本文翻译和精简自Stanford cs224n lec1+lec2,以及THU 2020信息检索课件。
1. 如何表示词语的含义?
1.1 Wordnet
wordnet依靠专家的知识,建立了同义词(synonym)和IS-A关系词(hypernym).使用方法:见https://blog.csdn.net/King_John/article/details/80252594
但是,wordnet的缺点是显而易见的。
- 不能把握词语细微的差别。如"proficient"和"good"在wordnet中是同义词,但是它们在不同语境下意思未必完全一样。
- 不能与时俱进,一些新词语的含义根本就没有。比如"wizard",“ninja”,“ipad”
- 需要大量的专家人力来完成,而且主观性很强
- 不能够比较词语的相似性,这是非常致命的一点。
1.2 离散式语义(bag of words, 2012年以前)
在传统NLP中,每个词被看作一个离散的symbol,这就是 localist representation.每个词都可以被表示成一个one-hot向量,如:
m o t e l = [ 0 , 0 , 0 , 0 , 0 , 0 , 0 , 1 , 0 , 0 , 0 , 0 ] h o t e l = [ 0 , 0 , 1 , 0 , 0 , 0 , 0 , 0 , 0 , 0 , 0 , 0 ] motel = [0,0,0,0,0,0,0,1,0,0,0,0]\\ hotel = [0,0,1,0,0,0,0,0,0,0,0,0] motel=[0,0,0,0,0,0,0,1,0,0,0,0]hotel=[0,0,1,0,0,0,0,0,0,0,0,0]
向量的维度就是词汇表vocab的大小,比如500000维。
离散式语义的致命缺点:
- 语料稍微大一点,词语对应的矩阵就会非常大且稀疏。
- 不能衡量两个词语之间的相似度。从"motel"和"hotel"的例子中可以看出,每两个词语的表示都是正交的,也就是similarity=0. 这显然是很糟糕的。比如,我们在搜索"Seattle motel"的时候,也希望能显示"Seattle hotel"的结果。
1.3 分布式语义(distributed representation, representing words by their context)
分布式语义的意思是:一个词语的含义是由它周围的词来决定的(a word’s meaning is given by the words that frequently appear close-by)。
分布式的意思也意味着,一个dense vector的每一位可以表示多个特征、一个特征也可以由很多位来表示。

我们将每个词语都表示成一个dense vector,使得周围词(context word)相近的两个词的dense vector也相似。这样就可以衡量词语的相似性了。

