ECCV 2018

主要思路:分别对文本和图像应用attention的机制,学习比较好的文本和图像表示,然后再在共享的子空间中利用hard triplet loss度量文本和图像之间的相似性。
图像特征:采用ResNet-101的Faster R-CNN网络对每一个图像产生k个目标区域,提取每一个目标对象的特征,嵌入矩阵变换为h维的vector
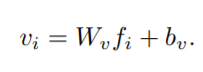

文本特征:文本的每一个word得到one-hot vector,embedding后为300维的vector,再用双向GRU得到h维的vector(bi-directional GRU)




计算每一个proposal vector和attended sentence vector之间的余弦距离,根据计算的余弦距离,再进行average polling
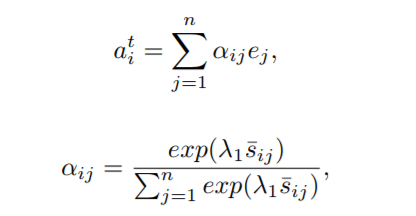
相似度(余弦相似度):

average polling:

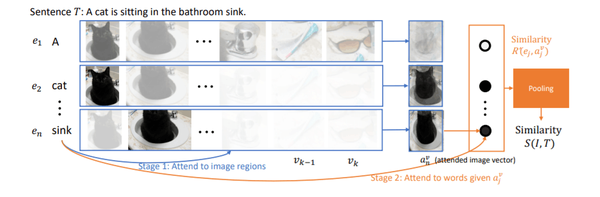
采用ResNet-101的Faster R-CNN网络对每一个图像产生多个proposal,提取每一个proposal(proposal vector,mean-pooled convolutional feature)和文本的每一个word的特征(bi-directional GRU),计算每一个word和proposal之间的余弦距离,根据计算的余弦距离,并根据权重形成image vector
同上
Loss Function
文章中用LogSumExp pooling (LSE),average pooling (AVG)和Sum-Max(SM)等方法度量sentence vector与proposal vector和image vector与word vector的相似性,然后用hard triplet loss训练

总结
先前的工作简单地聚合所有可能的区域和单词对的相似性,而对较多和不太重要的单词或区域没有进行区分。在本文中,提出Stacked Cross Attention,使用图像区域和句子中的单词作为上下文来发现完整的潜在对齐,并推断出图像 - 文本的相似性。