首先,先让我们看一下gensim和word2vec的关系吧
gensim库三大功能:
- 可扩展的统计语义
- 分析语义结构的纯文本
- 检索语义上类似的文档
word2vec是gensim的一个子模块,可以用来实现上面三大功能。而CBOW模型和 Skip-Gram模型是word2vec的两个模型。
Genism:
在gensim中,word2vec相关的API都在gensim.models.word2vec中。和算法有关的参数都在类gensim.models.word2vec.Word2Vec中。算法需要注意的参数有:
(1)sentences:我们要分析的语料,可以是一个列表,或者从文件中遍历读出。
(2)size:词向量的维度(不是one-hot),默认值100。这个维度的取值一般与我们语料的大小有关,比如小于100M的文本语料,则使用默认值一般就可以了。
(3)window:即词向量上下文最大距离,这个参数在我们的算法原理篇中标记为:window越大,则和某一个较远的词也会产生上下文关系。默认值为5。在实际的使用中,可以根据实际的需求来动态的调整这个window的大小。如果是小语料则这个值可以设置的更小。对于一般的语料这个值推荐在【5,10】之间。
(4)sg:即我们word2vec两个模型的选择了,如果是0,则是CBOW模型,是1则是Skip-Gram模型,默认是0即CBOW模型。(这两个模型后面会补充)
(5)hs:即我们的word2vec两个解法的选择了,如果是0,则是Negative Sampling,是1的话并且负采样个数negative大于0,则是Hierarchical Softmax。默认为0即Negative Sampling。
(6)negative:即使用Negative Sampling时负采样的个数。默认为5。推荐在 [3,10]之间。这个参数在我们的算法原理篇中标记为neg。
(7)cbow_mean:仅用于CBOW在做投影的时候,为0,则算法中的为上下文的词向量之和。为1则为上下文的词向量的平均值。在我们的原理篇中,是按照词向量的平均值来描述的。个人比较喜欢用平均值来表示,默认值也是1,不推荐修改默认值。
(8)min_count:需要计算词向量中的最小词频。这个值可以去掉一些很生僻的低词频,默认是5.如果是小语料,可以调低这个值。
(9)iter:随机梯度下降法中的迭代的最大次数,默认是5。对于大语料,可以增大这个值。
(10)alpha:在随机梯度下降中迭代的初始步长。算法原理篇中标记为默认值是0.025.
(11)min_alpha:由于算法支持在迭代的过程中逐渐减小步长,min_alpha给出最小的迭代步长值。随机梯度下降中每轮的迭代步长可以由iter,alpha,min_alpha一起得出。这部分由于不是word2vec算法的核心内容,因此在原理篇我们没有提到。对于大语料,需要对alpha,min_alpha,iter一起调参,来选择合适的三个值。
以上就是gensim word2vec的主要的参数,下面我们用一个实际的列子来学习word2vec。
详细的写一下:
- 什么是词向量
计算机是不理解人类的语言的,只认识数字,那我们就要将语言数字化,第一步就是将词转化文词向量。比如“我喜欢枫叶”,这句话里有三个词“我”,“喜欢”,“枫叶”,那么就用one-hot向量来表示,但是如果我们的语料很大呢,比如歌词里有10000个词,那词向量就是10000维,那会造成维度灾难和内存灾难,这个词向量太稀疏了,且我们知道词跟词之间并不是相互独立的。比如,“程序员”跟“编程”这两个词之间有紧密的联系,但是“程序员”跟“枫叶”之间则没有紧密的联系。那么我们应该找一种更好的表示呢?(我们经常用两个向量的点乘来表示两个向量的相似程度,比如,如果两个向量垂直,那么它们的点乘后的结果是零,这个时候我们一般说这两个向量是没有关系的,或它们是相互独立的。我们再来看一下我们上边定义的词向量,显然各个向量之间的点乘都是零,也就是它们之间是没有关系的,也就是说我们刚刚选择的词向量无法表达词与词之间的关系)
- 模型
- 这个时候,我们必须想出一种办法,首先我们需要一个低维度的向量来表示来表示我们的词?(这个后面会总结,word2vec可以将one-hot转化为低维度的连续值,也就是稠密向量,并且其中意思相近的词会被映射到向量空间中相近的位置) 比如,我们用一个v维的向量[0.2, 0.5, 0.3...]来表示“枫叶”,用[0.3, 0.8, 0.7.....]来表示“我”。这个时候我们的词向量不再是稀疏的,而是稠密的了。现在假设我们把所有的词向量堆叠起来形成一个矩阵,如下所示
-
根据矩阵乘法,左边矩阵的第一行乘以右边列向量就得到了第一个元素,等等,左边矩阵的第一行乘以右边矩阵的列向量代表什么?这不就是两个向量的相似度吗!所有,这个矩阵和右边向量相乘会得到一个n维的列向量,这个列向量代表的第一个词跟其他9999个词的关系!