一个好的词语表示能够把握住词语的syntactic(句法,如主谓宾)与semantic(词语的语义含义)信息,例如,一个优秀的词语表示可以做到:
- WR(“China”) - WR(“Beijing”) + WR(“Tokyo”) = WR(“Japan”)
- WR(“King”) - WR(“Queen”) + WR(“Woman”) = WR(“Man”)
2. Word2vec
2.1 概述
Word2vec (Mikolov et al. 2013)是学习词向量的一种方法。
思想:
-
我们有一个非常大的语料,需要把这个语料中的每个词表示成词向量
-
遍历语料的每个位置 t,都有一个中心词 c(center word)和周围词 o(context word, 原谅我真的不知道咋翻译…)。算法刚开始的时候,每个词的词向量都随机初始化。
-
计算给定周围词o的条件下中心词为c的概率,即 p ( c ∣ o ) p(c|o) p(c∣o), 这就是CBOW(continuous bag of words)的思想;或者相反,计算给定中心词c的条件下周围词为o的概率,这就是skip-gram的思想。

-
一直调整每个词的词向量,使得上面说的这个概率最大。
例如:
计算 P ( w t + j ∣ w t ) P(w_{t+j}|w_t) P(wt+j∣wt):
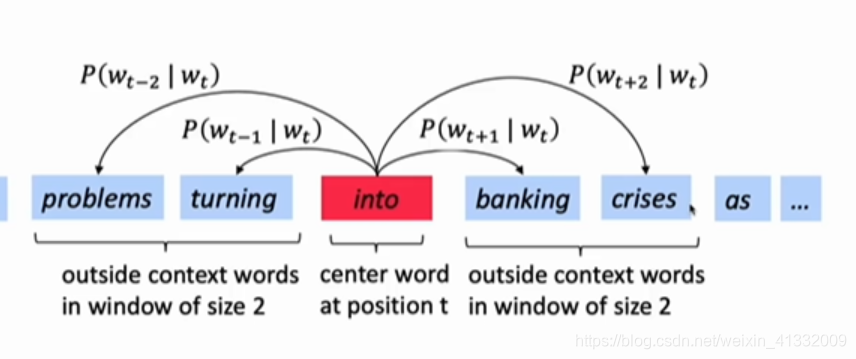
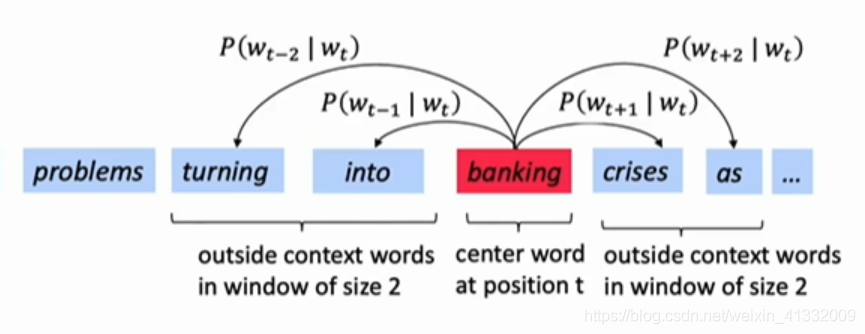
对于语料的每一个位置,都计算一遍窗口大小范围内的 P ( w t + j ∣ w t ) P(w_{t+j}|w_t) P(wt+j∣wt):
2.2 word2vec的目标函数
2.2.1 目标函数的表示
对于语料库中的每一个位置 t = 1 , 2 , . . . T t= 1,2,...T t=1,2,...T, 都计算一下给定中心词 w j w_j wj的条件下,窗口大小为m的周围词出现的概率。这个概率(也叫似然度)就是:

损失函数就是:
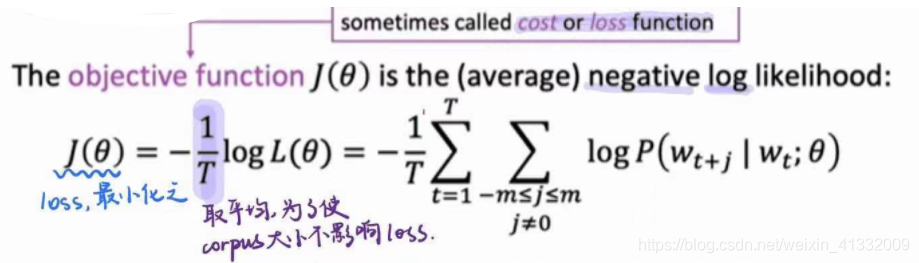
最小化损失函数就相当于最大化概率。
2.2.2 如何计算目标函数
上文已经推导过了,损失函数为
J ( θ ) = − 1 T ∑ t = 1 T ∑ − m ≤ j ≤ m , j ≠ 0 l o g P ( w t + j ∣ w t ; θ ) J(\theta) = -\frac{1}{T} \sum_{t=1}^T \sum_{-m \leq j \leq m, j \neq 0} log P(w_{t+j}|w_t;\theta) J(θ)=−T1t=1∑T−m≤j≤m,j=0∑logP(wt+j∣wt;θ)
那么如何计算 l o g P ( w t + j ∣ w t ; θ ) log P(w_{t+j}|w_t;\theta) logP(wt+j∣wt;θ)呢?
