目标:利用selenium抓取淘宝商品并利用pyquery解析得到的商品名称,图片,价格,购买人数,店铺名称和店铺所在地信息,并将其保存在mongodb。
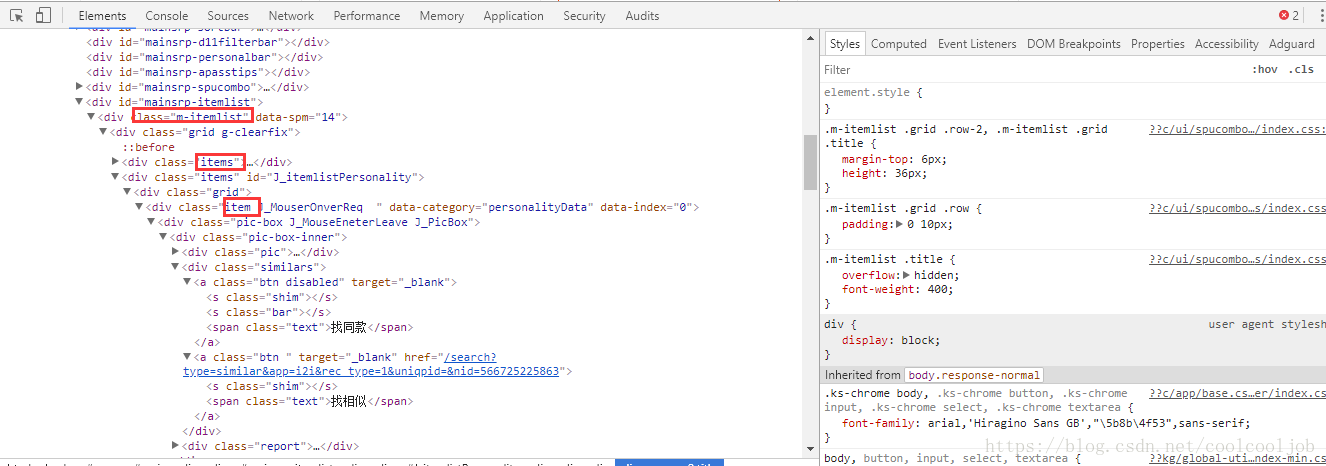
1.打开淘宝首页,搜索你要搜索的商品名称,比如我这里搜索ipad,注意观察此时的url有什么变化(附上链接https://s.taobao.com/search?q=ipad)),仔细观察便可以看到不同,然后查看网页源代码,找到商品列表所在的位置,如图所示,商品列表藏在m-itemlist 里面的items里面的item:
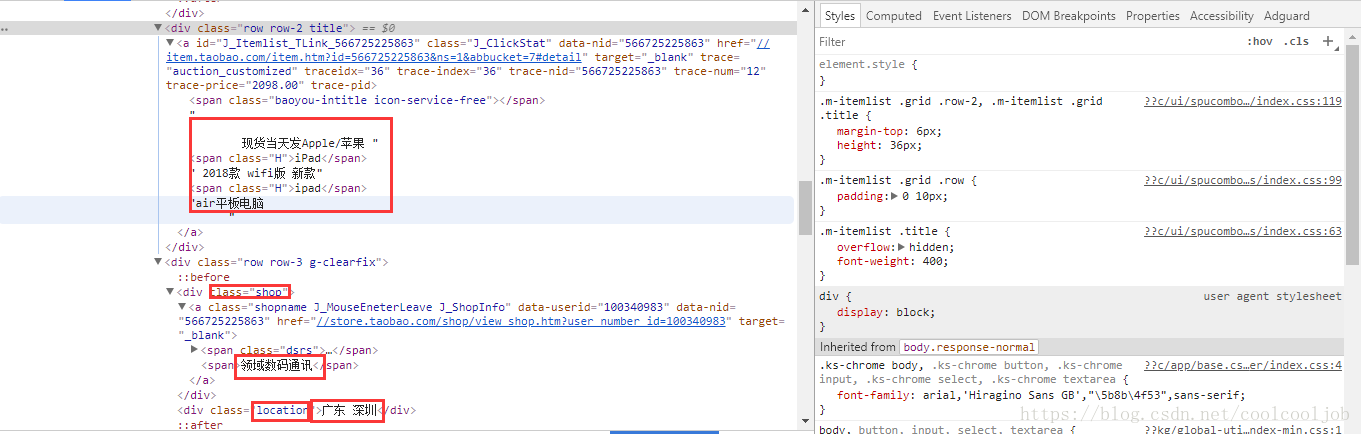
继续下拉,查询商品的详细信息,比如商品的图片,名称,价格,购买人数,店铺名称等,如图所示:
大概就是类似这样的信息。而我们要做的就是将这些信息抓取下来,再往下拉就可以发现,在页面下方,有一个分页导航,同时还有一个可以输入任意页码跳转的链接,如图所示:

这里商品的搜索结果一般都大于100页,要获取每一页的内容,只需要将页码从1到100遍历即可。所以,直接在页面跳转链接中输入要跳转的链接即可跳转到页码相应的页面。
3.整个代码部分按功能分为几个部分,先定义一个获取商品列表的函数index_page(),先访问了搜索商品的链接,再判断当前的页码,如果大于1,就进行跳页,否则等待页面加载完毕,至于翻页部分,我们可以获取输入框,赋值为input,再获取确定框,赋值为submit,再利用selenium模块模拟浏览器操作进行翻页,确定就可以了。之后再定义一个解析商品列表的函数get_products(),直接获取网页源代码,然后用pyquery进行解析。再定义一个保存到mongodb数据库的函数,将爬取的数据保存在数据库中,最后要做的就是遍历每一页,在最开始定义的获取索引页的函数里面传入一个参数page,代表页码。具体代码如下,仅供参考。
from selenium import webdriver
from selenium.common.exceptions import TimeoutException
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.wait import WebDriverWait
from urllib.parse import quote
from pyquery import PyQuery as pq
from multiprocessing import Pool
import pymongo
browser=webdriver.Chrome()
wait=WebDriverWait(browser,10)
KEYWORD='ipad'
MONGO_URL='localhost'
MONGO_DB='TAOBAO'
MONGO_COLLECTION='products'
client=pymongo.MongoClient(MONGO_URL)
db=client[MONGO_DB]
def index_page(page): #定义一个获取索引页信息的函数
print('正在爬取第',page,'页')
try:
url='https://s.taobao.com/search?q='+quote(KEYWORD)
