跳元模型
回顾一下第一节讲过的跳元模型
跳元模型(Skip-gram Model)是一种用于学习词向量的模型,属于Word2Vec算法中的一种。它的目标是通过给定一个中心词语来预测其周围的上下文词语。
这节我们以跳元模型为例,讲解word2vec的实现
文章内容来自李沐大神的《动手学深度学习》并加以我的理解,感兴趣可以去https://zh-v2.d2l.ai/查看完整书籍
文章目录
数据集
我们在这里使用的数据集是Penn Tree Bank(PTB)。该语料库取自“华尔街日报”的文章,分为训练集、验证集和测试集。在原始格式中,文本文件的每一行表示由空格分隔的一句话。在这里,我们将每个单词视为一个词元。
数据集的获取
import math
import os
import random
import torch
from d2l import torch as d2l
#@save
d2l.DATA_HUB['ptb'] = (d2l.DATA_URL + 'ptb.zip',
'319d85e578af0cdc590547f26231e4e31cdf1e42')
#@save
def read_ptb():
"""将PTB数据集加载到文本行的列表中"""
data_dir = d2l.download_extract('ptb')
# Readthetrainingset.
with open(os.path.join(data_dir, 'ptb.train.txt')) as f:
raw_text = f.read()
return [line.split() for line in raw_text.split('\n')]
sentences = read_ptb()
f'# sentences数: {
len(sentences)}'

在读取训练集之后,我们为语料库构建了一个词表,其中出现次数少于10次的任何单词都将由“”词元替换。请注意,原始数据集还包含表示稀有(未知)单词的“”词元。
词表的构建
vocab = d2l.Vocab(sentences, min_freq=10)
f'vocab size: {
len(vocab)}'

词表(Vocabulary),也被称为词典(Dictionary)或词汇表,是在自然语言处理(NLP)任务中用于表示文本数据中所有不同单词的集合。
在文本处理中,将文本数据转换为机器可处理的形式通常需要对单词进行编码。词表是一个重要的组成部分,它将每个单词映射到一个唯一的标识符,例如整数索引。通过构建词表,我们可以将文本数据中的单词转换为数字表示,以便机器学习模型可以对其进行处理。
词表的构建过程包括以下步骤:
- 收集所有的单词:遍历文本数据,将其中出现的所有单词进行收集。
- 去重:去除重复的单词,确保每个单词只在词表中出现一次。
- 分配唯一标识符:为每个单词分配一个唯一的标识符,例如整数索引。常见的做法是按照单词出现的频率进行排序,频率高的单词通常被分配较小的索引。
- 特殊标记:词表通常还包括一些特殊标记,如未知词元(UNK)、填充词元(PAD)、开始词元(START)、结束词元(END)等。这些标记用于表示特定的语义或在模型中的特殊处理。
词表在NLP任务中起到了关键的作用,它不仅提供了单词到数字的映射,还可以用于统计词频、计算词向量等。构建一个良好的词表对于成功实施文本处理任务至关重要。
d2l中的词表如下实现:
class Vocab:
"""Vocabulary for text."""
def __init__(self, tokens=None, min_freq=0, reserved_tokens=None):
"""Defined in :numref:`sec_text_preprocessing`"""
if tokens is None:
tokens = []
if reserved_tokens is None:
reserved_tokens = []
# Sort according to frequencies
counter = count_corpus(tokens)
self._token_freqs = sorted(counter.items(), key=lambda x: x[1],
reverse=True)
# The index for the unknown token is 0
self.idx_to_token = ['<unk>'] + reserved_tokens
self.token_to_idx = {
token: idx
for idx, token in enumerate(self.idx_to_token)}
for token, freq in self._token_freqs:
if freq < min_freq:
break
if token not in self.token_to_idx:
self.idx_to_token.append(token)
self.token_to_idx[token] = len(self.idx_to_token) - 1
def __len__(self):
return len(self.idx_to_token)
def __getitem__(self, tokens):
if not isinstance(tokens, (list, tuple)):
return self.token_to_idx.get(tokens, self.unk)
return [self.__getitem__(token) for token in tokens]
def to_tokens(self, indices):
if not isinstance(indices, (list, tuple)):
return self.idx_to_token[indices]
return [self.idx_to_token[index] for index in indices]
def count_corpus(tokens):
"""Count token frequencies.
