初探CNN卷积神经网络
1、概述
- 典型的深度学习模型就是很深层的神经网络,包含多个
隐含层,多隐层的神经网络很难直接使用BP算法进行直接训练,因为反向传播误差时往往会发散,很难收敛 CNN节省训练开销的方式是权共享weight sharing,让一组神经元使用相同的权值- 主要用于图像识别领域
2、卷积(Convolution)特征提取
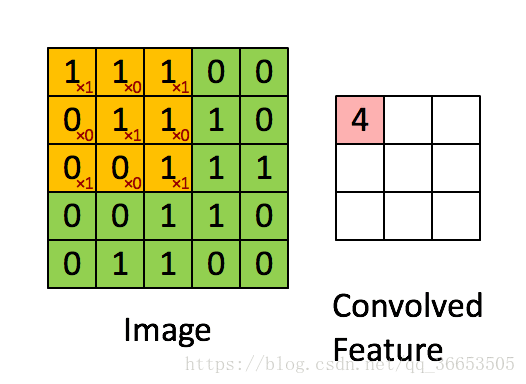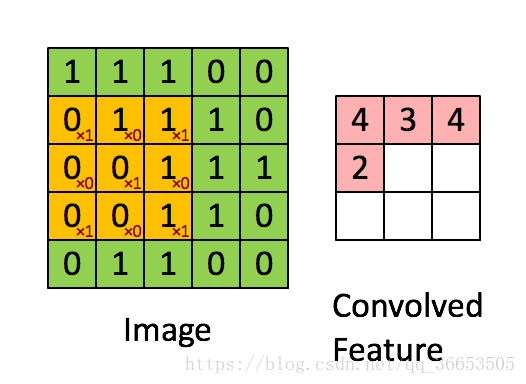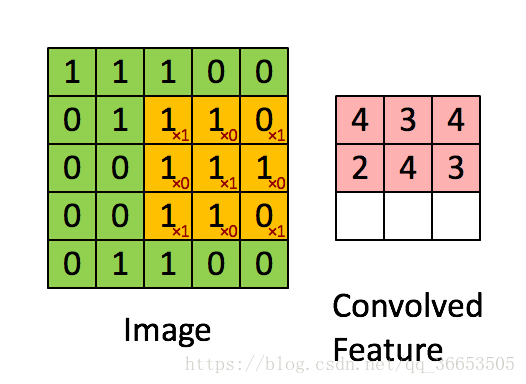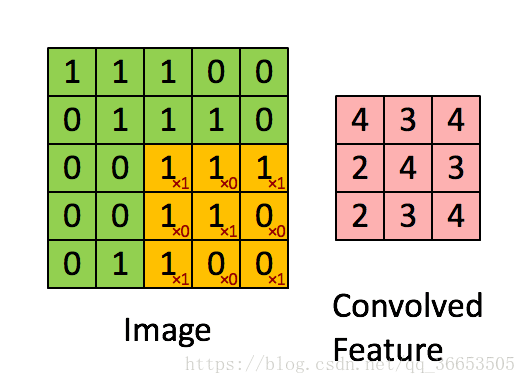
