目录
理论知识准备
前期我们对分词进行了详细的讲解,那么分词之后,哪些关键词对一个文档才是重要的?比如可以通过单词出现的次数,次数越多就表示越重要。
构造文本特征向量
-
Count (文档:空格连接的字符串)
-
TFIDF (文档:空格连接的字符串)
-
Word2Vec (文档:分词列表)
TF-IDF 值
单词的TF-IDF 值可以描述一个单词对文档的重要性,TF-IDF 值越大,则越重要。
TF:全称是Term Frequency,即词频(单词出现的频率),也就是一个单词在文档中出现的次数,次数越多越重要。
计算公式:一个单词的词频TF = 单词出现的次数 / 文档中的总单词数
IDF:全称是Inverse Document Frequency,即逆向文档词频,是指一个单词在文档中的区分度。
它认为一个单词出现在的文档数越少,这个单词对该文档就越重要,就越能通过这个单词把该文档和其他文档区分开。
计算公式:一个单词的逆向文档频率 IDF = log(文档总数 / 该单词出现的文档数 + 1)
为了避免分母为0(有些单词可能不在文档中出现),所以在分母上加1

IDF 是一个相对权重值,公式中log 的底数可以自定义,一般可取2,10,e 为底数。
假设有一篇文章,文章中共有2000 个词组,“好看”出现100 次。假设全网共有1 亿篇文章,其中包含“好看”的有200 万篇。现在我们要求“好看”的TF-IDF值。
TF(中国) = 100 / 2000 = 0.05
IDF(中国) = log(1亿/(200万+1)) = 1.7 # 这里的log 以10 为底
TF-IDF(中国) = 0.05 * 1.7 = 0.085
通过计算文档中单词的TF-IDF 值,我们就可以提取文档中的特征属性,就是把TF-IDF 值较高的单词,作为文档的特征属性。
sklearn中TfidfVectorizer
sklearn 库的 feature_extraction.text 模块中的 TfidfVectorizer 类,可以计算 TF-IDF 值。
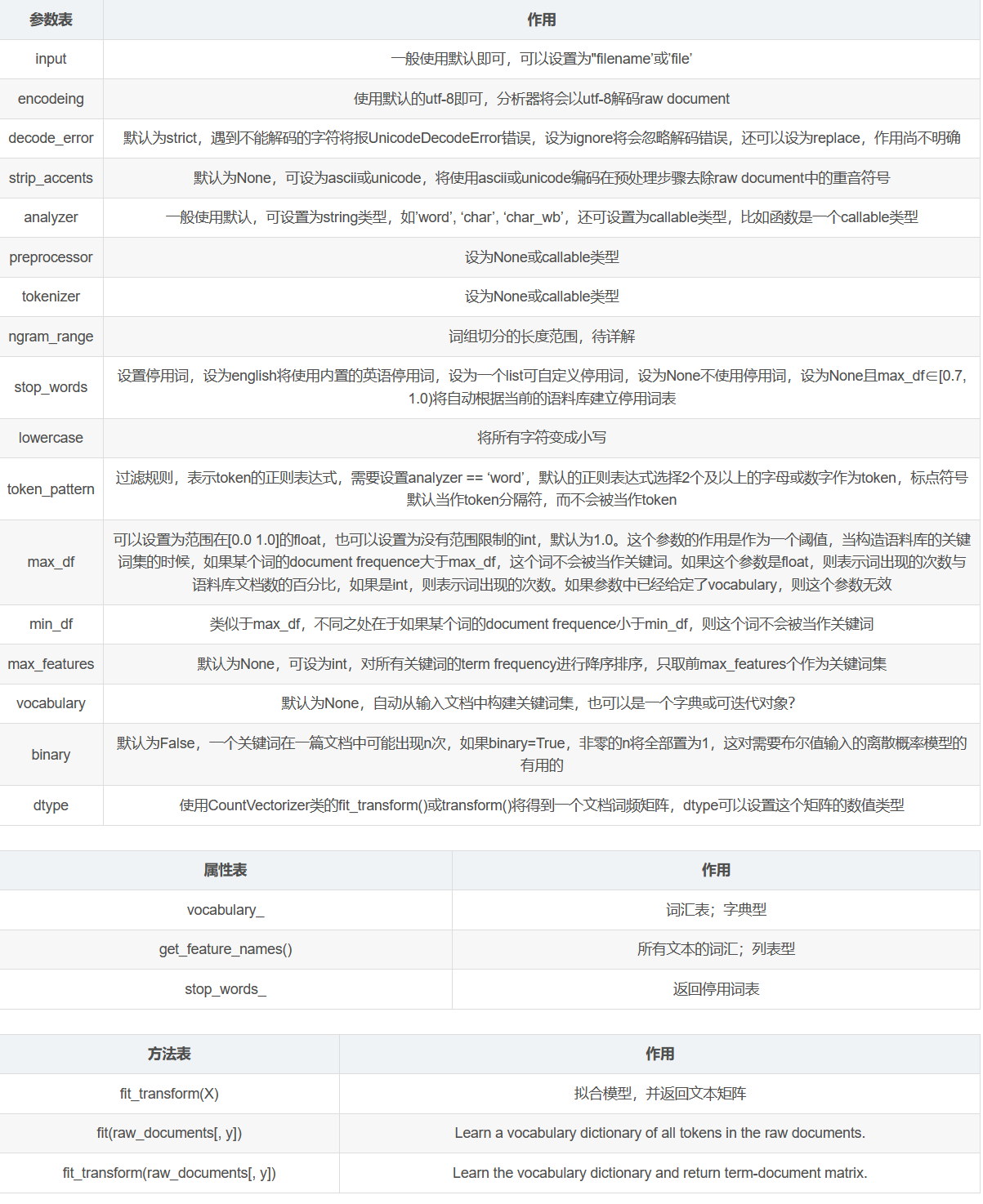
参数介绍:
TfidfVectorizer(*,
input='content',
encoding='utf-8',
decode_error='strict',
strip_accents=None,
lowercase=True,
preprocessor=None,
tokenizer=None,
analyzer='word',
stop_words=None,
token_pattern='(?u)\b\w\w+\b',
ngram_range=(1, 1),
