为什么Self-Attention要通过线性变换计算Q K V,背后的原理或直观解释是什么? - 知乎回答题主问题题主的问题: 在attention中都经过一个映射,那么建模的相似度是否就没有意义了?个人感觉这…![]() https://www.zhihu.com/question/592626839/answer/2965200007Cross-Attention in Transformer ArchitectureMerge two embedding sequences regardless of modality, e.g., image with text in Stable Diffusion U-Net.
https://www.zhihu.com/question/592626839/answer/2965200007Cross-Attention in Transformer ArchitectureMerge two embedding sequences regardless of modality, e.g., image with text in Stable Diffusion U-Net.![]() https://vaclavkosar.com/ml/cross-attention-in-transformer-architecture一言以蔽之,就是cross-attention是在sequence之间不同位置的输入做attention,self-attention是在sequence内部做attention。self和cross attention的区别仅在q和kv的来源上,self-attention Q(uery)K(ey)V(alue)均来源与一个sequence,而cross-attention中Q来源于另一个sequence,而且多为跨模态的sequence。
https://vaclavkosar.com/ml/cross-attention-in-transformer-architecture一言以蔽之,就是cross-attention是在sequence之间不同位置的输入做attention,self-attention是在sequence内部做attention。self和cross attention的区别仅在q和kv的来源上,self-attention Q(uery)K(ey)V(alue)均来源与一个sequence,而cross-attention中Q来源于另一个sequence,而且多为跨模态的sequence。


cross-attention混入了两种不同的序列。
class CrossAttention(nn.Module):
r"""
A cross attention layer.
Parameters:
query_dim (`int`): The number of channels in the query.
cross_attention_dim (`int`, *optional*):
The number of channels in the encoder_hidden_states. If not given, defaults to `query_dim`.
heads (`int`, *optional*, defaults to 8): The number of heads to use for multi-head attention.
dim_head (`int`, *optional*, defaults to 64): The number of channels in each head.
dropout (`float`, *optional*, defaults to 0.0): The dropout probability to use.
bias (`bool`, *optional*, defaults to False):
Set to `True` for the query, key, and value linear layers to contain a bias parameter.
"""
query = attn.to_q(hidden_states)
query = attn.head_to_batch_dim(query)
encoder_hidden_states = encoder_hidden_states if encoder_hidden_states is not None else hidden_states
key = attn.to_k(encoder_hidden_states)
value = attn.to_v(encoder_hidden_states)
key = attn.head_to_batch_dim(key)
value = attn.head_to_batch_dim(value)
attention_probs = attn.get_attention_scores(query, key, attention_mask)
hidden_states = torch.bmm(attention_probs, value)应用:
在transformer中有描述,但是是同模态的,还不叫cross-attention

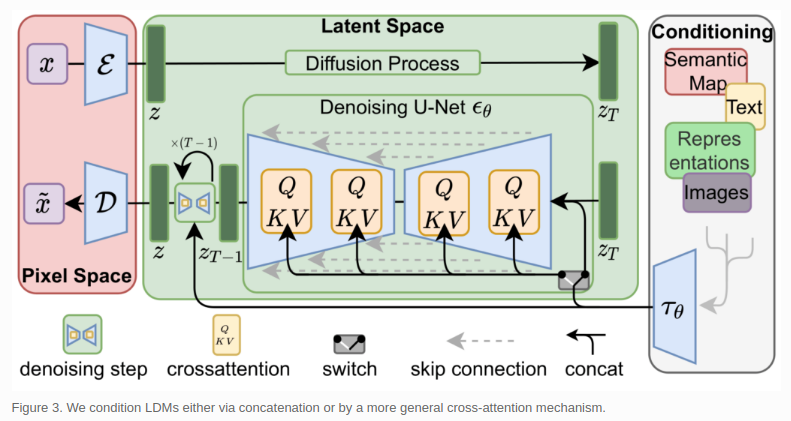
stable diffusion中:
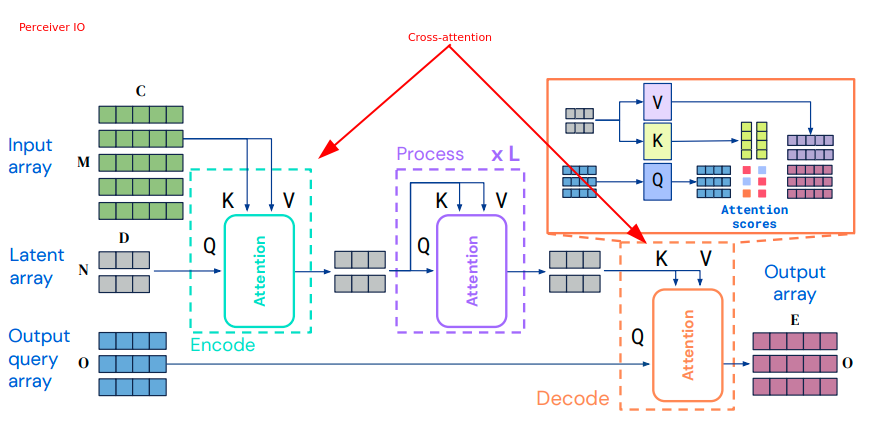
perceiver io: