首先将数据集划分为训练集和测试集
进一步划分出验证集
训练集:用于建立模型,训练模型的拟合能力
测试集:用来检验最终选择最优的模型的性能
验证集:用来确定网络结构或者控制模型复杂程度的参数,即用于参数的优选
1、首先将数据集划分为训练集和测试集
留出法:直接将数据集划分为两个互斥的集合,其中一个作为训练集,另一个作为测试集
train_test_split()函数的参数说明
train_test_split(X, y, random_state = , test_size = )
1)X:表示特征集
2)y:表示对应的类别
3)random_state:随机种子
如果是数字,则其他条件不变时,每次分类的情况都相同
如果不填,每次分类的结果都不同

4)train_size:表示训练集占比,默认为0.25
5)test_size:表示测试集占比,默认为0.75
详细说明:https://www.cnblogs.com/Yanjy-OnlyOne/p/11288098.html
示例:
import numpy as np
from sklearn.model_selection import train_test_split
X = np.array([[1, 1], [2, 2], [3, 3], [4, 4]])
y = np.array([1, 2, 3, 4])
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.25, random_state = 0)
#训练集
print('X_train:')
print(X_train)
print('y_train:')
print(y_train)
#测试集
print('X_test:')
print(X_test)
print('y_test:')
print(y_test)
输出:
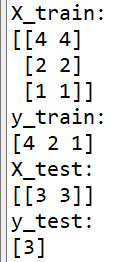
可以看出,划分后的X和y是对应的
2、基于训练集进行交叉验证
KNeighborsClassifier()函数的参数说明
KNeighborsClassifier(n_neighbors = , weights = )
1)n_neighbors:模型的k值,选取最近的k个邻居作为参考
2)weights:决策方式
有uniform(等权决策)、distance(基于距离的加权投票)
详细说明:https://blog.csdn.net/weixin_41990278/article/details/93169529
cross_val_score()函数的参数说明
cross_val_score(knn, X_train, y_train, cv = , scoring = )
1)第一个参数表示模型
2)接下来两个参数为X_train和y_train
3)cv:表示进行多少折交叉验证
4)scoring:表示评价指标
详细说明:https://blog.csdn.net/qq_36523839/article/details/80707678?utm_source=blogxgwz0
示例:
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import train_test_split,cross_val_score
#K的所有取值
K = [1, 4, 7, 10, 13, 16]
#K值对应的正确率平均值
acc = []
#K值对应的正确率标准差
std = []
#遍历可取的 k 值
for k in K:
#获得k近邻基于距离加权分类模型
knn = KNeighborsClassifier(k, weights = 'distance')
#对训练集进行4折交叉验证,获得正确率数组
score = cross_val_score(knn, X_train, y_train, cv = 5, scoring = 'accuracy')
#计算正确率的平均值
acc.append(score.mean())
#计算正确率的标准差
std.append(score.std())
#输出所有 K 值的正确率平均值
print('K值正确率平均值:', acc)
输出:

3、绘图
#添加误差线(即标准差)
for i in range(len(K)):
plt.errorbar(K[i], acc[i], fmt="bo:", yerr = std[i], capsize = 5)
#添加 K 值和对应的正确率
plt.plot(K, acc)
#添加网格
plt.grid(linestyle=':')
#设置x轴的横坐标
plt.xticks(K)
#x轴名称
plt.xlabel('K-values')
#y轴名称
plt.ylabel('Accuracy')
#绘制表格
plt.show()

因为k=1和k=10时的正确率平均值相等,此时比较标准差,选取标准差更小的10作为K值
详细说明:https://blog.csdn.net/weixin_41789707/article/details/81035997