Defined in :numref:`sec_text_preprocessing`"""
# Here `tokens` is a 1D list or 2D list
if len(tokens) == 0 or isinstance(tokens[0], list):
# Flatten a list of token lists into a list of tokens
tokens = [token for line in tokens for token in line]
return collections.Counter(tokens)
@property
def unk(self): # Index for the unknown token
return 0
@property
def token_freqs(self): # Index for the unknown token
return self._token_freqs
下采样
文本数据通常有“the”“a”和“in”等高频词:它们在非常大的语料库中甚至可能出现数十亿次。然而,这些词经常在上下文窗口中与许多不同的词共同出现,提供的有用信息很少。例如,考虑上下文窗口中的词“chip”:直观地说,它与低频单词“intel”的共现比与高频单词“a”的共现在训练中更有用。此外,大量(高频)单词的训练速度很慢。因此,当训练词嵌入模型时,可以对高频单词进行下采样 (Mikolov et al., 2013)。具体地说,数据集中的每个词 w i w_i wi将有概率 P ( w i ) P(w_i) P(wi)地被丢弃:
P ( w i ) = m a x ( 1 − t f ( w i ) , 0 ) P(w_i)=max(1-\sqrt{\frac{t}{f(w_i)}},0) P(wi)=max(1−f(wi)t,0)
其中 f ( w i ) f(w_i) f(wi)是 w i w_i wi的词数与数据集中的总词数的比率,常量 t t t是超参数(在实验中为 1 0 − 4 10^{-4} 10−4)。我们可以看到,只有当相对比率 f ( w i ) > t f(w_i)>t f(wi)>t时,(高频)词 w i w_i wi才能被丢弃,且该词的相对比率越高,被丢弃的概率就越大。
#@save
def subsample(sentences, vocab):
"""下采样高频词"""
# 排除未知词元'<unk>'
sentences = [[token for token in line if vocab[token] != vocab.unk]
for line in sentences]
counter = d2l.count_corpus(sentences)
num_tokens = sum(counter.values())
# 如果在下采样期间保留词元,则返回True
def keep(token):
return(random.uniform(0, 1) <
math.sqrt(1e-4 / counter[token] * num_tokens))
return ([[token for token in line if keep(token)] for line in sentences],
counter)
subsampled, counter = subsample(sentences, vocab)
这段代码是一个用于下采样高频词的函数。
函数的输入参数包括 sentences(句子列表)和 vocab(词表)。该函数的输出是一个经过下采样处理后的句子列表和词频统计计数器。
下采样的过程如下:
- 首先,函数排除了句子中的未知词元
'<unk>',即词表中未知词的标记。 - 然后,使用
count_corpus函数统计句子中每个词元的频次,并计算语料中总的词元数。 - 定义了一个内部函数
keep(token),用于判断是否在下采样过程中保留词元。这里使用了一个阈值1e-4和词元的频次来决定是否保留词元。频次较高的词元将有较小的概率保留下来,而频次较低的词元将有较大的概率保留下来。 - 最后,函数遍历每个句子中的词元,根据
keep函数的结果来决定是否保留该词元。保留的词元构成了经过下采样处理后的句子列表。
下面的代码片段绘制了下采样前后每句话的词元数量的直方图。正如预期的那样,下采样通过删除高频词来显著缩短句子,这将使训练加速。
d2l.show_list_len_pair_hist(
['origin', 'subsampled'], '# tokens per sentence',
'count', sentences, subsampled);

我们看出句子的长度显著降低。对于单个词元,高频词“the”的采样率不到1/20。
def compare_counts(token):
return (f'"{
token}"的数量:'
f'之前={
sum([l.count(token) for l in sentences])}, '
f'之后={
sum([l.count(token) for l in subsampled])}')
compare_counts('the')

相比之下,低频词“join”则被完全保留。
compare_counts('join')

在下采样之后,我们将词元映射到它们在语料库中的索引。

中心词和上下文词的提取
下面的get_centers_and_contexts函数从corpus中提取所有中心词及其上下文词。它随机采样1到max_window_size之间的整数作为上下文窗口。对于任一中心词,与其距离不超过采样上下文窗口大小的词为其上下文词。
#@save
