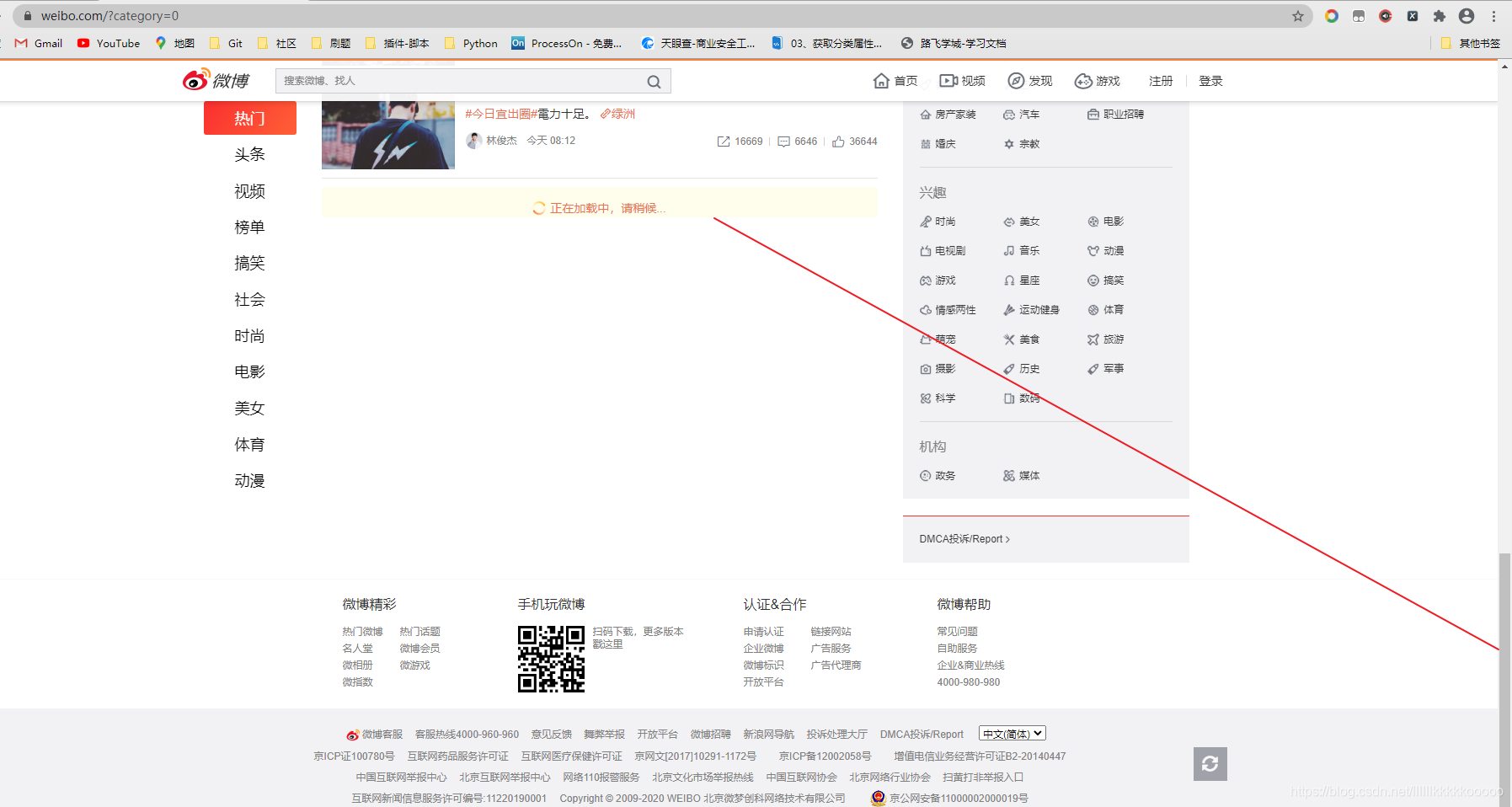
二、完整代码及代码分析
from selenium import webdriver
import time
import pymysql
from selenium.webdriver.chrome.options import Options
from selenium.webdriver import ChromeOptions
from bs4 import BeautifulSoup
#初始化浏览器
def init():
# 实现无可视化界面得操作
chrome_options = Options()
chrome_options.add_argument('--headless')
chrome_options.add_argument('--disable-gpu')
# 设置chrome_options=chrome_options即可实现无界面
driver = webdriver.Chrome(chrome_options=chrome_options)
