提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
前言
提示:这里可以添加本文要记录的大概内容:
例如:随着人工智能的不断发展,机器学习这门技术也越来越重要,很多人都开启了学习机器学习,本文就介绍了机器学习的基础内容。
提示:以下是本篇文章正文内容,下面案例可供参考
一、词向量
自然语言处理(NLP),要将自然语言交给机器学习中的算法来处理,通常需要将语言数学化。而词向量就是用来将语言中的词进行数学化的一种方式。
这其中,主要有两种表示方式
- One-Hot Representation
- Distributed Representation
1.1 One-Hot
One-Hot(独热编码)是一种最简单的编码方式。
就是用一个很长的向量来表示一个词,向量的长度为词典的大小,向量的分量只有一个1,其他全为0。
这种方式采用系数存储,非常简洁,也非常易于实现,但是它有如下两个缺点。
1.容易受维数灾难的困扰,当你的词典很大时,你的词向量的维度就会非常大。
2.不能很好的刻画词与词之间的相似性。
1.2 Distributed Representation
其基本想法是直接用一个普通的向量表示一个词(即用低维来表征一个词)。
当时这样的一种表示方式需要经过一番的训练。
这种方式得到的词向量一般是有空间上的意义的,也就是说,在这个空间上的词向量之间的距离度量也可以表示对应的两个词之间的“距离”。
二、语言模型
语言模型形式化的描述就是给定一个 T 个词的字符串 s,看它是自然语言的概率P(w1,w2,„,wt)。w1 到 wT 依次表示这句话中的各个词。
如果这个概率特别低,说明这句话不常出现,那么就不算是一句自然语言,因为在语料库里面很少出现。如果出现的概率高,就说明是一句自然语言。
2.1 N-gram模型
语言模型要求计算时需要考虑该词语前的所有词,但是N-Gram则是只考虑前n个词。
由此也就表示n的取值会影响到效果。
一般而言,我们考虑n取3左右。
当然N-gram也有它的局限性
1、n 不能取太大,取大了语料库经常不足,所以基本是用降级的方法
2、无法建模出词之间的相似度,就是有两个词经常出现在同一个 context后面,但是模型是没法体现这个相似性的。
3、有些 n 元组(n 个词的组合,跟顺序有关的)在语料库里面没有出现过,对应出来的条件概率就是 0,这样一整句话的概率都是 0 了,这是不对的,解决的方法主要是两种:平滑法(基本上是分子分母都加一个数)和回退法(利用 n-1 的元组的概率去代替 n 元组的概率)
2.2 N-pos 模型
由于在实际情况中,许多词是条件依赖于它前面的词的语法功能的,所以,N-pos模型即是先对词按照词性进行分类,然后计算P。
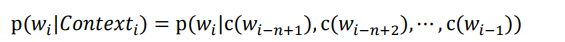
其中C是类别映射函数。由此会减少模型的计算量。
2.3 模型的问题与目标
由于很多方法都是通过硬统计来得到最后结果,又或者比如使用trigram还需要存储一个巨大的元组和概率的映射,这会需要非常大的内存,于是很多科学家想要通过利用函数来拟合计算p。
而拟合的方式中就有神经网络,word2vec就是其中一个方法。