def get_centers_and_contexts(corpus, max_window_size):
"""返回跳元模型中的中心词和上下文词"""
centers, contexts = [], []
for line in corpus:
# 要形成“中心词-上下文词”对,每个句子至少需要有2个词
if len(line) < 2:
continue
centers += line
for i in range(len(line)): # 上下文窗口中间i
window_size = random.randint(1, max_window_size)
indices = list(range(max(0, i - window_size),
min(len(line), i + 1 + window_size)))
# 从上下文词中排除中心词
indices.remove(i)
contexts.append([line[idx] for idx in indices])
return centers, contexts
函数的输入参数包括 corpus 和 max_window_size。corpus 是一个包含多个句子的语料库,每个句子由单词列表表示。max_window_size 是一个整数,表示上下文窗口的最大大小。
函数的输出是两个列表,分别是中心词列表 centers 和上下文词列表 contexts。
代码的逻辑如下:
- 创建空的中心词列表
centers和上下文词列表contexts。 - 对于语料库中的每个句子
line,执行以下步骤:- 如果句子的长度小于 2,即句子中不足两个词,则跳过该句子。
- 将句子中的所有单词添加到中心词列表
centers中。 - 对于句子中的每个词的索引
i,执行以下步骤:- 随机生成一个上下文窗口的大小
window_size,范围为 1 到max_window_size。 - 计算上下文窗口的左边界索引为
max(0, i - window_size),右边界索引为min(len(line), i + 1 + window_size)。 - 创建一个索引列表
indices,包含上下文窗口范围内的索引。 - 从索引列表中移除中心词的索引
i,得到最终的上下文词索引列表。 - 根据最终的上下文词索引列表,获取对应的上下文词,并将其添加到上下文词列表
contexts中。
- 随机生成一个上下文窗口的大小
- 完成语料库中所有句子的处理后,返回中心词列表
centers和上下文词列表contexts。
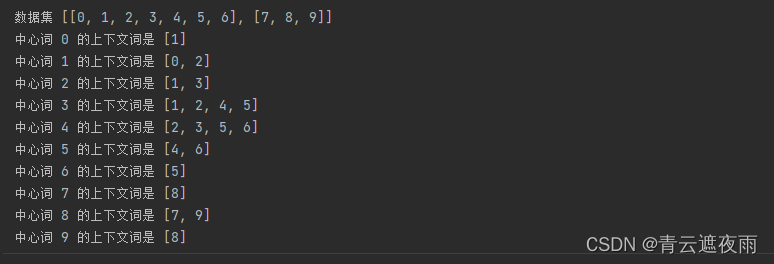
接下来,我们创建一个人工数据集,分别包含7个和3个单词的两个句子。设置最大上下文窗口大小为2,并打印所有中心词及其上下文词。
tiny_dataset = [list(range(7)), list(range(7, 10))]
print('数据集', tiny_dataset)
for center, context in zip(*get_centers_and_contexts(tiny_dataset, 2)):
print('中心词', center, '的上下文词是', context)
在PTB数据集上进行训练时,我们将最大上下文窗口大小设置为5。下面提取数据集中的所有中心词及其上下文词。
all_centers, all_contexts = get_centers_and_contexts(corpus, 5)
f'# “中心词-上下文词对”的数量: {
sum([len(contexts) for contexts in all_contexts])}'

负采样
我们使用负采样进行近似训练。为了根据预定义的分布对噪声词进行采样,我们定义以下RandomGenerator类,其中(可能未规范化的)采样分布通过变量sampling_weights传递。
sampling_weights具体来说是一个和population相同形状的列表,代表了population中对应元素被采样的概率
#@save
class RandomGenerator:
"""根据n个采样权重在{1,...,n}中随机抽取"""
def __init__(self, sampling_weights):
# Exclude
self.population = list(range(1, len(sampling_weights) + 1))
self.sampling_weights = sampling_weights
self.candidates = []
self.i = 0
def draw(self):#每次调用函数缓存10000个采样,输出一个采样,i自增1,直到用完整个缓存继续采样
if self.i == len(self.candidates):
# 缓存k个随机采样结果
self.candidates = random.choices(
self.population, self.sampling_weights, k=10000)
self.i = 0
self.i += 1
return self.candidates[self.i - 1]
这段代码定义了一个名为 RandomGenerator 的类,用于根据给定的采样权重在整数范围 {1, ..., n} 中进行随机抽取。
构造函数 __init__ 在创建类的实例时被调用,并接受一个采样权重列表 sampling_weights 作为参数。在构造函数内部,以下操作被执行:
- 创建一个整数列表
population,其中包含了从 1 到len(sampling_weights)的整数范围,用于表示可能的抽样候选项。 - 将采样权重列表存储在实例变量