# 把浏览器实现全屏
# driver.maximize_window()
# 返回driver
return driver
#找到指定页面进行操作返回源码
def index(driver):
#请求
driver.get("http://weibo.com/login.php")
time.sleep(1)
#selenium定位头条模块进行点击访问
#据博主测试这样不能直接访问成功,此时使浏览器后退即可达到访问目的
driver.find_element_by_xpath("//*[@id='pl_unlogin_home_leftnav']/div/ul/div[2]/li/a").click()
time.sleep(0.5)
#后退
driver.back()
time.sleep(1)
#控制滚轮逐步进行向下滑动
for y in range(10):
js = 'window.scrollBy(0,700)'
driver.execute_script(js)
time.sleep(0.5)
time.sleep(1)
#获得源码
source = driver.page_source
return source
#解析
def download(page_text):
dbparams = {
'host': '127.0.0.1',
'port': 3306,
'user': '数据库用户名',
'password': '密码',
'database': '数据库名称',
'charset': 'utf8'
}
conn = pymysql.connect(**dbparams)
cur = conn.cursor()
#sql插入语句
sql = "insert into wb(id,title,name,url,Time,fabulous,comment,forward) values(null,%s,%s,%s,%s,%s,%s,%s)"
# 使用lxml XML解析器
bs = BeautifulSoup(page_text, "lxml")
#拿到所有div标签,参考图1
div_list = bs.find_all(class_="UG_list_b")
