一、
1.什么是超参数
没接触过机器学习的人可能对这个概念比较模糊。我们可以从两方面来理解
(1)参数值的产生由来
超参数是在开始学习过程之前设置值的参数(人为设置),而不是通过训练得到的参数数据。
(2)超参数含义
-
定义关于模型的更高层次的概念,如复杂性或学习能力。
-
不能直接从标准模型培训过程中的数据中学习,需要预先定义。
-
可以通过设置不同的值,训练不同的模型和选择更好的测试值来决定
(3)举例
-
树的数量或树的深度
-
矩阵分解中潜在因素的数量
-
学习率(多种模式)
-
深层神经网络隐藏层数
-
k均值聚类中的簇数
2.交叉验证
交叉验证的目的是什么?
一般有两种:
1.我们进行学习的时候,可能会选择多种模型来训练,最后我们需要一种评判标准来选择哪种模型较好,此时就需要交叉验证
2.我们确定了某种学习模型,但可能有多组参数的选择,具体选择哪一种我们也需要交叉验证
普通的验证不行吗,为什么要交叉的?
因为数据集中某部分可能不纯(比如验证块中某些数据可能存在误差值,异常值,导致测试结果偏低,或者某些部分验证的数据过于简单,使得测试结果偏高)
关于交叉验证的具体分类和操作详见
https://zhuanlan.zhihu.com/p/24825503?refer=rdatamining
http://blog.csdn.net/linkin1005/article/details/42869331
二、
CS231n课程笔记5.4:超参数的选择&交叉验证
3.交叉验证
对于训练集再次进行切分,得到训练集以及验证集。通过训练集训练得到的模型,在验证集验证,从而确定超参数。(选取在验证集结果最好的超参数)
交叉验证的具体实例详见CS231n作业笔记1.7:基于特征的图像分类之调参和CS231n作业笔记1.2: KNN的交叉验证。
3.1. 先粗调,再细调
先通过数量少,间距大的粗调确定细调的大致范围。然后在小范围内部进行间距小,数量大的细调。
3.2. 尝试在对数空间内进行调节
即在对数空间内部随机生成测试参数,而不是在原空间生成,通常用于学习率以及正则项系数等的调节。出发点是该超参数的指数项对于模型的结果影响更显著;而同阶的数据之间即便原域相差较大,对于模型结果的影响反而不如不同阶的数据差距大。
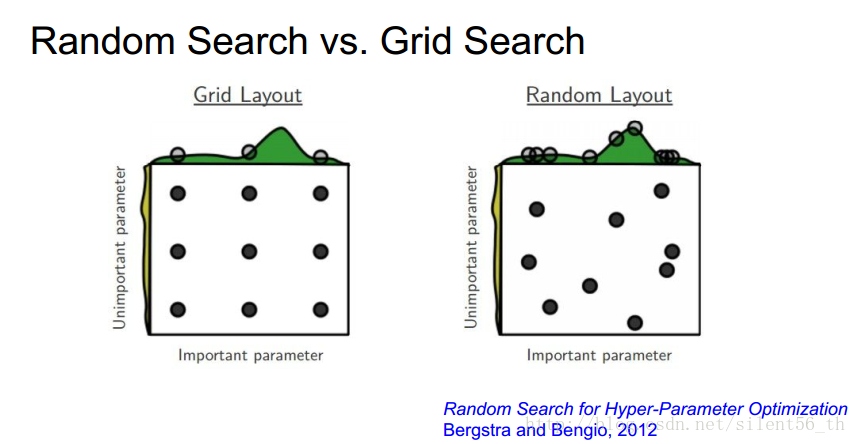
3. 随机搜索参数值,而不是格点搜索
通过随机搜索,可以更好的发现趋势。图中所示的是通过随机搜索可以发现数据在某一维上的变化更加明显,得到明显的趋势。
三、
2. 用于超参数调优的验证集
当我们在设计机器学习算法的时候,除了最终预测的时候使用测试集,其他时候都不能使用(很容易造成过拟合)。我们可以在训练集中分出一部分(50%~90%)作为验证集,在验证集上进行超参数调优。一旦找到最优的超参数,就让算法以该参数在测试集跑且只跑一次,并根据测试结果评价算法。
3. 交叉验证
当训练集数量较少时,我们一般使用交叉验证的方式(一般分为3、5、10份),比如:将训练集平均分成5份,其中4份用来训练,1份用来验证。然后我们循环着取其中4份来训练,其中1份来验证,最后取所有5次验证结果的平均值作为算法验证结果。

四、
CS231n作业笔记1.7:基于特征的图像分类之调参
https://blog.csdn.net/silent56_th/article/details/53842692