sampling_weights中。 - 创建一个空的候选项列表
candidates,用于缓存采样结果。 - 初始化一个索引变量
i,用于追踪当前采样的位置。
draw 方法用于执行随机抽取操作。方法的逻辑如下:
- 首先,检查当前采样位置
i是否等于候选项列表candidates的长度。如果相等,说明之前缓存的采样结果已经用完,需要重新生成一批新的采样结果。 - 调用
random.choices函数来生成k=10000个随机采样结果,其中population参数为整数范围{1, ..., n},sampling_weights参数为采样权重列表,k参数表示生成的采样结果数量。生成的结果存储在候选项列表candidates中。 - 将索引变量
i增加 1,表示进行了一次新的采样。 - 返回候选项列表中当前采样位置对应的元素。
这种设计的目的是为了提高采样效率。通过一次性生成一批采样结果并进行缓存,可以减少对 random.choices 函数的调用次数,提高整体的性能。每次调用 draw 方法时,通过逐个返回缓存的采样结果,避免了每次调用都进行一次完整的随机抽取操作。
例如,我们可以在索引1、2和3中绘制10个随机变量 X X X,采样概率为 P ( X = 1 ) = 2 / 9 , P ( X = 2 ) = 3 / 9 和 P ( X = 3 ) = 4 / 9 P(X=1)=2/9,P(X=2)=3/9和P(X=3)=4/9 P(X=1)=2/9,P(X=2)=3/9和P(X=3)=4/9,如下所示。
#@save
generator = RandomGenerator([2, 3, 4])
[generator.draw() for _ in range(10)]

对于一对中心词和上下文词,我们随机抽取了K个(实验中为5个)噪声词。根据word2vec论文中的建议,将噪声词 w w w的采样概率 P ( w ) P(w) P(w)设置为其在字典中的相对频率,其幂为0.75 (Mikolov et al., 2013)。
#@save
def get_negatives(all_contexts, vocab, counter, K):
"""返回负采样中的噪声词"""
# 索引为1、2、...(索引0是词表中排除的未知标记)
sampling_weights = [counter[vocab.to_tokens(i)]**0.75
for i in range(1, len(vocab))]
all_negatives, generator = [], RandomGenerator(sampling_weights)
for contexts in all_contexts:
negatives = []
while len(negatives) < len(contexts) * K:
neg = generator.draw()
# 噪声词不能是上下文词
if neg not in contexts:
negatives.append(neg)
all_negatives.append(negatives)
return all_negatives
all_negatives = get_negatives(all_contexts, vocab, counter, 5)
函数接受以下参数:
all_contexts:表示所有的上下文词的列表或可迭代对象。vocab:表示词汇表的对象。counter:表示词频计数器的对象。K:表示每个上下文词应采样的噪声词数量。
函数的逻辑如下:
- 首先,根据词频计数器
counter和词汇表vocab,计算每个词的采样权重列表sampling_weights。对于词汇表中的每个词(除了未知标记),使用词频的 0.75 次方作为权重值。这样可以使较低频次的词有更高的采样概率。 - 创建一个空列表
all_negatives,用于存储每个上下文对应的噪声词列表。 - 创建一个随机生成器对象
generator,并将前面计算得到的采样权重列表sampling_weights作为参数传递给生成器的构造函数。 - 对于每个上下文词列表
contexts,执行以下操作:- 创建一个空列表
negatives,用于存储当前上下文词的噪声词。 - 在噪声词列表中采样,直到噪声词的数量达到当前上下文词数量乘以
K。每次从随机生成器generator中使用draw方法进行采样,得到一个噪声词。 - 检查采样得到的噪声词是否不在当前上下文词列表
contexts中,如果满足条件,则将噪声词添加到negatives列表中。 - 将
negatives列表添加到all_negatives列表中,表示当前上下文对应的噪声词列表。
- 创建一个空列表
- 最后,函数返回
all_negatives,其中包含了每个上下文对应的噪声词列表。
小批量加载训练实例
在提取所有中心词及其上下文词和采样噪声词后,将它们转换成小批量的样本,在训练过程中可以迭代加载。
在小批量中, i t h i^{th} ith个样本包括中心词及其 n i n_i ni个上下文词和 m i m_i mi个噪声词。由于上下文窗口大小不同, n i + m i n_i+m_i ni+mi对于不同的 i i i是不同的。因此,对于每个样本,我们在contexts_negatives个变量中将其上下文词和噪声词连结起来,并填充零,直到连结长度达到 m a x ( n i + m i ) max(n_i+m_i) max(ni+mi)。为了在计算损失时排除填充,我们定义了掩码变量masks。在masks中的元素和contexts_negatives中的元素之间存在一一对应关系,其中masks中的0(否则为1)对应于contexts_negatives中的填充。