for li in div_list:
bs = BeautifulSoup(str(li), "lxml")
#标题,参考图2(.string拿到文本)
title = bs.find(class_="S_txt1").string
#博文链接,参考图3(['href']拿到href属性)
url = bs.find(class_="S_txt1")['href']
#博文作者名称,参考图4
#由于我们使用的使BeautifulSoup不好直接定位名称,因为后面的时间的class值和名称的相同,所有使用limit=2拿到匹配的最前面的2个,返回结果为列表,直接拿值,(.text拿文本值)
name = bs.find_all(class_='subinfo S_txt2',limit=2)[0].text
#创作时间,同上,由于当天发布的博文用的是今天+时分替代的,所以我把今天替换为年月日
Time = bs.find_all(class_='subinfo S_txt2',limit=2)[1].text
Time = str(Time).replace("今天",time.strftime("@Y-%m-%d", time.localtime(time.time())))
# print(bs.find_all(class_="subinfo_rgt S_txt2",limit=3))
#以下参考图5,这儿离我们使用的是select选择器,同样返回值为列表,不知道怎么写select的有个快捷方法参考图6
#但需要注意的是,这个方法得到的语句是根据整个页面来查找的,我们需要截取,仔细看看就可以截取,没多难度
#点赞数
fabulous = bs.select("em:nth-child(2)")[0].text
#评论数
comment = bs.select("em:nth-child(2)")[1].text
#转发数
forward = bs.select("em:nth-child(2)")[2].text
#执行sql语句进行插入
cur.execute(sql, (title, name, url, Time, fabulous, comment, forward))
