how
-
下图蓝色点为待处理像素点
,处理后得到结果为红色点
:
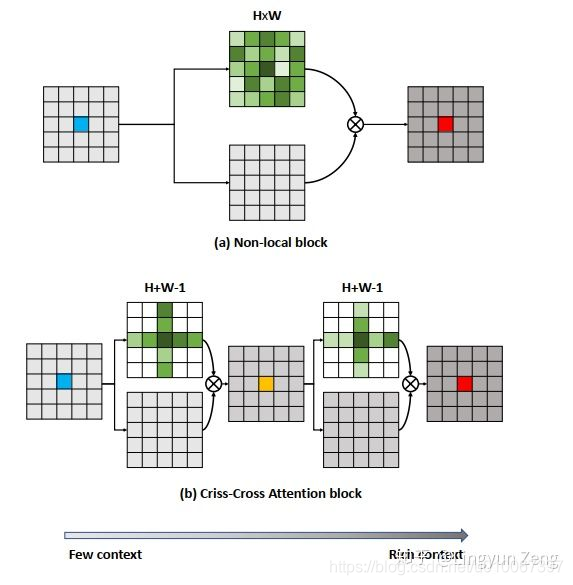
(a)是Non-local,含蓝色中心的feature map是输入,分为上下两个分支处理:
深绿色分支代表已经完成Non-local操作,得到了 (绿色的深浅则代表了当前位置与蓝色中心点的相关性大小);
下面灰色分支代表进行了 操作。将两个结果相乘,得到
(含红色中心的feature map).
(b)即为CCNet的改进,可以看到,深绿色 部分是十字型结构,意即只计算当前
周围十字型区域像素
与它的相关性。当然,我们需要知道是 所有像素 与
的相关性,于是作者将这个过程进行堆叠,并且通过实验发现,只需堆叠两次即可覆盖所有点,并超越non-local的效果。
为什么堆叠两次即可?
我们先看看信息是如何通过十字型结构传递的:
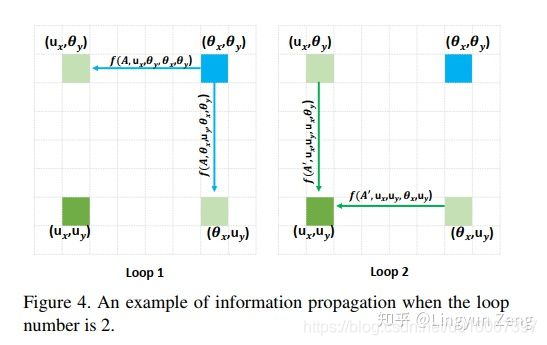
上图展示了蓝色像素点的信息传达到左下角点的过程:
第一次loop1,我们在计算左下角点的f时,只能包含左上角点和右下角点的信息,此时并没有左下角点与蓝色点的相关信息。
但在计算左上(or右下)点时,是计算了蓝色点与它们的相关性信息的。
第二次loop2,当我们再次计算左下角点的 时,再次包含左上&右下点的信息,此时的左上&右下已经不是当初那个它们了2333,它们已经有了蓝色点 的信息,此时便可以间接地将蓝色点信息传递给左下点。
同理,其他不在左下点十字型位置的像素点,都可以通过这种方式在第二次loop的时候就将信息传递给左下点。于是实现两次loop便“遍历”了所有点。
事实上,我们可以发现蓝色点信息是传递了两遍给左下点的(左上传递了一次,右下传递了一次),虽然是间接传递没有直接计算得到的结果强度大,但这种对于信息的两次加强也很有可能是最终效果 略胜于 Non-local的原因之一。
于是乎,原本需要计算 次,现在变为了
(一共
个像素点,每个点只"观照"其十字型区域
面积的像素)。计算效率大大提升!
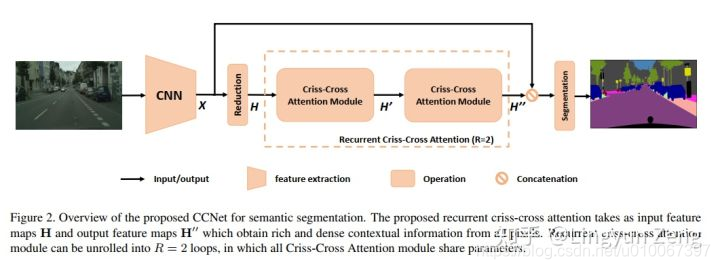
以下是CCNet的网络结构: