超参数的选择
1. 超参数有哪些
与超参数对应的是参数。参数是可以在模型中通过BP(反向传播)进行更新学习的参数,例如各种权值矩阵,偏移量等等。超参数是需要进行程序员自己选择的参数,无法学习获得。
常见的超参数有模型(SVM,Softmax,Multi-layer Neural Network,…),迭代算法(Adam,SGD,…),学习率(learning rate)(不同的迭代算法还有各种不同的超参数,如beta1,beta2等等,但常见的做法是使用默认值,不进行调参),正则化方程的选择(L0,L1,L2),正则化系数,dropout的概率等等。
2. 确定调节范围
超参数的种类多,调节范围大,需要先进行简单的测试确定调参范围。
2.1. 模型
模型的选择很大程度上取决于具体的实际问题,但必须通过几项基本测试。
首先,模型必须可以正常运行,即代码编写正确。可以通过第一个epoch的loss估计,即估算第一个epoch的loss,并与实际结果比较。注意此过程需要设置正则项系数为0,因为正则项引入的loss难以估算。
其次,模型必须可以对于小数据集过拟合,即得到loss接近于0,accuracy接近于1的模型。否则应该尝试其他或者更复杂的模型。
最后,如果val_acc与acc相差很小,可能是因为模型复杂度不够,需要尝试更为复杂的模型。
2.2. 学习率
loss基本不变:学习率过低
loss震动明显或者溢出:学习率过高
根据以上两条原则,可以得到学习率的大致范围。
2.3. 正则项系数
val_acc与acc相差较大:正则项系数过小
loss逐渐增大:正则项系数过大
根据以上两条原则,可以得到正则项系数的大致范围。
3. 交叉验证
对于训练集再次进行切分,得到训练集以及验证集。通过训练集训练得到的模型,在验证集验证,从而确定超参数。(选取在验证集结果最好的超参数)
3.1. 先粗调,再细调
先通过数量少,间距大的粗调确定细调的大致范围。然后在小范围内部进行间距小,数量大的细调。
3.2. 尝试在对数空间内进行调节
即在对数空间内部随机生成测试参数,而不是在原空间生成,通常用于学习率以及正则项系数等的调节。出发点是该超参数的指数项对于模型的结果影响更显著;而同阶的数据之间即便原域相差较大,对于模型结果的影响反而不如不同阶的数据差距大。
3.3. 随机搜索参数值,而不是格点搜索
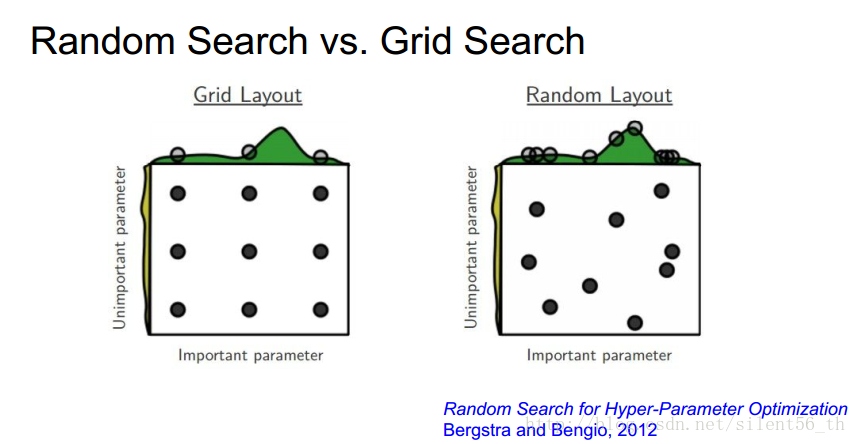
通过随机搜索,可以更好的发现趋势。图中所示的是通过随机搜索可以发现数据在某一维上的变化更加明显,得到明显的趋势。
网格搜索
网格搜索(Grid Search)名字非常大气,但是用简答的话来说就是你手动的给出一个模型中你想要改动的所用的参数,程序自动的帮你使用穷举法来将所用的参数都运行一遍。决策树中我们常常将最大树深作为需要调节的参数;AdaBoost中将弱分类器的数量作为需要调节的参数。
评分方法
为了确定搜索参数,也就是手动设定的调节的变量的值中,那个是最好的,这时就需要使用一个比较理想的评分方式(这个评分方式是根据实际情况来确定的可能是accuracy、f1-score、f-beta、pricise、recall等)
交叉验证
有了好的评分方式,但是只用一次的结果就能说明某组的参数组合比另外的参数组合好吗?这显然是不严谨的。所以就有了交叉验证这一概念。下面以K折交叉验证为例介绍这一概念。
综合格点搜素与交叉验证得到GridSearchCV
class sklearn.model_selection.GridSearchCV(estimator, param_grid, scoring=None, fit_params=None, n_jobs=1, iid=True, refit=True, cv=None, verbose=0, pre_dispatch=‘2*n_jobs’, error_score=’raise’, return_train_score=’warn’)
注意:scoring=None 默认为None, cv=None默认为None
| Parameters: | estimator : estimator object.
param_grid : dict or list of dictionaries
scoring : string, callable, list/tuple, dict or None, default: None
fit_params : dict, optional
n_jobs : int, default=1
pre_dispatch : int, or string, optional
iid : boolean, default=True
cv : int, cross-validation generator or an iterable, optional
refit : boolean, or string, default=True
verbose : integer
error_score : ‘raise’ (default) or numeric
return_train_score : boolean, optional
|
||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Attributes: | cv_results_ : dict of numpy (masked) ndarrays
best_estimator_ : estimator or dict
best_score_ : float
best_params_ : dict
best_index_ : int
scorer_ : function or a dict
n_splits_ : int
|
这里附上scoring对应的评分准则
The scoring parameter: defining model evaluation rules
| Scoring | Function | Comment |
|---|---|---|
| Classification | ||
| ‘accuracy’ | metrics.accuracy_score |
|
| ‘average_precision’ | metrics.average_precision_score |
|
| ‘f1’ | metrics.f1_score |
for binary targets |
| ‘f1_micro’ | metrics.f1_score |
micro-averaged |
| ‘f1_macro’ | metrics.f1_score |
macro-averaged |
| ‘f1_weighted’ | metrics.f1_score |
weighted average |
| ‘f1_samples’ | metrics.f1_score |
by multilabel sample |
| ‘neg_log_loss’ | metrics.log_loss |
requires predict_proba support |
| ‘precision’ etc. | metrics.precision_score |
suffixes apply as with ‘f1’ |
| ‘recall’ etc. | metrics.recall_score |
suffixes apply as with ‘f1’ |
| ‘roc_auc’ | metrics.roc_auc_score |
|
| Clustering | ||
| ‘adjusted_mutual_info_score’ | metrics.adjusted_mutual_info_score |
|
| ‘adjusted_rand_score’ | metrics.adjusted_rand_score |
|
| ‘completeness_score’ | metrics.completeness_score |
|
| ‘fowlkes_mallows_score’ | metrics.fowlkes_mallows_score |
|
| ‘homogeneity_score’ | metrics.homogeneity_score |
|
| ‘mutual_info_score’ | metrics.mutual_info_score |
|
| ‘normalized_mutual_info_score’ | metrics.normalized_mutual_info_score |
|
| ‘v_measure_score’ | metrics.v_measure_score |
|
| Regression | ||
| ‘explained_variance’ | metrics.explained_variance_score |
|
| ‘neg_mean_absolute_error’ | metrics.mean_absolute_error |
|
| ‘neg_mean_squared_error’ | metrics.mean_squared_error |
|
| ‘neg_mean_squared_log_error’ | metrics.mean_squared_log_error |
|
| ‘neg_median_absolute_error’ | metrics.median_absolute_error |
|
| ‘r2’ | metrics.r2_score |
Examples
>>> from sklearn import svm, datasets
>>> from sklearn.model_selection import GridSearchCV
>>> iris = datasets.load_iris()
>>> parameters = {'kernel':('linear', 'rbf'), 'C':[1, 10]}
>>> svc = svm.SVC()
>>> clf = GridSearchCV(svc, parameters)
>>> clf.fit(iris.data, iris.target)
...
GridSearchCV(cv=None, error_score=...,
estimator=SVC(C=1.0, cache_size=..., class_weight=..., coef0=...,
decision_function_shape='ovr', degree=..., gamma=...,
kernel='rbf', max_iter=-1, probability=False,
random_state=None, shrinking=True, tol=...,
verbose=False),
fit_params=None, iid=..., n_jobs=1,
param_grid=..., pre_dispatch=..., refit=..., return_train_score=...,
scoring=..., verbose=...)
>>> sorted(clf.cv_results_.keys())
...
['mean_fit_time', 'mean_score_time', 'mean_test_score',...
'mean_train_score', 'param_C', 'param_kernel', 'params',...
'rank_test_score', 'split0_test_score',...
'split0_train_score', 'split1_test_score', 'split1_train_score',...
'split2_test_score', 'split2_train_score',...
'std_fit_time', 'std_score_time', 'std_test_score', 'std_train_score'...]参考资料:http://www.cnblogs.com/liuyu124/p/7332594.html
https://blog.csdn.net/sinat_32547403/article/details/73008127