word2vec原理
词袋模型(bag of word)模型是最早的以词语为基本处理单元的文本向量化方法。举个简单的例子说明下。
假设有两个文本
John likes to watch movies, mary likes too.
john also likes to watch football games.
基于文本构建词典
{‘john’:1,‘likes’:2,‘to’:3,‘watch’:4,‘movies’:5,‘also’:6,‘football’:7,‘games’:8,'mary‘:9,‘too‘:10}
有10个单词那么每个文本可以用10维向量表示。
[1,2,1,1,1,0,0,0,1,1]
[1,1,1,1,0,1,1,1,0,0]
词袋模型存在问题,维度灾难,无法保留语序问题。
词向量Word2Vec模型应用而生,Word2Vec其实就是通过学习文本来用词向量的方式表征词的语义信息,即通过一个嵌入空间使得语义上相似的单词在该空间内距离很近。Embedding其实就是一个映射,将单词从原先所属的空间映射到新的多维空间中,也就是把原先词所在空间嵌入到一个新的空间中去。
Word2Vec模型中,主要有Skip-Gram和CBOW两种模型,从直观上理解,Skip-Gram是给定input word来预测上下文。而CBOW是给定上下文,来预测input word。本篇文章仅讲解Skip-Gram模型。
Skip-Gram模型的基础形式非常简单,为了更清楚地解释模型,我们先从最一般的基础模型来看Word2Vec(下文中所有的Word2Vec都是指Skip-Gram模型)。
Word2Vec模型实际上分为了两个部分,第一部分为建立模型,第二部分是通过模型获取嵌入词向量。Word2Vec的整个建模过程实际上与自编码器(auto-encoder)的思想很相似,即先基于训练数据构建一个神经网络,当这个模型训练好以后,我们并不会用这个训练好的模型处理新的任务,我们真正需要的是这个模型通过训练数据所学得的参数,例如隐层的权重矩阵——后面我们将会看到这些权重在Word2Vec中实际上就是我们试图去学习的“word vectors”。基于训练数据建模的过程,我们给它一个名字叫“Fake Task”,意味着建模并不是我们最终的目的。

The Fake Task
我们在上面提到,训练模型的真正目的是获得模型基于训练数据学得的隐层权重。为了得到这些权重,我们首先要构建一个完整的神经网络作为我们的“Fake Task”,后面再返回来看通过“Fake Task”我们如何间接地得到这些词向量。
接下来我们来看看如何训练我们的神经网络。假如我们有一个句子“The dog barked at the mailman”。
首先我们选句子中间的一个词作为我们的输入词,例如我们选取“dog”作为input word;
有了input word以后,我们再定义一个叫做skip_window的参数,它代表着我们从当前input word的一侧(左边或右边)选取词的数量。如果我们设置skip_window=2,那么我们最终获得窗口中的词(包括input word在内)就是[‘The’, ‘dog’,‘barked’, ‘at’]。skip_window=2代表着选取左input word左侧2个词和右侧2个词进入我们的窗口,所以整个窗口大小span=2x2=4。另一个参数叫num_skips,它代表着我们从整个窗口中选取多少个不同的词作为我们的output word,当skip_window=2,num_skips=2时,我们将会得到两组 (input word, output word) 形式的训练数据,即 (‘dog’, ‘barked’),(‘dog’, ‘the’)。
神经网络基于这些训练数据将会输出一个概率分布,这个概率代表着我们的词典中的每个词是output word的可能性。这句话有点绕,我们来看个栗子。第二步中我们在设置skip_window和num_skips=2的情况下获得了两组训练数据。假如我们先拿一组数据 (‘dog’, ‘barked’) 来训练神经网络,那么模型通过学习这个训练样本,会告诉我们词汇表中每个单词是“barked”的概率大小。
模型的输出概率代表着到我们词典中每个词有多大可能性跟input word同时出现。举个栗子,如果我们向神经网络模型中输入一个单词“Soviet“,那么最终模型的输出概率中,像“Union”, ”Russia“这种相关词的概率将远高于像”watermelon“,”kangaroo“非相关词的概率。因为”Union“,”Russia“在文本中更大可能在”Soviet“的窗口中出现。我们将通过给神经网络输入文本中成对的单词来训练它完成上面所说的概率计算。下面的图中给出了一些我们的训练样本的例子。我们选定句子“The quick brown fox jumps over lazy dog”,设定我们的窗口大小为2(window_size=2),也就是说我们仅选输入词前后各两个词和输入词进行组合。下图中,蓝色代表input word,方框内代表位于窗口内的单词。