为了区分正反例,我们在contexts_negatives中通过一个labels变量将上下文词与噪声词分开。类似于masks,在labels中的元素和contexts_negatives中的元素之间也存在一一对应关系,其中labels中的1(否则为0)对应于contexts_negatives中的上下文词的正例。
上述思想在下面的batchify函数中实现。其输入data是长度等于批量大小的列表,其中每个元素是由中心词center、其上下文词context和其噪声词negative组成的样本。此函数返回一个可以在训练期间加载用于计算的小批量,例如包括掩码变量。
#@save
def batchify(data):
"""返回带有负采样的跳元模型的小批量样本"""
#计算最大长度
max_len = max(len(c) + len(n) for _, c, n in data)
centers, contexts_negatives, masks, labels = [], [], [], []
for center, context, negative in data:
cur_len = len(context) + len(negative)
centers += [center]
contexts_negatives += \
[context + negative + [0] * (max_len - cur_len)]
masks += [[1] * cur_len + [0] * (max_len - cur_len)]
labels += [[1] * len(context) + [0] * (max_len - len(context))]#负采样的部分也标注为0
return (torch.tensor(centers).reshape((-1, 1)), torch.tensor(
contexts_negatives), torch.tensor(masks), torch.tensor(labels))
函数接受一个数据列表 data,其中每个元素包含了中心词、上下文词列表和负采样的噪声词列表。
函数的逻辑如下:
-
首先,计算所有样本中上下文词列表和负采样噪声词列表的最大长度
max_len。这将用于确定小批量样本的张量形状。 -
创建四个空列表:
centers用于存储中心词,contexts_negatives用于存储拼接后的上下文词列表和负采样噪声词列表,masks用于存储掩码张量,labels用于存储标签张量。 -
对于数据列表
data中的每个元组(center, context, negative),执行以下操作:- 计算当前样本中上下文词列表和负采样噪声词列表的长度
cur_len。 - 将中心词
center添加到centers列表中。 - 将上下文词列表、负采样噪声词列表和填充的零元素拼接成一个长度为
max_len的列表,并将结果添加到contexts_negatives列表中。 - 创建一个掩码张量,**其中上下文词部分和负采样的部分为 1,填充部分为 0,**并将结果添加到
masks列表中。 - 创建一个标签张量,**其中上下文词部分为 1,负采样噪声词和填充部分为 0,**并将结果添加到
labels列表中。
- 计算当前样本中上下文词列表和负采样噪声词列表的长度
-
最后,函数将四个列表转换为张量,并返回一个包含中心词张量、上下文词列表和负采样噪声词列表的元组。
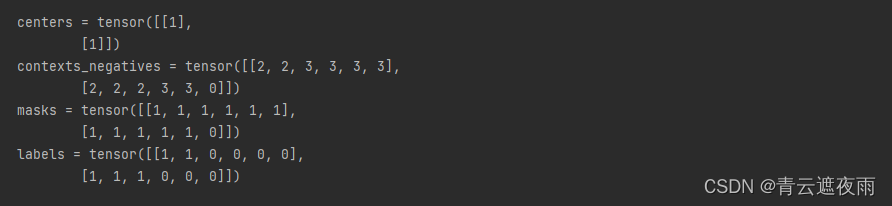
让我们使用一个小批量的两个样本来测试此函数。
x_1 = (1, [2, 2], [3, 3, 3, 3])
x_2 = (1, [2, 2, 2], [3, 3])
batch = batchify((x_1, x_2))
names = ['centers', 'contexts_negatives', 'masks', 'labels']
for name, data in zip(names, batch):
print(name, '=', data)
整合所有代码
#@save
def load_data_ptb(batch_size, max_window_size, num_noise_words):
"""下载PTB数据集,然后将其加载到内存中"""
num_workers = 0;
#获取数据集
sentences = read_ptb()
#生成词表
vocab = d2l.Vocab(sentences, min_freq=10)
#下采样
subsampled, counter = subsample(sentences, vocab)
#采样结果转索引
corpus = [vocab[line] for line in subsampled]
#获取所有中心词和上下文词
all_centers, all_contexts = get_centers_and_contexts(
corpus, max_window_size)
#获取所有噪声词
all_negatives = get_negatives(
all_contexts, vocab, counter, num_noise_words)
# 定义数据集
class PTBDataset(torch.utils.data.Dataset):
def __init__(self, centers, contexts, negatives):
assert len(centers) == len(contexts) == len(negatives)