max_df=1.0,
min_df=1,
max_features=None,
vocabulary=None,
binary=False,
dtype=<class 'numpy.float64'>,
norm='l2',
use_idf=True,
smooth_idf=True,
sublinear_tf=False)
参数解释:
input:有三种取值:
filename
file
content:默认值为content。
analyzer:有三种取值,分别是:
word:默认值为word。
char
char_wb
stop_words:表示停用词,有三种取值:
english:会加载自带英文停用词。
None:没有停用词,默认为None。
List类型的对象:需要用户自行加载停用词。只有当参数 analyzer == ‘word’ 时才起作用。
token_pattern:
表示过滤规则,是一个正则表达式,不符合正则表达式的单词将会被过滤掉。 注意默认的 token_pattern 值为
r’(?u)\b\w\w+\b’,匹配两个以上的字符,如果是一个字符则匹配不上。只有参数 analyzer == ‘word’
时,正则才起作用。
max_df:
用于描述单词在文档中的最高出现率,取值范围为 [0.0~1.0]。 比如 max_df=0.6,表示一个单词在 60%
的文档中都出现过,那么认为它只携带了非常少的信息,因此就不作为分词统计。
mid_df:单词在文档中的最低出现率,一般不用设置。
常用的方法有
t.fit(raw_docs):用raw_docs 拟合模型。
t.transform(raw_docs):将 raw_docs 转成矩阵并返回,其中包含了每个单词在每个文档中的 TF-IDF 值。
t.fit_transform(raw_docs):可理解为先 fit 再 transform。
在上面三个方法中:
t 表示 TfidfVectorizer 对象。
raw_docs 参数是一个可遍历对象,其中的每个元素表示一个文档。
fit_transform 与 transform 的用法
一般在拟合转换数据时,先处理训练集数据,再处理测试集数据。 训练集数据会用于拟合模型,而测试集数据不会用于拟合模型。所以:
fit_transform 用于训练集数据。 transform 用于测试集数据,且 transform 必须在 fit_transform
之后。
如果测试集数据也用 fit_transform 方法,则会造成过拟合。
代码实例
#中文分词
import jieba
str1 = "今天天气很好,不如我们去走走吧!"
str2 = "如果每一次天气都下雨,那么我们的计划就要取消了!"