模型细节
我们如何来表示这些单词呢?首先,我们都知道神经网络只能接受数值输入,我们不可能把一个单词字符串作为输入,因此我们得想个办法来表示这些单词。最常用的办法就是基于训练文档来构建我们自己的词汇表(vocabulary)再对单词进行one-hot编码。
假设从我们的训练文档中抽取出10000个唯一不重复的单词组成词汇表。我们对这10000个单词进行one-hot编码,得到的每个单词都是一个10000维的向量,向量每个维度的值只有0或者1,假如单词ants在词汇表中的出现位置为第3个,那么ants的向量就是一个第三维度取值为1,其他维都为0的10000维的向量(ants=[0, 0, 1, 0, …, 0])。
还是上面的例子,“The dog barked at the mailman”,那么我们基于这个句子,可以构建一个大小为5的词汇表(忽略大小写和标点符号):(“the”, “dog”, “barked”, “at”, “mailman”),我们对这个词汇表的单词进行编号0-4。那么”dog“就可以被表示为一个5维向量[0, 1, 0, 0, 0]。
模型的输入如果为一个10000维的向量,那么输出也是一个10000维度(词汇表的大小)的向量,它包含了10000个概率,每一个概率代表着当前词是输入样本中output word的概率大小。
隐层没有使用任何激活函数,但是输出层使用了sotfmax。
我们基于成对的单词来对神经网络进行训练,训练样本是 ( input word, output word ) 这样的单词对,input word和output word都是one-hot编码的向量。最终模型的输出是一个概率分布。
隐层
说完单词的编码和训练样本的选取,我们来看下我们的隐层。如果我们现在想用300个特征来表示一个单词(即每个词可以被表示为300维的向量)。那么隐层的权重矩阵应该为10000行,300列(隐层有300个结点)。
Google在最新发布的基于Google news数据集训练的模型中使用的就是300个特征的词向量。词向量的维度是一个可以调节的超参数(在Python的gensim包中封装的Word2Vec接口默认的词向量大小为100, window_size为5)。
看下面的图片,左右两张图分别从不同角度代表了输入层-隐层的权重矩阵。左图中每一列代表一个10000维的词向量和隐层单个神经元连接的权重向量。从右边的图来看,每一行实际上代表了每个单词的词向量。
所以我们最终的目标就是学习这个隐层的权重矩阵。
我们现在回来接着通过模型的定义来训练我们的这个模型。

回顾一下,你可能会问:one-hot向量大多数都是0,这种表示有什么用呢?如果你将110000的向量乘以10000300的矩阵,就相当于找出这个矩阵中对应的1*10000向量中”1“所在位置的行。
也就是隐藏层就相当于一个查找表,输出输入词对应的词向量。

