版权声明:版权声明:本文为博主原创文章,转载请注明出处!!!(●'◡'●) https://blog.csdn.net/xiaocy66/article/details/83052555
本文的前提是实现了整站内容的抓取,然后把抓取的内容保存到数据库。
可以参考另一篇已经实现整站抓取的文章:Scrapy 使用CrawlSpider整站抓取文章内容实现
本文也是基于这篇文章代码基础上实现通过pymysql+twisted异步保存到本地数据库
直接进入主题:
# -*- coding: utf-8 -*-
import pymysql
from twisted.enterprise import adbapi
from scrapy.utils.project import get_project_settings
class DBHelper():
def __init__(self):
settings = get_project_settings()
dbparams = dict(
host=settings['MYSQL_HOST'],
db=settings['MYSQL_DBNAME'],
user=settings['MYSQL_USER'],
passwd=settings['MYSQL_PASSWD'],
charset='utf8', #解决中文乱码问题
cursorclass=pymysql.cursors.DictCursor,
use_unicode=False,
)
#**表示将字典扩展为关键字参数,相当于host=xxx,db=yyy....
dbpool = adbapi.ConnectionPool('pymysql', **dbparams)
self.__dbpool = dbpool
def connect(self):
return self.__dbpool
def insert(self, item):
#这里定义要插入的字段
sql = "insert into article(title) values(%s)"
query = self.__dbpool.runInteraction(self._conditional_insert, sql, item)
query.addErrback(self._handle_error)
return item
#写入数据库中
def _conditional_insert(self, canshu, sql, item):
#这里item就是爬虫代码爬下来存入items内的数据
params = (item['title'])
canshu.execute(sql, params)
def _handle_error(self, failue):
print(failue)
def __del__(self):
try:
self.__dbpool.close()
except Exception as ex:
print(ex)
- 定义数据库表结构(提前创建好名为scrapy的数据库并授权给root用户):
CREATE TABLE `article` (
`id` bigint(20) unsigned NOT NULL AUTO_INCREMENT,
`title` varchar(200) DEFAULT NULL COMMENT '文章标题',
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=116 DEFAULT CHARSET=utf8mb4
- settings.py中定义用到的数据库连接信息(这里配置的账号等信息根据你自己的环境相应改动):
#mysql-config
MYSQL_HOST = '127.0.0.1'
MYSQL_DBNAME = 'scrapy'
MYSQL_USER = 'root'
MYSQL_PASSWD ='123456'
MYSQL_PORT = 3306
- 最后在管道中把爬取的内容保存到mysql数据库中:
pipelines.py 的代码如下(其中还保存到json文件中了,不需要的可以去掉file相关操作的代码):
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://doc.scrapy.org/en/latest/topics/item-pipeline.html
import json
from logging import Logger
from twisted.enterprise import adbapi
from blogscrapy.db.dbhelper import DBHelper
import codecs
from logging import log
from scrapy.utils.project import get_project_settings
class BlogscrapyPipeline(object):
def __init__(self):
self.file = open('blog.json', 'a+', encoding='utf-8')
self.db = DBHelper()
def process_item(self, item, spider):
content = json.dumps(dict(item), ensure_ascii=False) + "\n"
self.file.write(content)
self.db.insert(item)
return item
def close_spider(self, spider):
self.file.close()
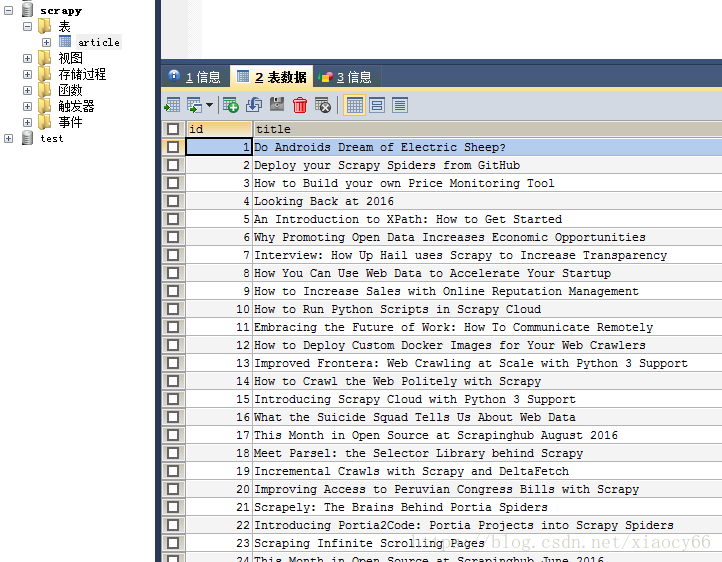
结果如下图:
本文源码下载: 点我去下载
参考资料
[1]: Scrapy官方文档
[2]: Python3爬取今日头条系列
[3]: 廖雪峰老师的Python3 在线学习手册
[4]: Python3官方文档
[5]: 菜鸟学堂-Python3在线学习
[6]: XPath语法参考
[7]: Scrapy 使用CrawlSpider整站抓取文章内容实现