#提交事务
conn.commit()
#关闭连接
cur.close()
conn.close()
#运行开始
if __name__ == "__main__":
driver = init()
# cursor = init_mysql()
source = index(driver)
download(source)
三、图片辅助理解
图1
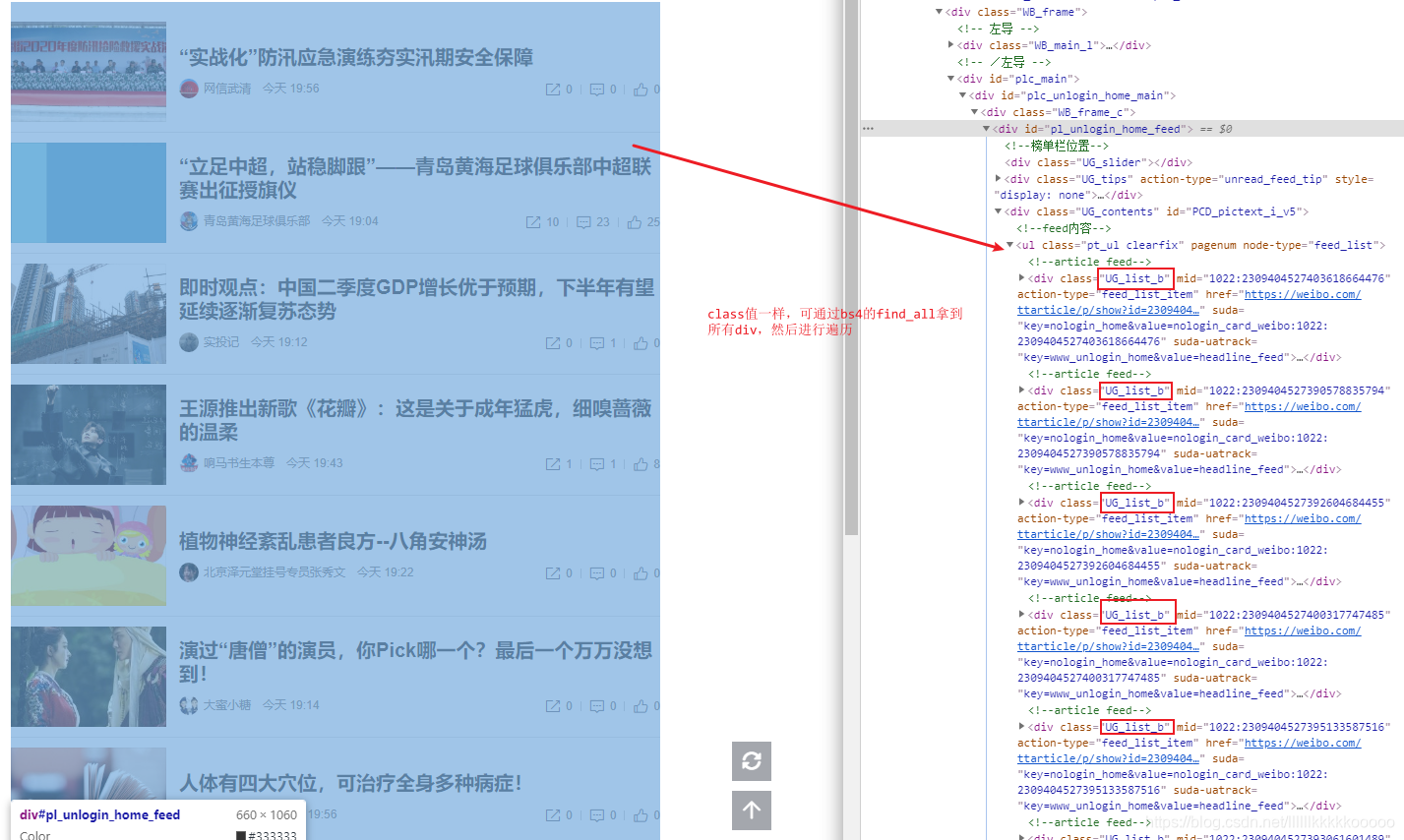
图2
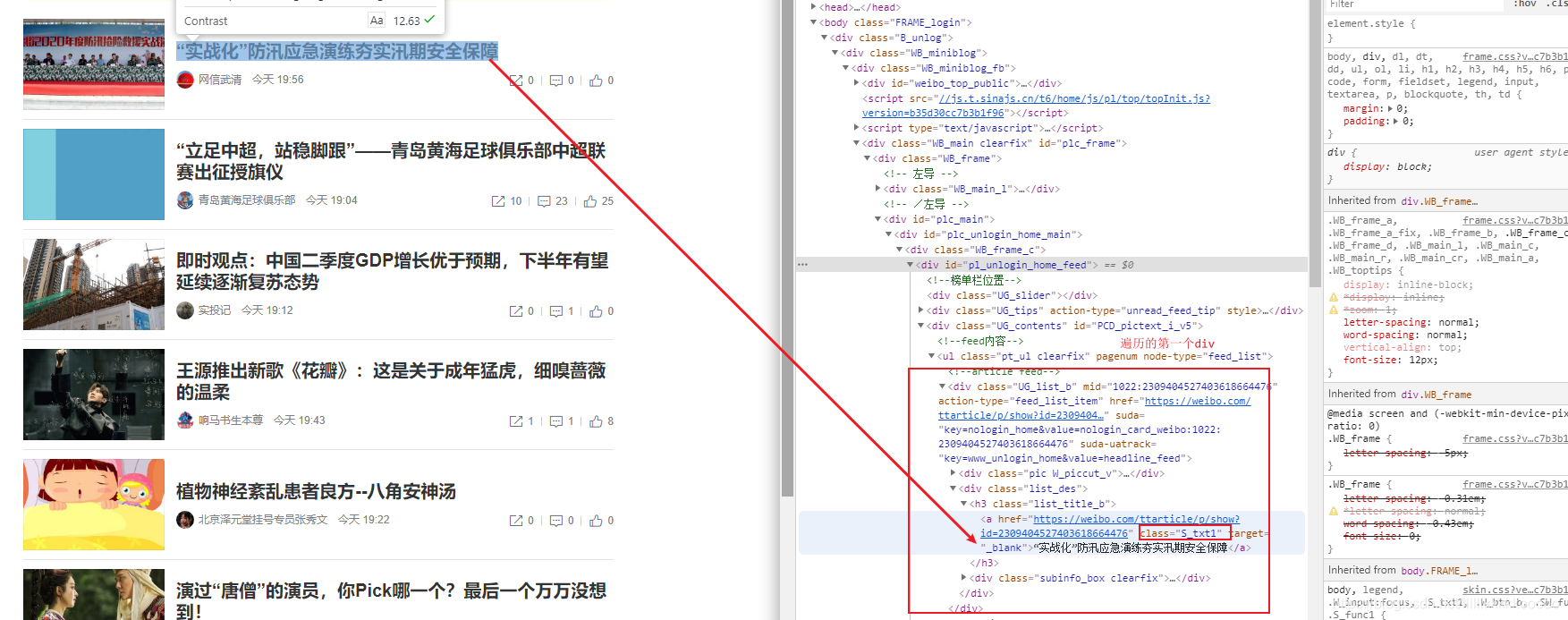
图3
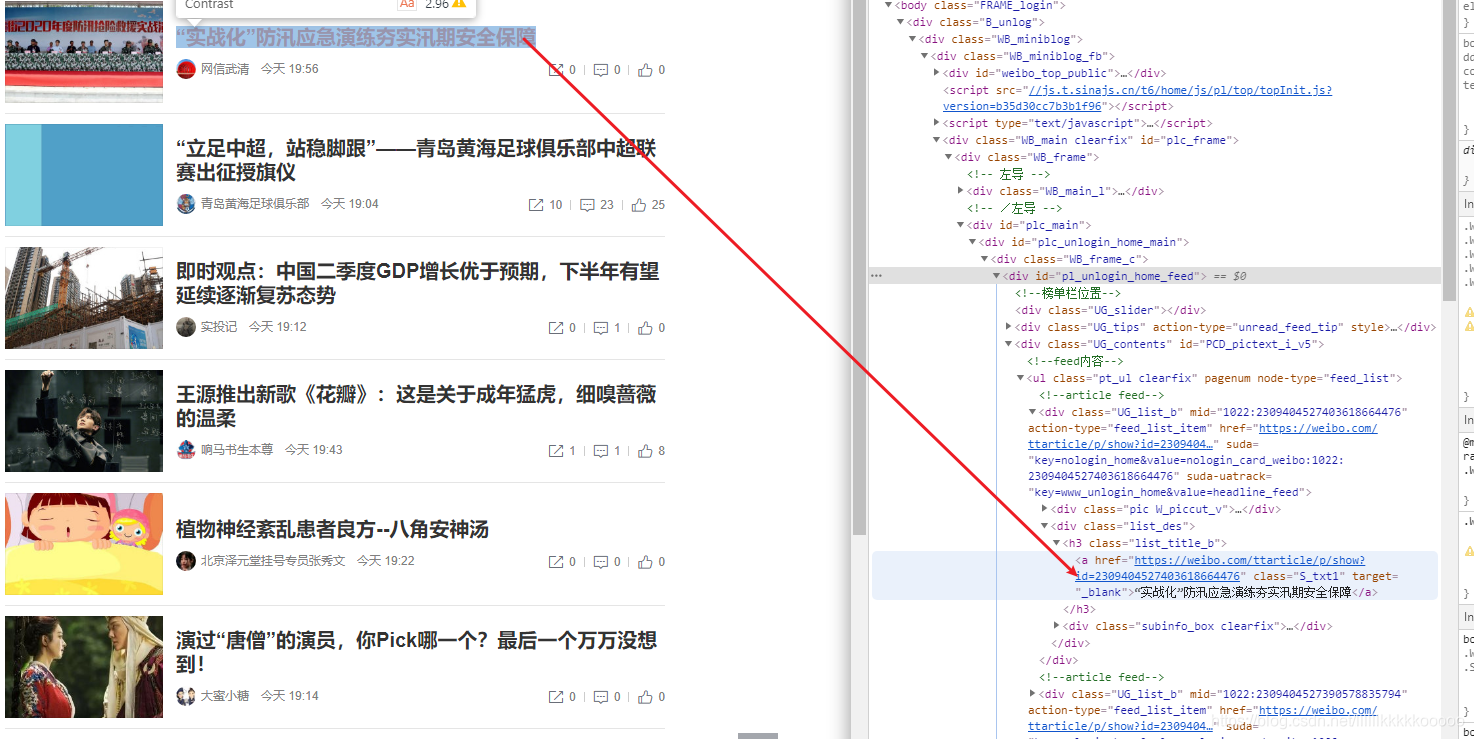
图4
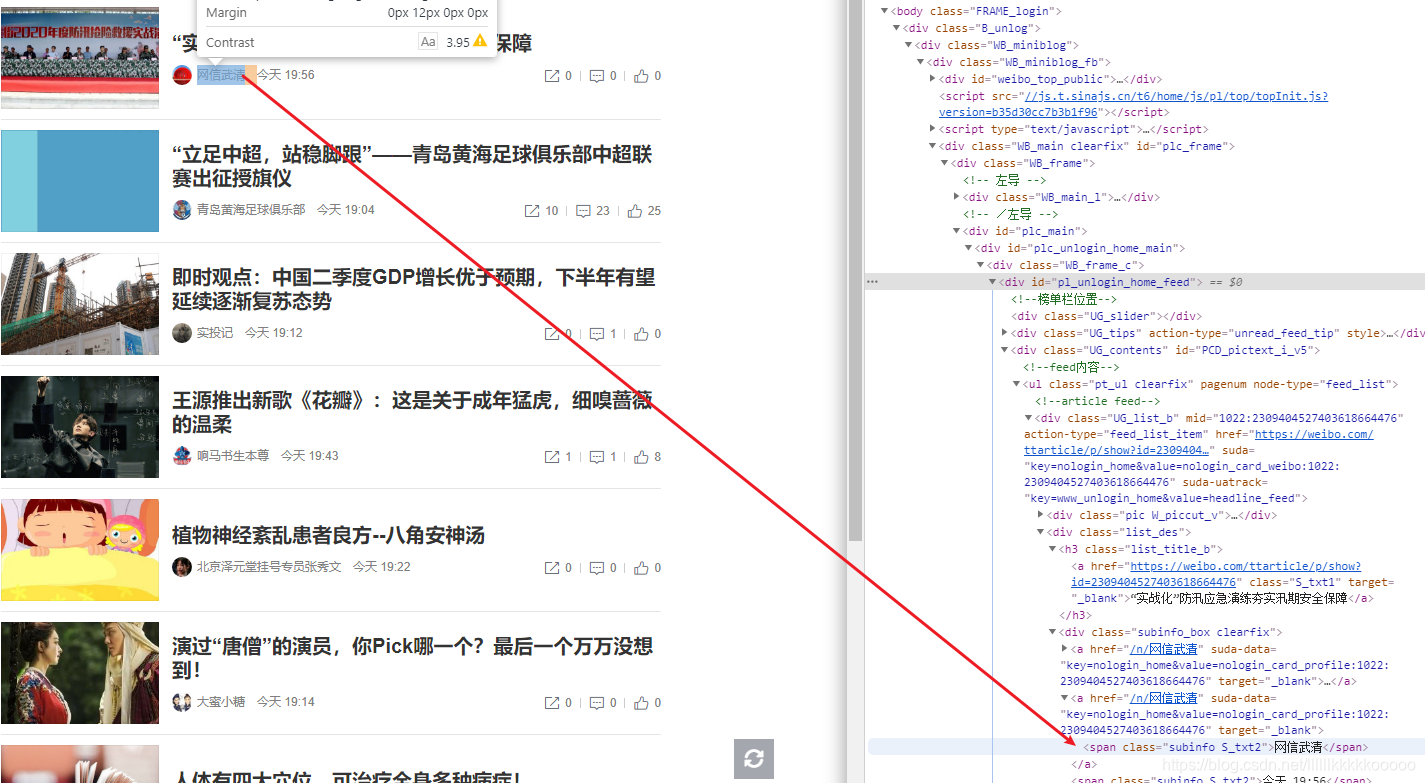
图5
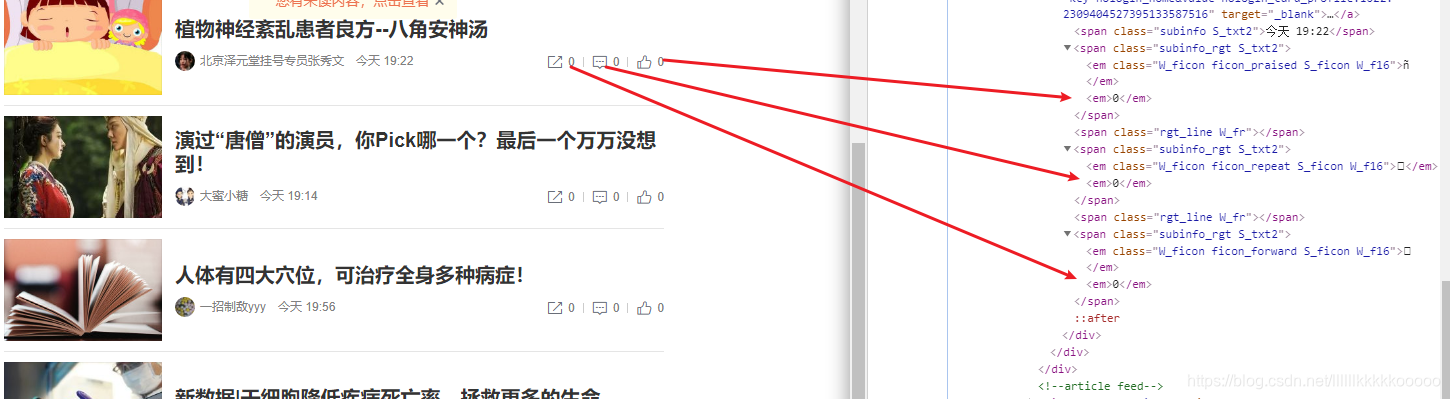
图6
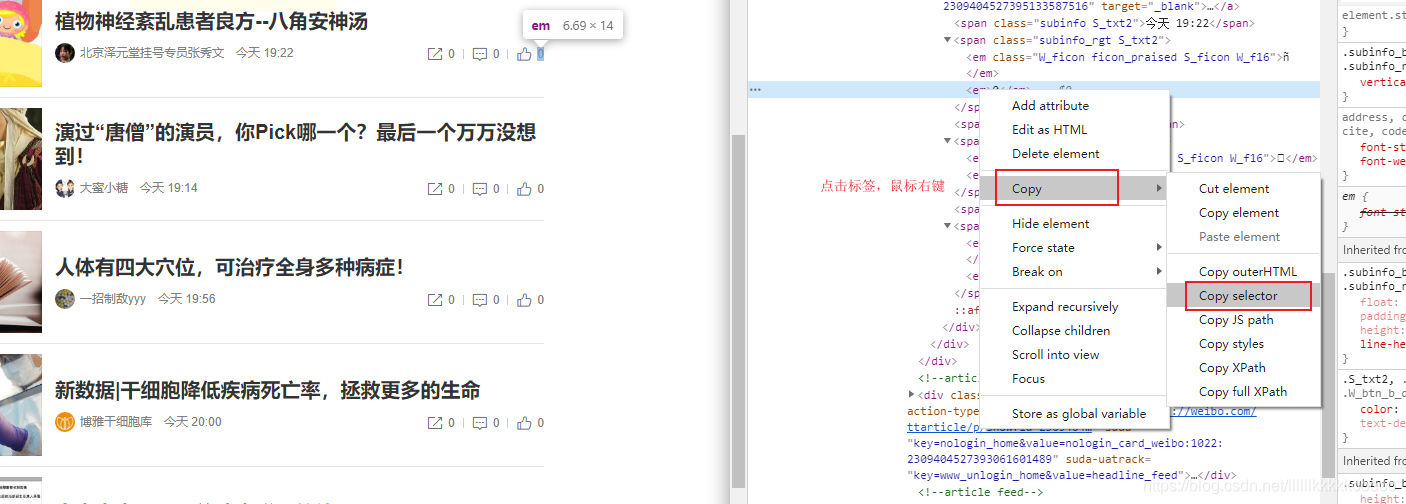
新建数据库weibo