# 将文本放入一个列表
X = [str1,str2] # 数据集
y = ['正能量','负能量'] # 目标数据
# 使用结巴将每一个文本样本进行分词,变成空格间隔的词
splited_X = []
for s in X:
splited_X.append(" ".join(jieba.lcut(s)))
print(splited_X)
# 空格间隔的词的文本可以直接使用sklearn的向量化构造器进行向量化
tv = TfidfVectorizer()
splited_X_metrics = tv.fit_transform(splited_X)
print(tv.get_feature_names()) # 特征向量
print(splited_X_metrics.toarray())

这里还有很多的默认参数,我们也可以进行指定,这样就可以根据实际的实验场景进行测试了!
import jieba
# 读取数据,一般采取文件读取方式或者pandas读取文本列
word='个人简介:【私信必回】CSDN博客专家、CSDN签约作者、华为云享专家,腾讯云、阿里云、简书、InfoQ创作者。公众号:书剧可诗画,2020年度CSDN优秀创作者。左手诗情画意,右手代码人生,欢迎一起探讨技术的诗情画意!'
# 内置词库的选择,不分词的词语
jieba.add_word("博客专家")
jieba.suggest_freq("签约作者",True)
jieba.suggest_freq("华为云享专家",True)
jieba.suggest_freq("腾讯云",True)
jieba.suggest_freq("阿里云",True)
# 分词模式,精确模式;发现新词模式,使用百度飞浆模式
words = jieba.lcut(word,cut_all=False,HMM=True,use_paddle=True)
# 加载停用词过滤
with open('stopwords.txt', 'r+', encoding = 'utf-8')as fp:
stopwords = fp.read().split('\n') #将停用词词典的每一行停用词作为列表中的一个元素
word_list = [] #用于存储过滤停用词后的分词结果
for seg in words:
if seg not in stopwords:
word_list.append(seg)
print("*"*50+"分词结果"+"*"*50+'\n')
print(word_list)
tv = TfidfVectorizer(max_features=10)
print("*"*50+"构建词向量矩阵"+"*"*50+'\n')
print(tv.fit_transform(word_list).toarray())
print(tv.get_feature_names_out()) # 默认使用所有的词构建词袋
print(tv.vocabulary_)

CountVectorizer()
这个函数的作用是:生产 文档 - 词频 矩阵,如:
结构如下:
#只列出常用的参数
contv = CountVectorizer(encoding=u'utf-8', decode_error=u'strict',
lowercase=True, stop_words=None,
token_pattern=u'(?u)\b\w\w+\b', ngram_range=(1, 1),
analyzer=u'word', max_df=1.0, min_df=1,max_features=None,
vocabulary=None, binary=False, dtype=<type 'numpy.int64'>)
代码实操
import numpy as np
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.feature_extraction.text import CountVectorizer
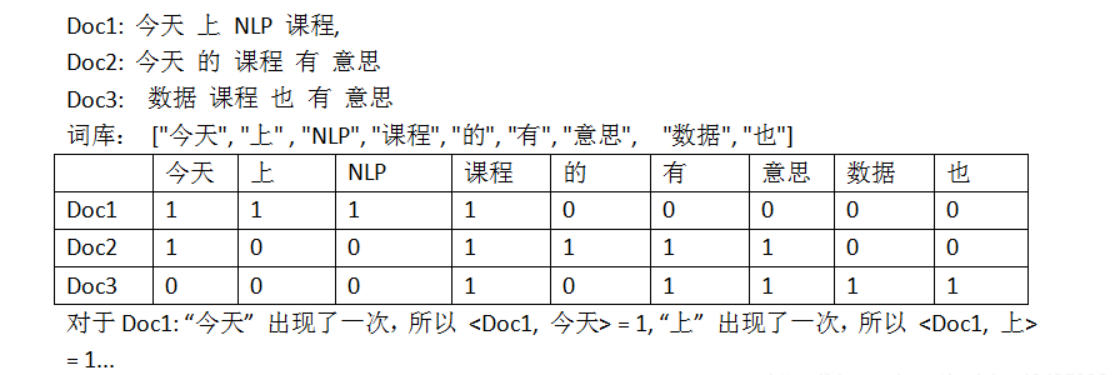