卷积核(Convolution Kernel),也叫过滤器filter,由对应的权值W和偏置b体现- 下图是
3x3的卷积核在5x5的图像上做卷积的过程,就是矩阵做点乘之后的和
第i个隐含单元的输入就是:,其中
就是与过滤器filter过滤到的图片
- 另外上图的步长
stride为1,就是每个filter每次移动的距离 卷积特征提取的原理
- 卷积特征提取利用了自然图像的统计平稳性,这一部分学习的特征也能用在另一部分上,所以对于这个图像上的所有位置,我们都能使用同样的学习特征。
- 当有多个
filter时,我们就可以学到多个特征,例如:轮廓、颜色等
多个过滤器
filter(卷积核)- 例子如下
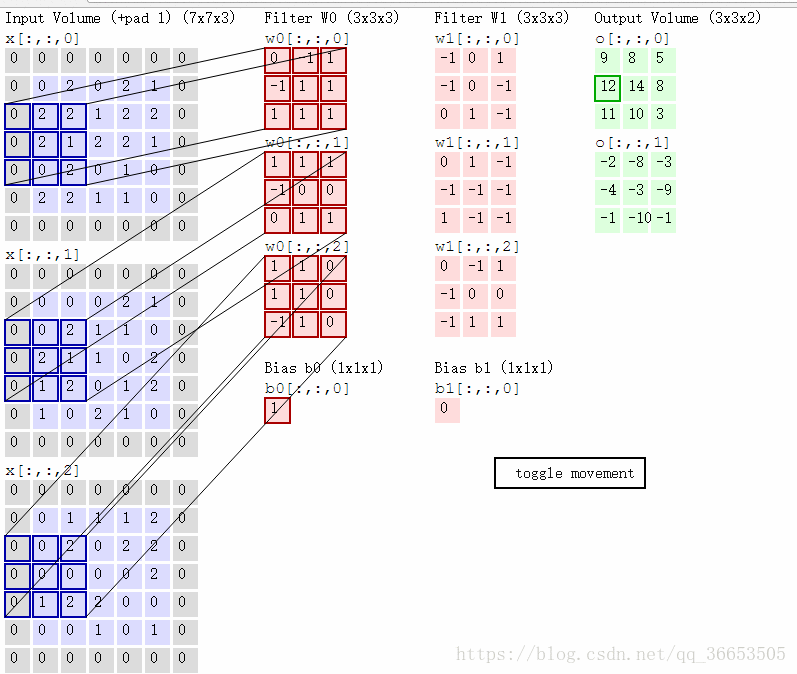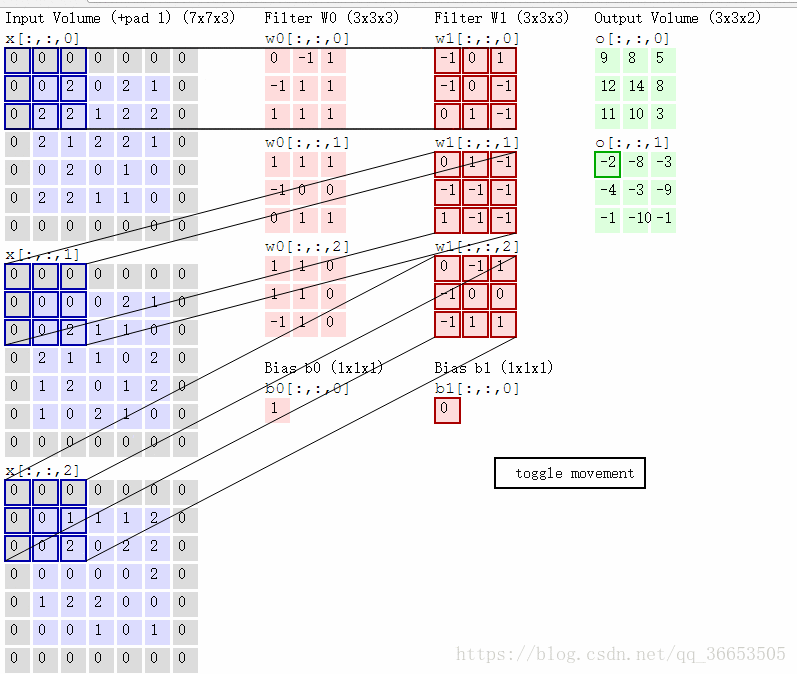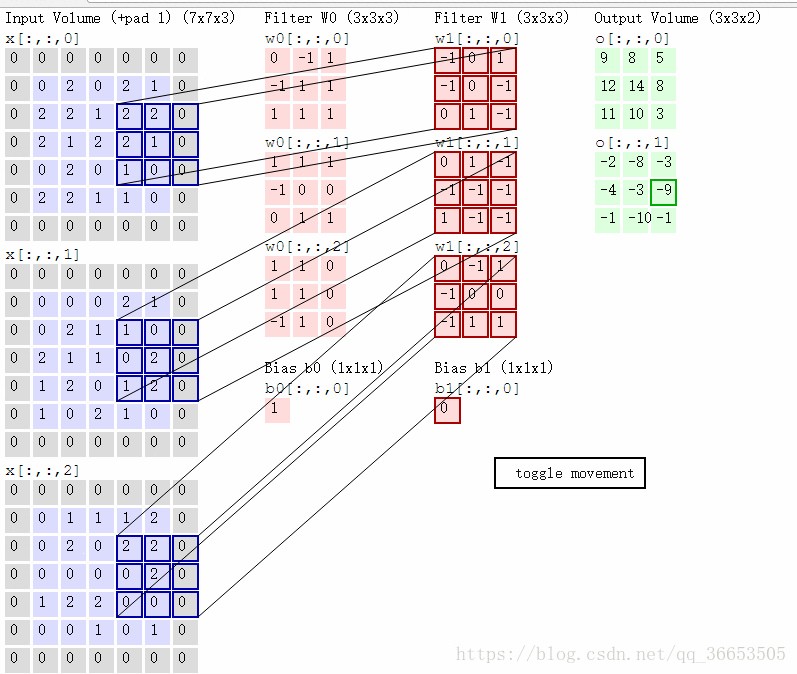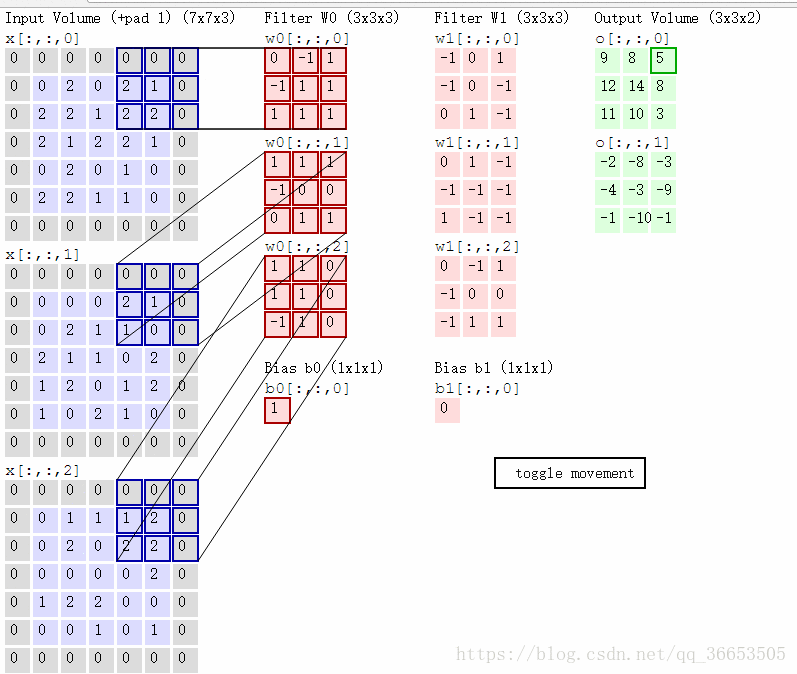
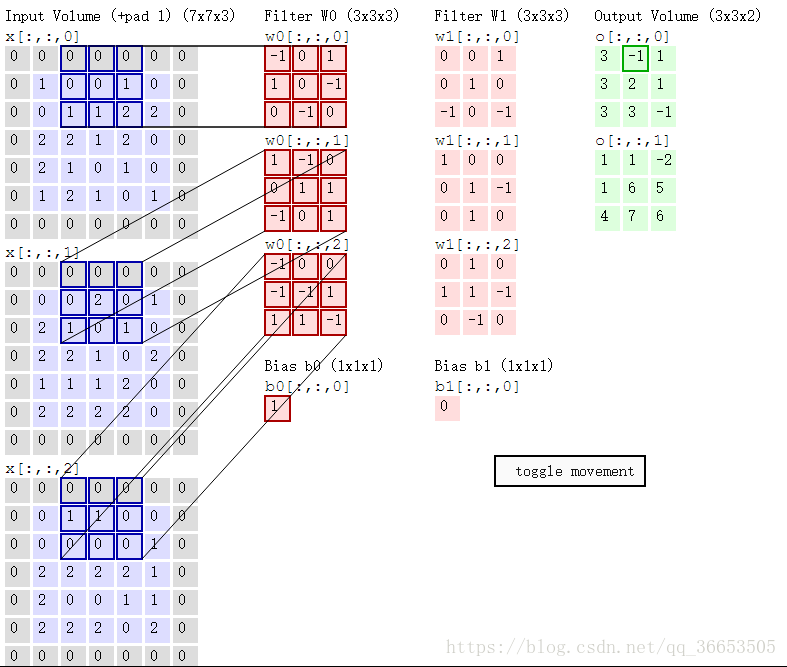
- 一张图片有RGB三个颜色通道,则对应的filter过滤器也是三维的,图像经过每个filter做卷积运算后都会得到对应提取特征的图像,途中两个filter:W0和W1,输出的就是两个图像
- 这里的步长stride为2(一般就取2,3)