self.centers = centers
self.contexts = contexts
self.negatives = negatives
def __getitem__(self, index):
return (self.centers[index], self.contexts[index],
self.negatives[index])
def __len__(self):
return len(self.centers)
dataset = PTBDataset(all_centers, all_contexts, all_negatives)
data_iter = torch.utils.data.DataLoader(
dataset, batch_size, shuffle=True,
collate_fn=batchify, num_workers=num_workers)
return data_iter, vocab
注意:collate_fn=batchify
collate_fn是torch.utils.data.DataLoader类的一个可选参数,用于指定在加载每个小批量样本时要使用的函数。
当collate_fn参数被指定时,DataLoader会在每个小批量样本加载时调用这个函数,并将单个样本作为输入。collate_fn函数负责对单个样本进行处理,并将它们组合成一个小批量样本。
通常情况下,collate_fn函数用于将单个样本转换为张量形式,并根据需要进行填充或其他数据转换操作。这样可以确保每个小批量样本具有相同的形状,以便于输入到模型进行训练或推理。
让我们打印数据迭代器的第一个小批量。
data_iter, vocab = load_data_ptb(512, 5, 5)
for batch in data_iter:
for name, data in zip(names, batch):
print(name, 'shape:', data.shape)
break
训练word2vec
使用上述定义的函数获取数据集
batch_size, max_window_size, num_noise_words = 512, 5, 5
data_iter, vocab = d2l.load_data_ptb(batch_size, max_window_size,
num_noise_words)
跳元模型
嵌入层
嵌入层(Embedding Layer)是深度学习中常用的一种层类型,用于将离散的符号(如词、字符等)表示为连续的向量形式,也被称为词嵌入或向量表示。
在自然语言处理(NLP)任务中,文本数据通常以离散的符号形式表示,如词汇表中的单词。嵌入层可以将这些离散符号映射到连续的低维向量空间中,其中每个维度代表了一个语义特征。嵌入层的目的是通过学习这种映射关系,将相似的符号映射到相近的向量表示,从而捕捉到词之间的语义关系。
嵌入层通常通过一个可训练的参数矩阵来实现。该参数矩阵的维度是词汇表大小(词的数量)乘以嵌入向量的维度。在训练过程中,这些嵌入向量会根据模型的优化目标逐渐调整,以最大程度地捕捉到词汇之间的语义关系。
嵌入层在深度学习中的应用非常广泛,特别是在NLP任务中。它可以作为模型的第一层,将输入的离散符号(例如单词或字符)转换为密集向量表示,进而输入到后续层进行进一步处理,如循环神经网络(RNN)或卷积神经网络(CNN)等。
嵌入层将词元的索引映射到其特征向量。该层的权重是一个矩阵,其行数等于字典大小(input_dim),列数等于每个标记的向量维数(output_dim)。在词嵌入模型训练之后,这个权重就是我们所需要的。
# 创建嵌入层的参数矩阵
embedding_weights = torch.randn(vocab_size, embedding_dim)
我们可以使用torch中的Embedding创建嵌入层
embed = nn.Embedding(num_embeddings=20, embedding_dim=4)
print(f'Parameter embedding_weight ({
embed.weight.shape}, '
f'dtype={
embed.weight.dtype})')
嵌入层的输入是词元(词)的索引。对于任何词元索引 i i i,其向量表示可以从嵌入层中的权重矩阵的第 i i i行获得。由于向量维度(output_dim)被设置为4,因此当小批量词元索引的形状为(2,3)时,嵌入层返回具有形状(2,3,4)的向量。
x = torch.tensor([[1, 2, 3], [4, 5, 6]])
embed(x)

定义前向传播
在前向传播中,跳元语法模型的输入包括形状为(批量大小,1)的中心词索引center和形状为(批量大小,max_len)的上下文与噪声词索引contexts_and_negatives,这两个变量首先通过嵌入层从词元索引转换成向量,然后它们的批量矩阵相乘,返回形状为(批量大小,1,max_len)的输出。输出中的每个元素是中心词向量和上下文或噪声词向量的点积。
跳元的定义:
def skip_gram(center, contexts_and_negatives, embed_v, embed_u):
v = embed_v(center)
u = embed_u(contexts_and_negatives)
pred = torch.bmm(v, u.permute(0, 2, 1))#批量矩阵乘法
return pred