mysql建表语句,建立wb表
CREATE TABLE `wb` (
`id` int(10) NOT NULL AUTO_INCREMENT,
`title` varchar(100) DEFAULT NULL,
`name` varchar(100) DEFAULT NULL,
`url` varchar(100) DEFAULT NULL,
`Time` varchar(30) DEFAULT NULL,
`fabulous` int(10) DEFAULT NULL,
`comment` int(10) DEFAULT NULL,
`forward` int(255) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=40 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;
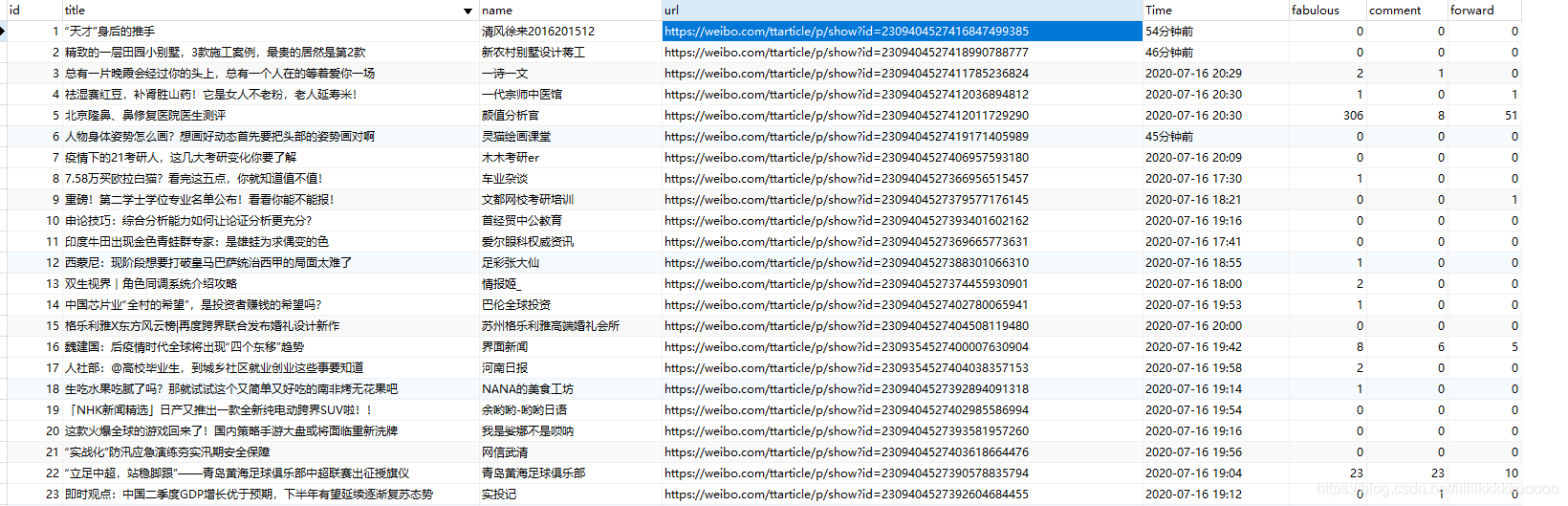
运行结果
觉得博主写的不错的读者大大们,可以点赞关注和收藏哦,谢谢各位!