browser.get(url)
if page>1:
input=wait.until(EC.presence_of_element_located((By.CSS_SELECTOR,'#mainsrp-pager > div > div > div > div.form > input')))
submit=wait.until(EC.element_to_be_clickable((By.CSS_SELECTOR,'#mainsrp-pager > div > div > div > div.form > span.btn.J_Submit')))
input.clear()
input.send_keys(page)
submit.click()
wait.until(EC.text_to_be_present_in_element((By.CSS_SELECTOR,'#mainsrp-pager > div > div > div > ul > li.item.active > span'),str(page)))
wait.until(EC.presence_of_element_located((By.CSS_SELECTOR,'.m-itemlist .items .item')))
get_products()
except TimeoutException:
index_page(page)
def get_products(): #解析获取到的索引页的信息,将商品的信息从中提取出来
html=browser.page_source
doc=pq(html)
items=doc('#mainsrp-itemlist .items .item').items()
for item in items:
product= {
'image': item.find('.pic .img').attr('data-src'),
'price': item.find('.price').text(),
'deal': item.find('.deal-cnt').text(),
'title': item.find('.title').text(),
'shop': item.find('.shop').text(),
'location': item.find('.location').text()
}
print(product)
save_to_mongo(product)
def save_to_mongo(result): #定义一个存储到MONGODB数据库的方法
try:
if db[MONGO_COLLECTION].insert(result):
print('存储到Mongodb成功!')
except Exception:
print('存储到Mongodb失败!')
MAX_PAGE=100
def main(): #实现页码的遍历
for i in range(1,MAX_PAGE+1):
index_page(i)
if __name__=='__main__':
main()
4.到这里,基本就完成了利用selenium对淘宝商品进行抓取的实现,下面来看看函数运行的结果:
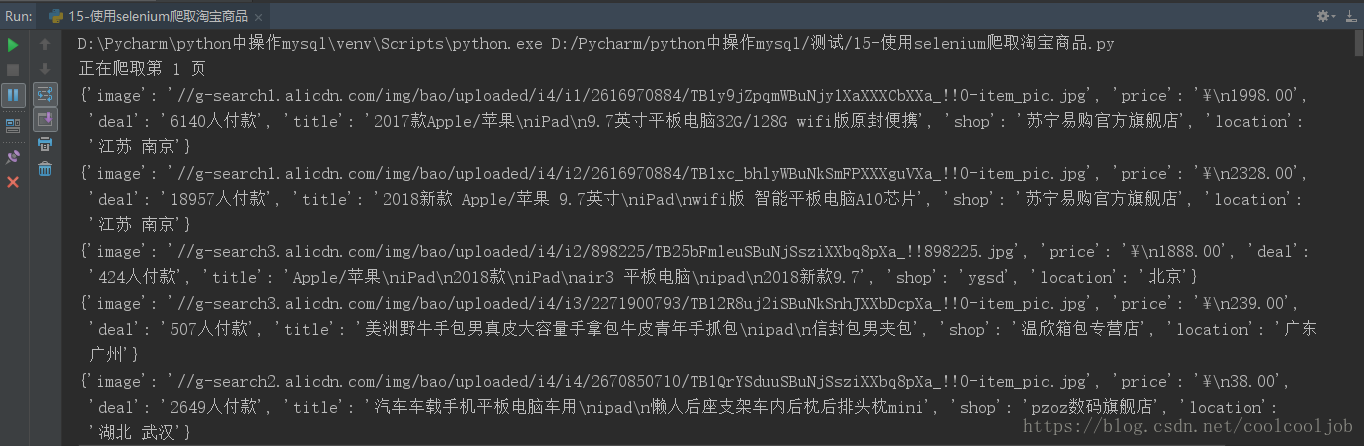
可以看到,它按照一定的规则将淘宝页面我们需要的商品信息抓取了下来,并打印了出来。