解决办法是,我们为每个词语 w 都训练两个向量:
- v w v_w vw是当w为中心词时,w的表示向量
- u w u_w uw是当w为周围词时,w的表示向量
最后的词向量结果可以是 v w v_w vw和 u w u_w uw的平均。
那么,对于一个中心词 c 和周围词 o,有:
P ( o ∣ c ) = e u o T v c ∑ w ∈ V o c a b e u w T v c P(o|c) = \frac{e^{u_o^Tv_c}}{\sum _{w \in Vocab} e^{u_w^Tv_c}} P(o∣c)=∑w∈VocabeuwTvceuoTvc
其中, u o u_o uo就是 o 作为周围词时的向量表示, v c v_c vc就是c作为中心词时的向量表示。
- 点乘实际上是衡量了 u o u_o uo和 v c v_c vc的相似度,因为 u o T v c = ∑ i = 1 n u o i v c i u_o^Tv_c= \sum_{i=1}^n u_{o_i}v_{c_i} uoTvc=∑i=1nuoivci。也就是说, u o u_o uo和 v c v_c vc越相近,这个点乘的值越大。
- 求指数是为了保证值为正数
- 分母就是对词汇表中所有的词求和,是为了归一化,使这个概率位于[0,1]区间
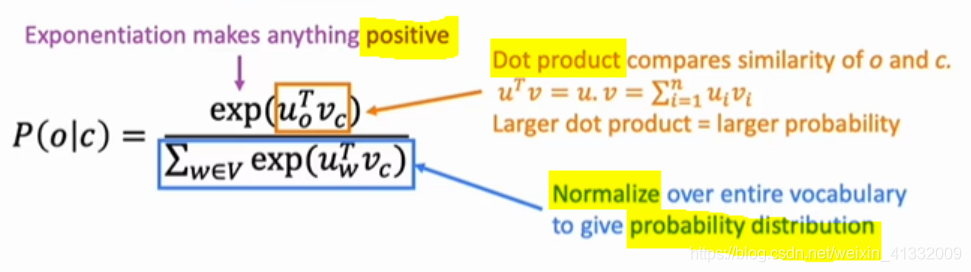
这个概率 P ( o ∣ c ) P(o|c) P(o∣c)的计算方法是一个典型的softmax方法
【softmax】
s o f t m a x ( x i ) = e x p ( x i ) ∑ j = 1 n e x p ( x j ) = p i softmax(x_i) = \frac{exp(x_i)}{\sum_{j=1}^n exp(x_j)} = p_i softmax(xi)=∑j=1nexp(xj)exp(xi)=pi
softmax函数把任意的一个实数值 x i x_i xi都能变成概率 p i p_i pi.
softmax 的名字包含两种含义:
- “max”表示它使最大的值更加放大(exp函数特点)
- 对于那些不是最大值的值,softmax也给了它们一定的小值,而不是像hardmax那样采用one-hot编码,让非最大值的值都为0.
2.2.3 梯度下降 训练模型
为了训练模型,需要每一步调整参数使得loss最小化。这里说的参数,实际上就是每个词语的词向量表示:
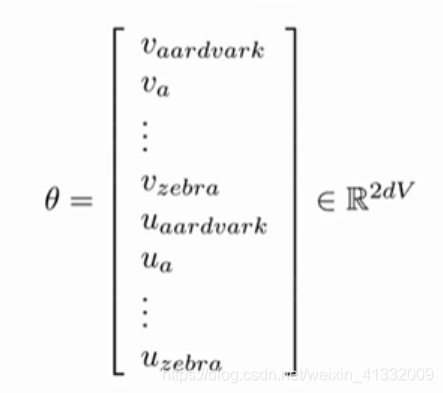
参数的维度是 2 d V 2dV 2dV,是因为每个词语都有两个表示(作为中心词时的 v w o r d v_{word} vword、作为周围词时的 u w o r d u_{word} uword),每个表示的维度为d。总共有V个词语,所以,总共需要有 2 d V 2dV 2dV 个参数。
使用随机梯度下降法(SGD)来更新参数,损失函数 J ( θ ) J(\theta) J(θ)关于参数 θ \theta θ的梯度为:

这是因为如果采用随机梯度下降法(小批量梯度下降法也会遇到这个问题),每次只考虑一个位置 t,这样只会更新2m+1个词语的词向量,m为窗口大小。这样,梯度是一个非常稀疏的向量!
解决这个问题的方法是:由于每次只会更新我们这轮迭代见到的2m+1个词语的词向量,其他词语的词向量根本不会发生变化,所以可以维护一个词语->词向量的哈希,这样每次只改变那2m+1个词语的词向量就可以了。尤其是当我们有非常多的词语的时候,绝对不能每次都传一个巨大的、稀疏的梯度向量!