输出层:
隐藏层输出的1*300的词向量输入输出层,输出层是一个softmax分类器,输出层的每个神经元会输出一个在0,1之间的值,且所有神经元输出的和为1。
每个输出神经元会有一个权重向量,用来乘以隐藏层输出的词向量,然后计算相乘后的结果的指数,exp(相乘后的结果)。最后,为了使所有输出的和为1,除以这10000个输出的和。
word2vec实现(tensorflow版)
tensorflow版代码在github上有,再来感受下它的具体实现过程。
由于Keras 很难直接打印中间层参数,故舍弃写Keras版。
第一步.导入包
import tensorflow as tf
import matplotlib.pyplot as plt
import matplotlib; matplotlib.use('TkAgg')
from pylab import *
mpl.rcParams['font.sans-serif'] = ['SimHei']
mpl.rcParams['axes.unicode_minus'] = False
import numpy as np
tf.reset_default_graph()
第二步.导入文本
sentences = [ "i like dog", "i like cat", "i like animal",
"dog cat animal", "apple cat dog like", "dog fish milk like",
"dog cat eyes like", "i like apple", "apple i hate",
"apple i movie book music like", "cat dog hate", "cat dog like"]
第三步:文本预处理
word_sequence = " ".join(sentences).split()#得到所有词汇
word_list = " ".join(sentences).split()
word_list = list(set(word_list))#词汇去重
#字典
word_dict = {w: i for i, w in enumerate(word_list)}
其中
word_list
[‘milk’, ‘i’, ‘like’, ‘dog’, ‘fish’, ‘hate’, ‘music’, ‘eyes’, ‘cat’, ‘animal’, ‘movie’, ‘apple’, ‘book’]
word_dict
{‘animal’: 0, ‘dog’: 1, ‘apple’: 2, ‘i’: 3, ‘cat’: 4, ‘milk’: 5,
‘movie’: 6, ‘like’: 7, ‘fish’: 8, ‘book’: 9, ‘music’: 10, ‘hate’: 11, ‘eyes’: 12}
第四步:参数设置
batch_size = 20#随机选取的数量,为后面训练多轮,每轮选择的个数
embedding_size = 2 # To show 2 dim embedding graph,词向量为2维
voc_size = len(word_list)#13个单词,词汇量个数
第5步:skip gram
skip_grams = []
for i in range(1, len(word_sequence) - 1):#除掉第一个字和最后一个字
target = word_dict[word_sequence[i]]#得到目标字
context = [word_dict[word_sequence[i - 1]], word_dict[word_sequence[i + 1]]]#上下文字,word_dict为字典{词:数字}
for w in context:
skip_grams.append([target, w])#得到[目标字,上一个字],[目标字,下一个字] 即类似[[1, 3], [1, 9],
第6步:skip gram 得到的数组,目标字和上下文 one-hot化。
其中的np.random.choice为后面每轮选取样本时用到。每轮随机选择size个skip gram样本,对这size个skip gram样本进行标签和上下文One-hot化。这np.random.choice可以不要的,表示不进行多轮,直接输出全部skip gram 的one-hot标签,那i应该是data的行数
#one-hot标签化
def random_batch(data, size):
random_inputs = []
random_labels = []
np.random.seed(1)
random_index = np.random.choice(range(len(data)), size, replace=False)#从生成的skip_grams词语对里,随机抽取size个
for i in random_index:
random_inputs.append(np.eye(voc_size)[data[i][0]]) # target
random_labels.append(np.eye(voc_size)[data[i][1]]) # context word
return random_inputs, random_labels
其中的random_inputs类似

