转载:请注明出处https://blog.csdn.net/HHTNAN
相关论文下载:cw2vec: (Learning Chinese Word Embeddings with Stroke n-gram Information)
与2016年facebook提出的论文(Enriching Word Vectors with Subword Information)直通车
全国知识图谱与语义计算大会(CCKS2018)8月14日至17日在天津举行,凭借出色的专业能力,阿里健康团队在中文电子病历命名实体识别评测任务中夺冠。
cw2vec: (Learning Chinese Word Embeddings with Stroke n-gram Information)
AAAI 2018高分录用的一篇中文词向量论文,出自蚂蚁金服人工智能部。本文将从背景知识、模型简介、c++实现、实验结果、结论等几个方面来进行阐述。
一、背景知识
目前已经存在很多的词向量模型,但是较多的词向量模型都是基于西方语言,像英语,西班牙语,德语等,这些西方语言的内部组成都是拉丁字母,然而,由于中文书写和西方语言完全不同,中文词语包含很少的中文字符,但是中文字符内部包含了很强的语义信息,因此,如何有效利用中文字符内部的语义信息来训练词向量,成为近些年研究的热点。
单个英文字符(character)是不具备语义的,而中文汉字往往具有很强的语义信息。不同于前人的工作,我们提出了“n元笔画”的概念。所谓“n元笔画”,即就是中文词语(或汉字)连续的n个笔画构成的语义结构。
问题与挑战:
自然语言处理的顶级会议ACL 2017,共提出了未来的四大研究方向,如何更好的利用“亚词”信息就是其中的一个。在中文词向量场景下,仅将中文词语拆解到汉字粒度,会一定程度上提高中文词向量的质量,是否存在汉字粒度仍不能刻画的情况?

可以看出,“木材”和“森林”是两个语义很相关的词语,但是当我们拆解到汉字粒度的时候,“木”和“材”这两个字对比“森”和“材”没有一个是相同的(一般会用一个下标去存储一个词语或汉字),因此对于这个例子而言,汉字粒度拆解是不够的。我们所希望得到的是:

“木”和“材”可以分别拆解出“木”和“木”(来源于“材”的左半边)结构,而“森”和“林”分别拆解得到多个“木”的相同结构。此外,可以进一步将汉字拆解成偏旁、字件,对于以上例子可以有效提取出语义结构信息,不过我们也分析到:

可以看出,“智”的偏旁恰好是“日”,而“日”不能表达出“智”的语义信息。实际上,偏旁的设计是为了方便在字典中查询汉字,因此结构简单、出现频率高变成了首要原则,并不一定恰好能够表达出该汉字的语义信息。此外,将“智”拆分到字件粒度,将会得到“失”,“口”和“日”三个,很不巧的是,这三个字件也均不能表达其汉字语义。我们需要设计出一种新的方法,来重新定义出词语(或汉字)具有语义的结构:
这里,“知”是可以表达出“智”语义的模块,如何得到这样的亚词结构,并结合句子上下文设计模型的优化目标,生成出更好的中文词向量,将是后文要探索的内容。
通过观察中文字符内部组成,发现中文字符包含偏旁部首、字符组件,笔画信息等语义信息特征(如下图),基于偏旁部首和汉字组件特征的中文词向量模型已经有人提出,并取得了较好的效果。
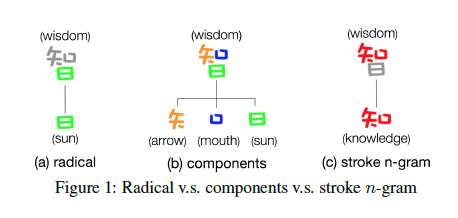
▲图1 n元笔画生成的例子
思想来源于2016年facebook提出的论文(Enriching Word Vectors with Subword Information),目前facebook这篇论文已经被引用300多次,影响力很大,cw2vec可以称之为中文版本的fasttext。
cw2vec模型
word2vec提出了CBOW和Skip-Gram两个模型(详解),cw2vec在Skip-Gram基础之上进行改进,把词语的n-gram笔画特征信息代替词语进行训练,cw2vec模型如下图。

短语:治理 雾霾 刻不容缓
中心词:雾霾
上下文词:治理,刻不容缓
如上图所示,对于“治理 雾霾 刻不容缓”这句话,假设此刻当前词语恰好是“雾霾”,上下文词语是“治理”和“刻不容缓”。首先将当前词语“雾霾”拆解成n元笔画并映射成数字编码,然后划窗得到所有的n元笔画,根据设计的Objective Function(损失函数),计算每一个n元笔画和上下文词语的相似度,进而根据损失函数求梯度并对上下文词向量和n元笔画向量进行更新。