下面解释CBOW和Skip-Gram模型,word2vec主要分为CBOW和Skip-Gram模型。
CBOW(Continuous Bag-of-Words)模型的训练输入是某一个特征词的上下文相关的词对应的词向量,而输出就是一个特定的词的词向量。
CBOW是一种根据上下文的词语预测当前词语的出现概率的模型。
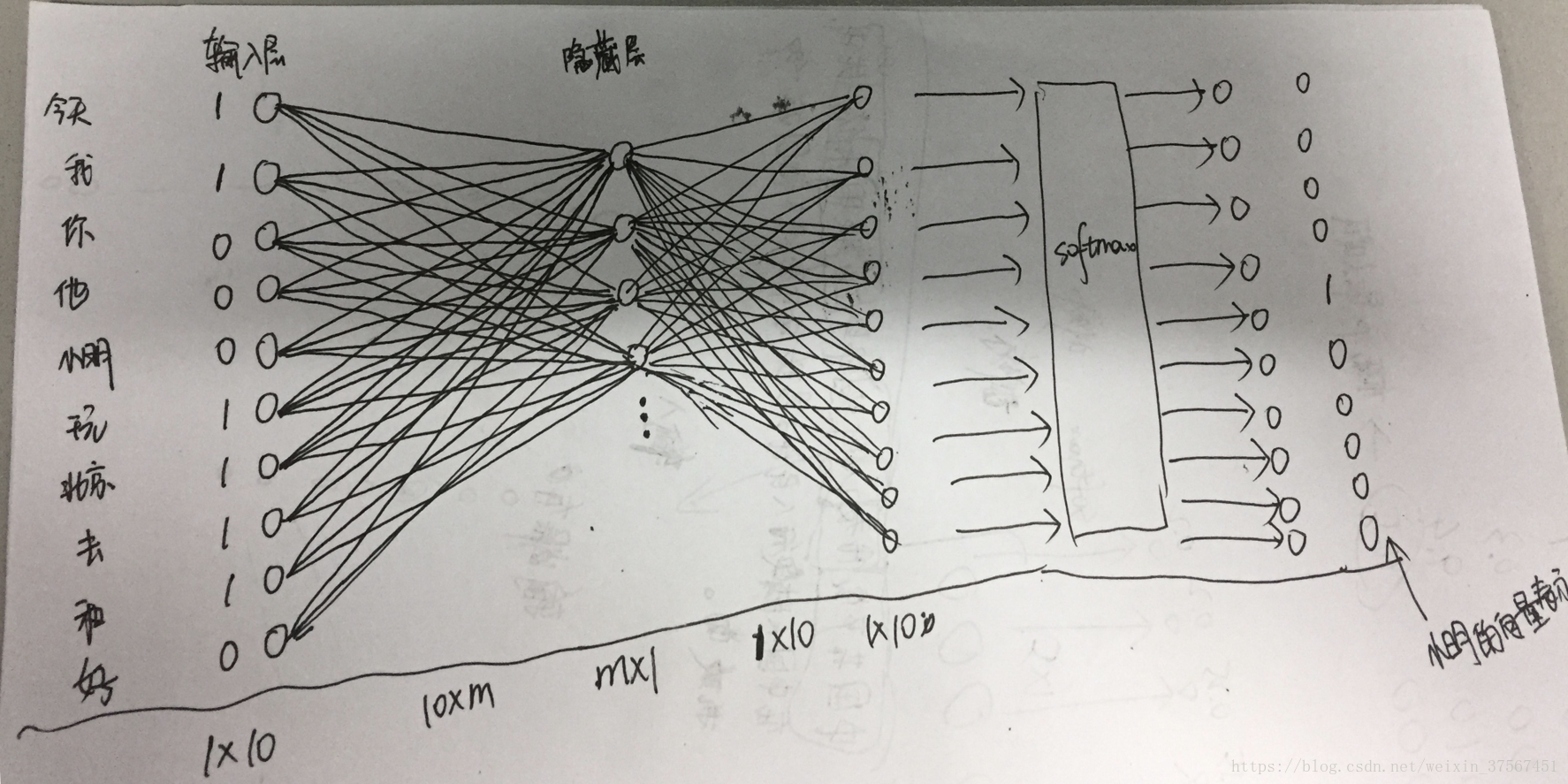
假设语料库里有10个词,[今天,我,你,他,小明,玩,北京,去,和,好]
现在有这样一句话:今天我和小明去北京玩
很显然,这个句子分词后应该是:
今天|我|和|小明|去|北京|玩
对于小明而言,选择他的前后三个词作为这个词的上下文。
接下来,将这些分别全部表示成一个one-hot向量,则向量如下:
今天:[1,0,0,0,0,0,0,0,0,0] 记为x1
我:[0,1,0,0,0,0,0,0,0,0] 记为x2
和:[0,0,0,0,0,0,0,0,1,0] 记为x3
去:[0,0,0,0,0,0,0,1,0,0] 记为x4
北京:[0,0,0,0,0,0,1,0,0,0] 记为x5
玩:[0,0,0,0,0,1,0,0,0,0] 记为x6注意:这里的维度是10,因为语料库里有10个词,这里可不是7。
此外:小明的向量表示为:
小明:[0,0,0,0,1,0,0,0,0,0]
接下来,将这6个向量求和,作为神经网络模型的输入:
x=x1+x2+x3+x4+x5+x6=[1,1,0,0,0,1,1,1,1,0]
即输入层是由小明的前后三个词生成的一个向量,维度为1*10。
我们这个例子就是根据小明这个词的前后三个词来预测小明这个位置出现各个词的概率,因为在训练中这个词就是小明,所以小明出现的概率应该是最大的,所以我们希望输出层的结果就是小明所对应的向量。也可以认为是训练数据的标签。
-
-
(上面这个图有点错误,下面的维度写的不对,应该从左到右依次是1*10,10*m,1*m,m*10,1*10,懒得改了再拍照上传)
这里我们可以随意的设定隐藏层的维度,即m的值。
那么,模型的目标函数是什么呢?
就是损失函数,就是实际输出和期望输出的差值,我们可以用平方差。
期望输出(标签):Y_=[0,0,0,0,1,0,0,0,0,0]