2.2.4 Skip-gram 模型的优化 – negative sampling
skip-gram模型就是我们一直在讲的方法,即在给定中心词 c 的条件下,求周围词 o 出现的概率,并不断调整模型参数使得这个概率最大化的一种方法。
之前我们用朴素的softmax来衡量每个周围词 o 出现的概率,分母是vocab中所有词语的概率总和:
P ( o ∣ c ) = e u o T v c ∑ w ∈ V o c a b e u w T v c P(o|c) = \frac{e^{u_o^Tv_c}}{\sum _{w \in Vocab} e^{u_w^Tv_c}} P(o∣c)=∑w∈VocabeuwTvceuoTvc这显然需要太长的时间来计算,因为词汇表中的词语实在是太多了!所以,实际上我们使用negative sampling的方法。
【negative sampling】
每一个位置 t 的损失函数为:
J t ( θ ) = l o g σ ( u o T v c ) + ∑ j = 1 k l o g σ ( − u j T v c ) J_t(\theta) = log \sigma (u_o^T v_c) + \sum_{j=1}^k log \sigma(-u_j^Tv_c) Jt(θ)=logσ(uoTvc)+j=1∑klogσ(−ujTvc)
第一项 l o g σ ( u o T v c ) log \sigma (u_o^T v_c) logσ(uoTvc)是中心词c的周围出现了真正的周围词 o的概率,需最大化之。
第二项 ∑ j = 1 k l o g σ ( − u j T v c ) \sum_{j=1}^k log \sigma(-u_j^Tv_c) ∑j=1klogσ(−ujTvc)中的 u j u_j uj就是随机抽的词语的词向量。我们按照词频随机抽取k个这样的随机词。抽到每个词的概率为 P ( w ) = U ( w ) 3 4 / Z P(w) = U(w)^{\frac{3}{4}}/Z P(w)=U(w)43/Z, 其中U(w)为该词语出现的词频,Z是归一化项。我们需要最小化中心词c的周围出现这种随机词的概率,所以要最小化 ∑ j = 1 k l o g σ ( u j T v c ) \sum_{j=1}^k log \sigma(u_j^Tv_c) ∑j=1klogσ(ujTvc)使用negative sampling的方法,每次只需采样k个负样本,并不需要计算所有词汇表中的 u w T v c u_w^Tv_c uwTvc,大大节省了计算时间。
2.2.5 Continuous bag of words (CBOW)的优化
已知窗口中的一些周围词,计算中心词为 c 的概率,并最大化之。根据bag of words假设,周围词出现的顺序不会影响它们预测中心词的结果。
对于CBOW,
-
输入层是周围词的词向量(什么!我们不是在训练词向量吗?不不不,我们是在训练CBOW模型,词向量只是个副产品,确切来说,是CBOW模型的一个参数。训练开始的时候,词向量是个随机值,随着训练的进行不断被更新)。
-
投影层对其求和,所谓求和,就是简单的向量加法。
-
输出层输出最可能的w, 就是取softmax。由于语料库中词汇量是固定的|V|个,所以上述过程其实可以看做一个多分类问题。给定特征,从|V|个分类中挑一个。
对于神经网络模型多分类,最朴素的做法是softmax回归,但是softmax回归需要对语料库中每个词语都计算一遍输出概率并进行归一化,在几十万词汇量的语料上无疑是令人头疼的。所以可以使用hierarchical clustering的方法:
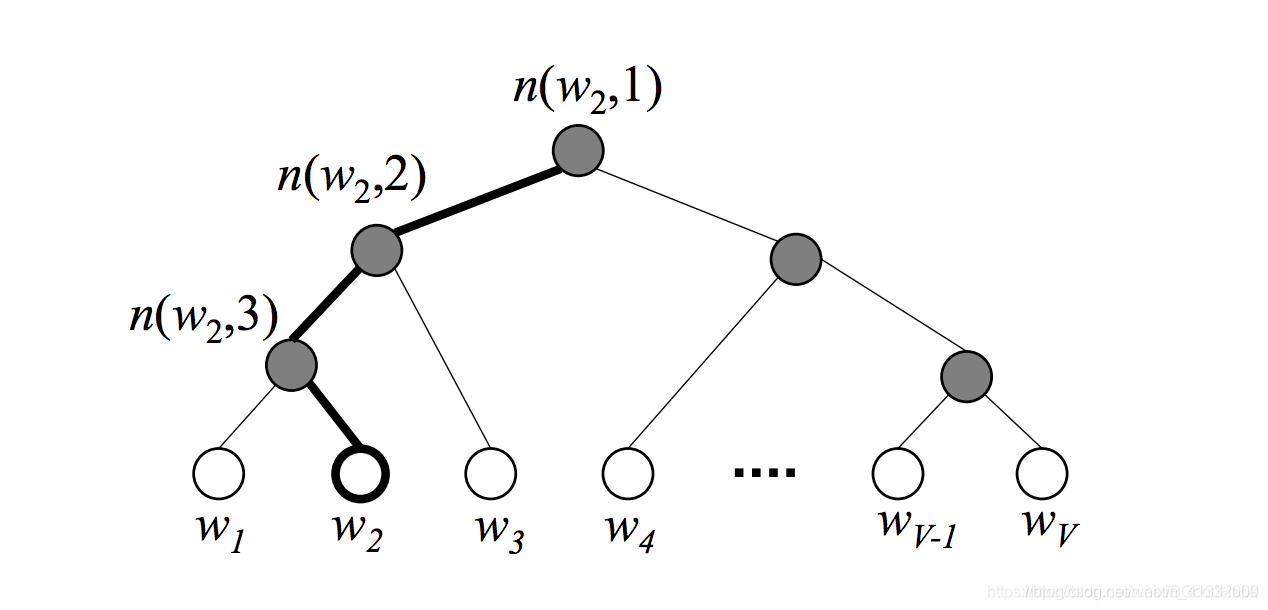
如果已知周围词context去求中心词word的概率p直接用softmax的话,需要计算所有词与周围词的内积,运算量是很大的。反之,如果构建一个huffman tree,每次进行一次二分,那么求p的话只需要沿着路径从根节点到指向这个词word的叶子节点,把一路上的概率相乘即可,运算量上小了许多,变成了O(log(V)).