Objective Function
在论文中提出了一种基于n元笔画的新型的损失函数,如下:
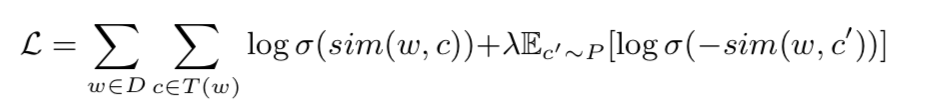
其中,和
分别为当前词语和上下文词语,
是sigmoid函数,
是当前词语划窗内的所有词语集合,
是训练语料的全部文本。为了避免传统softmax带来的巨大计算量,我们也采用了负采样的方式。
为随机选取的词语,称为“负样例”,
是负样例的个数,而
则表示负样例
按照词频分布进行的采样,其中语料中出现次数越多的词语越容易被采样到。相似性
函数被按照如下构造:
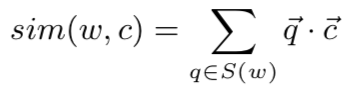
其中,为当前词语对应的一个n元笔画向量,而
是其对应的上下文词语的词向量。我们将当前词语拆解为其对应的n元笔画,但保留每一个上下文词语不进行拆解。
为词语
所对应的n元笔画的集合。在算法执行前,我们先扫描每一个词语,生成n元笔画集合,针对每一个n元笔画,都有对应的一个n元笔画向量,在算法开始之前做随机初始化,其向量维度和词向量的维度相同。
其中:sigmoid函数
论文中提及上下文词向量(context word embedding)为最终cw2vec模型的输出词向量。
n-grams特征构建的流程
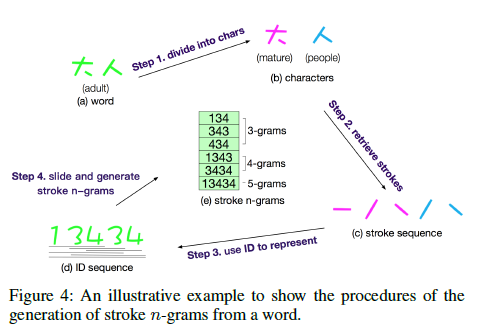
1、 词语分割
把中文词语分割为单个字符,为了获取中文字符的笔画信息。
词语:大人 分割为:(1)大 (2)人
2、 笔画特征
获取中文字符的笔画信息,并且把字符的笔画信息合并,得到词语的笔画信息。
大: 一ノ丶
人: ノ丶
大人: 一ノ丶 ノ丶
3、 笔画特征数字化
为了方便,论文提及把笔画信息数字化,用数字代表每一种笔画信息,如下图。

那么“大人”这个词的笔画信息就可以表示为:
大人: 一ノ丶 ノ丶
大人:13434
我从训练语料中获取到13354个汉字,并获取笔画信息,统计笔画种类和上图一致,只有5种笔画信息。
4、 N元笔画特征
提取词语笔画信息的n-gram特征。
3-gram:134、343、434
4-gram:1343、3434
5-gram:13434
……
上述4个步骤,如下图:
相关算法对比:

更多算法对比内容请阅读原来的paper.
参考资料:
word2vec提出了CBOW和Skip-Gram两个模型
cw2vec 一个c++版本的cw2vec github代码:
参考文献:
[1] Cao, Shaosheng, et al. “cw2vec: Learning Chinese Word Embeddings with Stroke n-gram Information.” (2018).
[2] Bojanowski, Piotr, et al. “Enriching word vectors with subword information.” arXiv preprint arXiv:1607.04606 (2016).
[3] Chen, Xinxiong, et al. “Joint Learning of Character and Word Embeddings.” IJCAI 2015.
[4] Sun, Yaming, et al. “Radical-enhanced Chinese character embedding.” ICNIP 2014.
[5] Li, Yanran, et al. “Component-enhanced Chinese character embeddings.” arXiv preprint arXiv:1508.06669 (2015).
[6] Yu, Jinxing, et al. “Joint Embeddings of Chinese Words, Characters, and Fine-grained Subcharacter Components.” EMNLP 2017.
[7] Mikolov, Tomas, et al. “Efficient estimation of word representations in vector space.” arXiv preprint arXiv:1301.3781 (2013).