在给定中心词center和上下文词汇contexts_and_negatives的情况下,代码使用embed_v和embed_u分别对中心词和上下文词汇进行嵌入操作。然后,通过调用torch.bmm函数执行批量矩阵乘法,计算中心词向量v与上下文词汇向量u的转置之间的乘积。最终,返回预测结果pred。
值得注意的是,torch.bmm函数接受的输入张量的形状需满足要求。在这个例子中,v的形状应为(batch_size, 1, embedding_dim),u的形状应为(batch_size, num_negatives + num_contexts, embedding_dim),其中batch_size表示批量大小,embedding_dim表示词向量维度,num_negatives表示负样本数量,num_contexts表示上下文词汇数量。
skip_gram(torch.ones((2, 1), dtype=torch.long),
torch.ones((2, 4), dtype=torch.long), embed, embed).shape

训练
在训练带负采样的跳元模型之前,我们先定义它的损失函数。
二元交叉熵损失
交叉熵(Cross-Entropy)是一种常用的损失函数,常用于分类任务中。它用于衡量模型的输出与目标标签之间的差异。
CrossEntropy = − ∑ i = 1 N ∑ j = 1 K y i j log ( p i j ) \text{CrossEntropy} = -\sum_{i=1}^{N}\sum_{j=1}^{K} y_{ij} \log(p_{ij}) CrossEntropy=−i=1∑Nj=1∑Kyijlog(pij)
其中, y i j y_{ij} yij表示第i个样本的真实标签的第j个元素(0或1), p i j p_{ij} pij表示模型预测的第i个样本属于第j个类别的概率。
二元交叉熵损失(Binary Cross-Entropy Loss)是交叉熵损失函数在二分类问题中的特殊形式。它用于衡量二分类模型的预测结果与真实结果之间的差异。
在二分类问题中,我们有两个类别,通常将它们表示为"正例"(positive)和"反例"(negative)。对于每个样本,我们用一个标签值来表示其真实类别,通常为0或1,其中0表示反例,1表示正例。模型给出的预测结果是一个介于0和1之间的概率值,表示样本属于正例的概率。
二元交叉熵损失的计算公式如下:
H ( p , q ) = − 1 N ∑ i = 1 N [ y i log ( p i ) + ( 1 − y i ) log ( 1 − p i ) ] H(p, q) = -\frac{1}{N}\sum_{i=1}^{N}[y_{i}\log(p_{i}) + (1-y_{i})\log(1-p_{i})] H(p,q)=−N1i=1∑N[yilog(pi)+(1−yi)log(1−pi)]
其中, N N N表示样本数量, y i y_i yi表示第 i i i个样本的真实标签(取值为0或1), p i p_i pi表示预测为类别1的概率。
为什么使用二元交叉熵损失?
我们回顾上一节我们计算出的损失的函数:
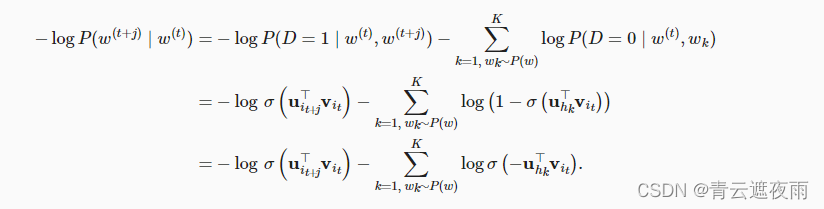
观察到和二元交叉熵损失非常相似,其中中心词的上下文词被视为正例,而其他随机选择的词(负采样部分)则被视为负例。
对于每个训练样本,我们将中心词作为输入,然后使用模型进行预测。预测结果是一个介于0和1之间的概率值,表示上下文词是正例的概率。然后,我们使用二元交叉熵损失函数来计算预测结果与真实结果之间的差异,并通过优化算法(如梯度下降)来最小化这个损失函数。
class SigmoidBCELoss(nn.Module):
# 带掩码的二元交叉熵损失
def __init__(self):
super().__init__()
def forward(self, inputs, target, mask=None):
out = nn.functional.binary_cross_entropy_with_logits(
inputs, target, weight=mask, reduction="none")
return out.mean(dim=1)
loss = SigmoidBCELoss()
在forward方法中,调用了nn.functional.binary_cross_entropy_with_logits函数,该函数是PyTorch中用于计算二元交叉熵损失的函数。它接收模型的输出(未经过Sigmoid函数)、真实标签和掩码作为输入,并返回一个张量,其中包含每个样本的损失值。
nn.functional.binary_cross_entropy_with_logits 是 PyTorch 中用于计算二分类问题的交叉熵损失函数。它可以在处理具有二元标签的分类任务时非常有用。该函数的输入是模型的输出 logits 和对应的目标标签,它会自动将 logits 通过 sigmoid 函数转换为概率,并计算预测概率与目标标签之间的交叉熵损失。
以下是 nn.functional.binary_cross_entropy_with_logits 函数的实现原理:
-
首先,输入的 logits 应该是一个具有任意形状的张量,通常来自于模型的输出层,没有经过 sigmoid 函数处理。
-
函数内部会将 logits 通过 sigmoid 函数转换为概率,即将 logits 的每个元素 x 转换为 p = 1 / (1 + exp(-x))。
-
然后,函数会将目标标签 target 转换为与 logits 相同的形状,以便进行逐元素的比较。
-
接下来,函数会计算每个预测概率 p 与对应的目标标签 t 之间的交叉熵损失,使用上述公式计算
-
