CS231n简介
详见 CS231n课程笔记1:Introduction。
注:斜体字用于注明作者自己的思考,正确性未经过验证,欢迎指教。
1. 超参数有哪些
与超参数对应的是参数。参数是可以在模型中通过BP(反向传播)进行更新学习的参数,例如各种权值矩阵,偏移量等等。超参数是需要进行程序员自己选择的参数,无法学习获得。
常见的超参数有模型(SVM,Softmax,Multi-layer Neural Network,…),迭代算法(Adam,SGD,…),学习率(learning rate)(不同的迭代算法还有各种不同的超参数,如beta1,beta2等等,但常见的做法是使用默认值,不进行调参),正则化方程的选择(L0,L1,L2),正则化系数,dropout的概率等等。
2. 确定调节范围
超参数的种类多,调节范围大,需要先进行简单的测试确定调参范围。
2.1. 模型
模型的选择很大程度上取决于具体的实际问题,但必须通过几项基本测试。
首先,模型必须可以正常运行,即代码编写正确。可以通过第一个epoch的loss估计,即估算第一个epoch的loss,并与实际结果比较。注意此过程需要设置正则项系数为0,因为正则项引入的loss难以估算。
其次,模型必须可以对于小数据集过拟合,即得到loss接近于0,accuracy接近于1的模型。否则应该尝试其他或者更复杂的模型。
最后,如果val_acc与acc相差很小,可能是因为模型复杂度不够,需要尝试更为复杂的模型。
2.2. 学习率
loss基本不变:学习率过低
loss震动明显或者溢出:学习率过高
根据以上两条原则,可以得到学习率的大致范围。
2.3. 正则项系数
val_acc与acc相差较大:正则项系数过小
loss逐渐增大:正则项系数过大
根据以上两条原则,可以得到正则项系数的大致范围。
3.交叉验证
对于训练集再次进行切分,得到训练集以及验证集。通过训练集训练得到的模型,在验证集验证,从而确定超参数。(选取在验证集结果最好的超参数)
交叉验证的具体实例详见CS231n作业笔记1.7:基于特征的图像分类之调参和CS231n作业笔记1.2: KNN的交叉验证。
3.1. 先粗调,再细调
先通过数量少,间距大的粗调确定细调的大致范围。然后在小范围内部进行间距小,数量大的细调。
3.2. 尝试在对数空间内进行调节
即在对数空间内部随机生成测试参数,而不是在原空间生成,通常用于学习率以及正则项系数等的调节。出发点是该超参数的指数项对于模型的结果影响更显著;而同阶的数据之间即便原域相差较大,对于模型结果的影响反而不如不同阶的数据差距大。
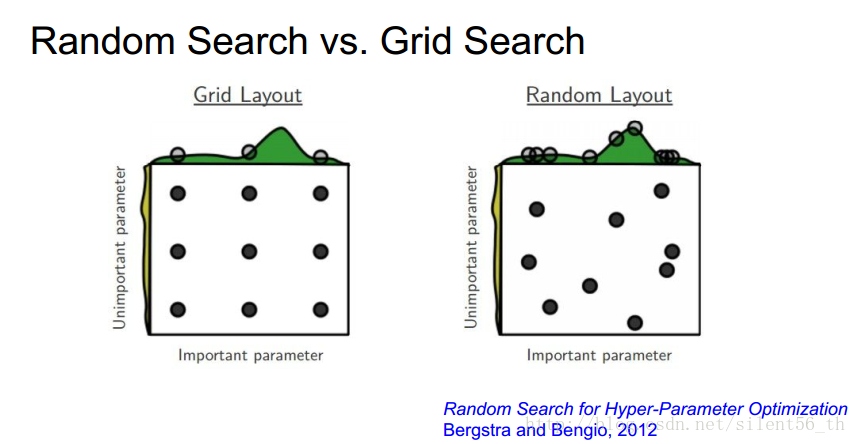
3. 随机搜索参数值,而不是格点搜索
通过随机搜索,可以更好的发现趋势。图中所示的是通过随机搜索可以发现数据在某一维上的变化更加明显,得到明显的趋势。