random_label类似

第7步:模型
# Model
inputs = tf.placeholder(tf.float32, shape=[None, voc_size])#one-hot数组
labels = tf.placeholder(tf.float32, shape=[None, voc_size])#one-hot数组
# W and WT is not Traspose relationship
W = tf.Variable(tf.random_uniform([voc_size, embedding_size], -1.0, 1.0))
WT = tf.Variable(tf.random_uniform([embedding_size, voc_size], -1.0, 1.0))
hidden_layer = tf.matmul(inputs, W) # [batch_size, embedding_size]
output_layer = tf.matmul(hidden_layer, WT) # [batch_size, voc_size]
cost = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits_v2(logits=output_layer, labels=labels))
optimizer = tf.train.AdamOptimizer(0.001).minimize(cost)
第8步:训练,我们取出中间层权重w
with tf.Session() as sess:
init = tf.global_variables_initializer()
sess.run(init)
for epoch in range(5000):
batch_inputs, batch_labels = random_batch(skip_grams, batch_size)
_, loss = sess.run([optimizer, cost], feed_dict={inputs: batch_inputs, labels: batch_labels})
if (epoch + 1)%1000 == 0:
print('Epoch:', '%04d' % (epoch + 1), 'cost =', '{:.6f}'.format(loss))
trained_embeddings = W.eval()
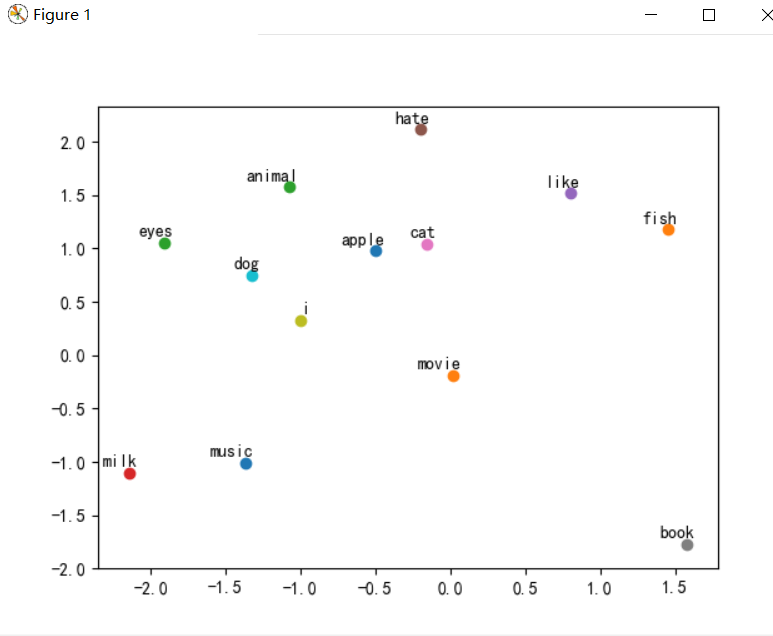
第9步:可视化
w行为单词个数,列为可视化维度数。
for i, label in enumerate(word_list):
x, y = trained_embeddings[i]
plt.scatter(x, y)
plt.annotate(label, xy=(x, y), xytext=(5, 2), textcoords='offset points', ha='right', va='bottom')
plt.show()
word2vec gensim使用
官网文档https://radimrehurek.com/gensim/models/word2vec.html
网址为:
http://radimrehurek.com/gensim/
gensim的安装非常简单:
pip install --upgrade gensim
训练方式:
import gensim
from gensim.models import word2vec
sentences = [['first', 'sentence'], ['second', 'sentence']]#分词后的数据
model = gensim.models.Word2Vec(sentences, min_count=1,size=2)
print (model['first'] )
结果
sentences为分好的词

其中Word2Vec有很多可以影响训练速度和质量的参数。第一个参数可以对字典做截断,少于min_count次数的单词会被丢弃掉, 默认值为5:
model = Word2Vec(sentences, min_count=10)
另外一个是神经网络的隐藏层的单元数,推荐值为几十到几百。事实上Word2Vec参数的个数也与神经网络的隐藏层的单元数相同,比如size=200,那么训练得到的Word2Vec参数个数也是200:
model = Word2Vec(sentences, size=200)
初始化Word2Vec对象,设置神经网络的隐藏层的单元数为200,生成的词向量的维度也与神经网络的隐藏层的单元数相同。设置处理的窗口大小为8个单词,出现少于10次数的单词会被丢弃掉,迭代计算次数为10次,同时并发线程数与当前计算机的cpu个数相同:
model=gensim.models.Word2Vec(size=200, window=8, min_count=10, iter=10, workers=cores)
模型应用
匹配关系
此处叙述如何寻找匹配关系。所谓匹配关系,是指针对A和B之间的关系(A, B),如果给定C,求D,使得C和D之间的关系(C, D)是同性质的。例如中most_similar中所举的示例:topn表示结果个数
model.most_similar(positive=[‘woman’, ‘king’], negative=[‘man’], topn=1)
结果:[(‘queen’, 0.50882536)]
使用方法
items = model.most_similar(positive=[u’黄蓉’, u’杨过’], negative=[u’小龙女’])
forr,s in items:
if r in names:
print r, s
得到的结果为:
郭芙0.888121366501
郭靖0.8785790205
model.most_similar(positive=[‘woman’, ‘king’], negative=[‘man’], topn=1)
[(‘queen’, 0.50882536)]
计算两个词的相似度
model.similarity(‘woman’, ‘man’)
.73723527
词向量查询
model[‘first’]
模型保存与载入
model.save(‘word2vec_model’)
new_model=gensim.models.Word2Vec.load(‘word2vec_model’)
基于word2vec的文本分类
keras版代码
见链接:
基于词向量word2vec模型的文本分类实现(算例有代码)

大家好,我是余登武。看到这里说明你觉得本文对你有用,请点个赞支持下,谢谢。