而X*W1*W2的值在输入到softmax得到实际的输出,假设为
Y=[y1,y2,y3,y4,y5,y6,y7,y8,y9,y10]
最后训练结束后,就要将一个词表示成一个向量,那么“今天”就用它对应的连线上的权重参数来表示
今天:[w11,w12,w13……w1m] (m就是隐藏层节点数)
我:[w21,w22,w23….w2m]
…
但是要注意的是:只能将X中元素为1的词表示成向量,即只能把句子中出现的词表示为词向量,其他词不能表示向量。
这样当我们有新的需求,比如需要求出某6个词对应是最可能的输出中心词时,我们就可以通过一次DNN前向传播算法并通过sotfmax激活函数来找到概率最大的词对应的神经元即可。
当然,网上还有另一种解释,但是原理是一致的,以 “我爱北京天安门” 这句话为例。假设我们现在关注的词是 “爱”,C=2 时它的上下文分别是 “我”,“北京天安门”。CBOW 模型就是把 “我” “北京天安门” 的 one hot 表示方式作为输入,也就是 C 个 1xV 的向量,分别跟同一个 VxN 的大小的系数矩阵 W1 相乘得到 C 个 1xN 的隐藏层 hidden layer,然后 C 个取平均所以只算一个隐藏层(这里因为得到了C个隐藏层,注意把相对应的隐藏层神经元取平均值,也就是说只有一层隐藏层)。这个过程也被称为线性激活函数 (这也算激活函数?分明就是没有激活函数了)。然后再跟另一个 NxV 大小的系数矩阵 W2 相乘得到 1xV 的输出层,这个输出层每个元素代表的就是词库里每个词的事后概率。输出层需要跟 ground truth 也就是 “爱” 的 one hot 形式做比较计算 loss。
具体的算法步骤:(其中C为窗口大小,W为输入层到隐藏层的权重矩阵)
-
-
问题:那语料中其他词的向量呢?怎么表示?还有,比如我的语料库经过分词以后是这样的26个词(暂且用字母代替):abcdefghigklmnopqrstuvwxyz,我的窗口就设为7,滑动步长设为1,即我由abc和efg训练生成d,得到abc,efg的向量表示,那么我滑动一步,变成由bcd和fgh来训练得到e的时候,这时候训练结束后,我由得到了新的b和c和f和g的表示向量,这个怎么解释?难道是变成一个矩阵吗?
Skip-Gram这里不详细讲,正好是把CBOW倒过来。