2.2.6 word2vec的一些trick
- 因为罕见词会表示更多、更独特的信息,所以应该更加关注罕见词、不要过度关注常见词。因此,可以对词语进行欠采样,以 1 − t / f ( w ) 1-\sqrt{t/f(w)} 1−t/f(w)的概率丢弃词语 w, 其中 f ( w ) f(w) f(w)就是词语词频,t是一个可调阈值。
- 软窗口(soft sliding window)在一个窗口中,离target word较远的那些周围词应该具有较低的权重。
3. 潜在语义分析 LSA
见https://blog.csdn.net/weixin_41332009/article/details/111470786
在2013年之前,人们用LSA(潜在语义分析)来做词向量。
- term-term matrix: 词和词的共现矩阵,可以把握住词与词的相似性。
- term-doc matrix:词和文档的共现矩阵,可以把握文档和文档之间的相似度
例如,一个term-term matrix是这样的:
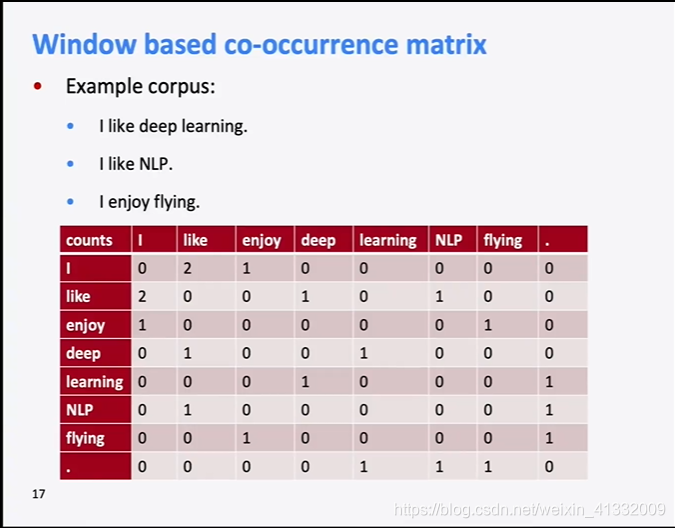
为了将其降维,使用SVD分解的方法,
4. 词语的歧义性
- 一个暴力的方法:对每个词语进行聚类,每个聚类都是一个一个词语,而是词语的一个义项。

- 一个很自然的想法:对每一个多义词的义项,都有一个词向量;每个多义词义项出现的频率也是不一样的,那么就对这些义项的词向量按频率进行加权平均。
一个担心就是,平均之后会不会这些义项就不可分了、丢失了?比如我说,“我想到了两个数,它们的和是42.” 但是你并不能够知道我想到的这两个数究竟是什么。
但惊讶的是,在这个情形下并不会出现这种情况,由于sparse coding,你还是能够区分出不同的义项。
5. 词向量的评估
有两种方法来衡量word2vec方法的好坏:
- intrinsic evaluation:直接看word2vec值相似的两个词,究竟是否相近?或者,类似“man之于king相当于woman之于?”的问题,看word2vec能否很好的回答。这需要和人工标记的结果做对比。
- extrinsic evaluation:看word2vec下游任务完成的好坏。