最后,函数会返回所有样本的平均损失,即将每个样本的损失相加并除以样本总数(如果
reduction参数设置为'mean')。
pred = torch.tensor([[1.1, -2.2, 3.3, -4.4]] * 2)
label = torch.tensor([[1.0, 0.0, 0.0, 0.0], [0.0, 1.0, 0.0, 0.0]])
mask = torch.tensor([[1, 1, 1, 1], [1, 1, 0, 0]])
loss(pred, label, mask) * mask.shape[1] / mask.sum(axis=1)

计算过程:
def sigmd(x):
return -math.log(1 / (1 + math.exp(-x)))
print(f'{
(sigmd(1.1) + sigmd(2.2) + sigmd(-3.3) + sigmd(4.4)) / 4:.4f}')
print(f'{
(sigmd(-1.1) + sigmd(-2.2)) / 2:.4f}')

初始化模型参数
我们定义了两个嵌入层,将词表中的所有单词分别作为中心词和上下文词使用。字向量维度embed_size被设置为100。
embed_size = 100
net = nn.Sequential(nn.Embedding(num_embeddings=len(vocab),
embedding_dim=embed_size),
nn.Embedding(num_embeddings=len(vocab),
embedding_dim=embed_size))
定义训练阶段代码
训练阶段代码实现定义如下。由于填充的存在,损失函数的计算与以前的训练函数略有不同。
def train(net, data_iter, lr, num_epochs, device=d2l.try_gpu()):
def init_weights(m):
if type(m) == nn.Embedding:
nn.init.xavier_uniform_(m.weight)
net.apply(init_weights)
net = net.to(device)
optimizer = torch.optim.Adam(net.parameters(), lr=lr)
animator = d2l.Animator(xlabel='epoch', ylabel='loss',
xlim=[1, num_epochs])
# 规范化的损失之和,规范化的损失数
metric = d2l.Accumulator(2)
for epoch in range(num_epochs):
timer, num_batches = d2l.Timer(), len(data_iter)
for i, batch in enumerate(data_iter):
optimizer.zero_grad()
center, context_negative, mask, label = [
data.to(device) for data in batch]
pred = skip_gram(center, context_negative, net[0], net[1])
l = (loss(pred.reshape(label.shape).float(), label.float(), mask)
/ mask.sum(axis=1) * mask.shape[1])
l.sum().backward()
optimizer.step()
metric.add(l.sum(), l.numel())
if (i + 1) % (num_batches // 5) == 0 or i == num_batches - 1:
animator.add(epoch + (i + 1) / num_batches,
(metric[0] / metric[1],))
print(f'loss {
metric[0] / metric[1]:.3f}, '
f'{
metric[1] / timer.stop():.1f} tokens/sec on {
str(device)}')
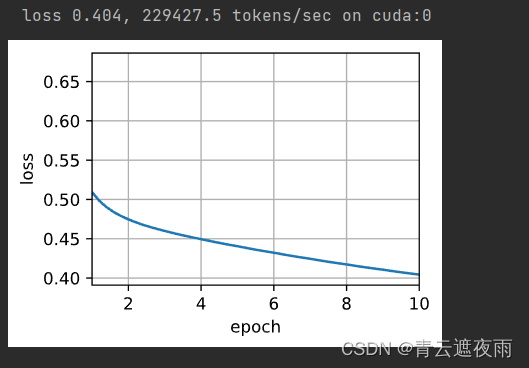
现在,我们可以使用负采样来训练跳元模型。
lr, num_epochs = 0.002, 5
train(net, data_iter, lr, num_epochs)
应用词嵌入
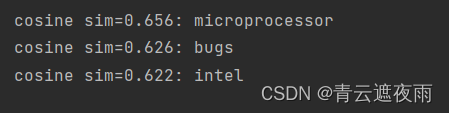
在训练word2vec模型之后,我们可以使用训练好模型中词向量的余弦相似度来从词表中找到与输入单词语义最相似的单词。
def get_similar_tokens(query_token, k, embed):
W = embed.weight.data
x = W[vocab[query_token]]
# 计算余弦相似性。增加1e-9以获得数值稳定性
cos = torch.mv(W, x) / torch.sqrt(torch.sum(W * W, dim=1) *
torch.sum(x * x) + 1e-9)
topk = torch.topk(cos, k=k+1)[1].cpu().numpy().astype('int32')
for i in topk[1:]: # 删除输入词
print(f'cosine sim={
float(cos[i]):.3f}: {
vocab.to_tokens(i)}')
get_similar_tokens('chip', 3, net[0])