text = ["今天 上 NLP 课程", "今天 的 课程 有 意思" , "数据 课程 也有 意思"]
vocabulary = ["今天", "上" , "NLP", "课程", "的", "有", "意思", "数据", "也"]
contv = CountVectorizer(vocabulary=vocabulary, stop_words=[], min_df=0, token_pattern='(?u)\\b\\w*\\w*\\b', lowercase=False) # 实例化
contv1 = contv.fit_transform(text) # 训练-传入数据
print(contv1) #调取结果
print(contv1.toarray())
print(contv.vocabulary_)
{
'今天': 0, '上': 1, 'NLP': 2, '课程': 3, '的': 4, '有': 5, '意思': 6, '数据': 7, '也': 8}
(0, 0) 1
(0, 1) 1
(0, 2) 1
(0, 3) 1
(1, 0) 1
(1, 3) 1
(1, 4) 1
(1, 5) 1
(1, 6) 1
(2, 3) 1
(2, 6) 1
(2, 7) 1
[[1 1 1 1 0 0 0 0 0]
[1 0 0 1 1 1 1 0 0]
[0 0 0 1 0 0 1 1 0]]
一般要设置的参数是:ngram_range,max_df,min_df,max_features等,具体情况具体分析
这里对参数进行一个详细的说明:
Word2Vec
它是一种语言模型,使用向量表示单词,向量空间表示句子。在将单词转化为向量之后,句子也就可以被表示成一个矩阵,这样就把现实中的语言成功转化成了数字。
它是一种词嵌入模型,简单来说,就是可以通过训练词嵌入模型将文本由原来的高维表示形式转化为低维表示形式,每一个维度代表着当前单词与其它单词在该维度下的不同,多个维度的数共同来表示这个单词。
word2vec是基于one-hot词向量进行的转化,one-hot是把每一个词都表示成(0,0,1,…,0,0,…)的形式,不仅在文字量巨大时会造成数据灾难,而且在多个词进行比较时效果一般。
Word2vec 的优缺点
优点:
由于 Word2vec 会考虑上下文,跟之前的 Embedding 方法相比,效果要更好(但不如 18 年之后的方法)
比之前的 Embedding方 法维度更少,所以速度更快
通用性很强,可以用在各种 NLP 任务中
缺点:
由于词和向量是一对一的关系,所以多义词的问题无法解决。
Word2vec 是一种静态的方式,虽然通用性强,但是无法针对特定任务做动态优化
word2vec更多学到的是具备相似上下文的词,学习的向量和真正语义还有差距。比如 “他的技术水平很好”,“他的技术水平很差”相似度也很高。
所以在使用情感分析的时候,一般不是很推荐word2vec进行分析和研究
代码案例
from gensim.models import Word2Vec
word2vec_model = Word2Vec(cutWords_list,
vector_size=100, # 向量长度
epochs=10, # 训练批次
min_count=20 # 忽略词频数少于20的词
)
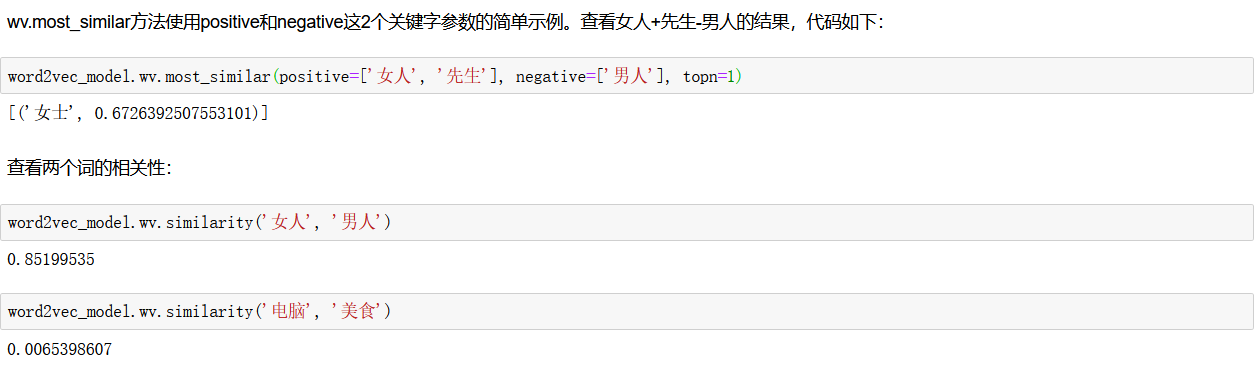
调用Word2Vec模型对象的wv.most_similar方法查看与摄影含义最相近的词。
- wv.most_similar方法有2个参数,第1个参数是要搜索的词,第2个关键字参数topn数据类型为正整数,是指需要列出多少个最相关的词汇,默认为10,即列出10个最相关的词汇。
- wv.most_similar方法返回值的数据类型为列表,列表中的每个元素的数据类型为元组,元组有2个元素,第1个元素为相关词汇,第2个元素为相关程度,数据类型为浮点型。

总结
如何将文本转换为数值矩阵,目前在自然语言处理当中有很多的方法,构建词向量,每一种的方法都有优缺点,我们在使用这类方法的时候,需要结合自己的实际情况进行比对,最终才能得到最佳的模型。

每文一语
当不断学习的时候,才会发现知识储备少之越少!