- 在原图上添加zero-padding,它是超参数,主要用于控制输出的大小
- 同样也是做卷积操作,以下图的一步卷积操作为例:
与w0[:,:,0]卷积:0x(-1)+0x0+0x1+0x1+0x0+1x(-1)+1x0+1x(-1)+2x0=-2
与w0[:,:,1]卷积:2x1+1x(-1)+1x1=2
与w0[:,:,2]卷积:1x(-1)+1x(-1)=-2
最终结果:-2+2+(-2)+1=-1 (1为偏置)
3、池化(Pooling)
- 也叫做下采样
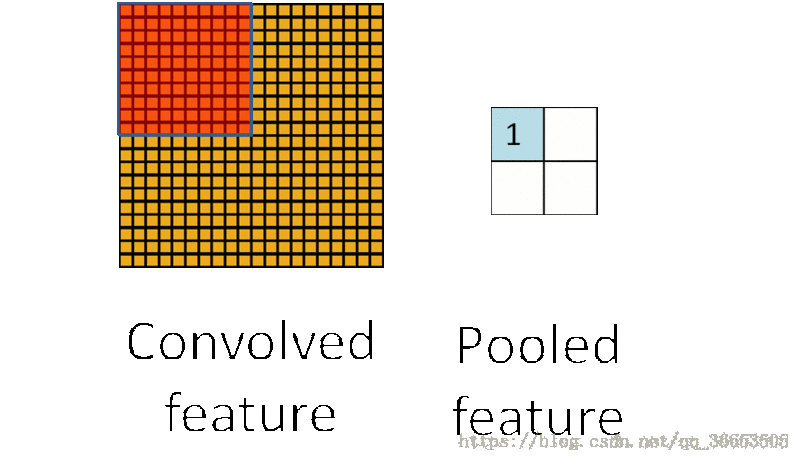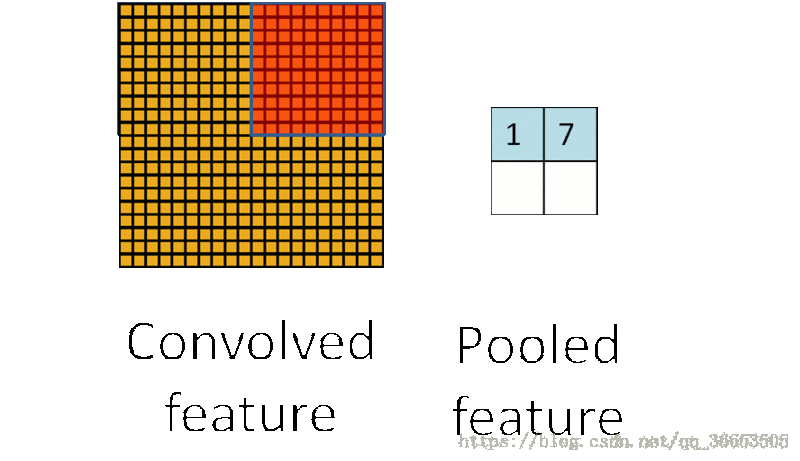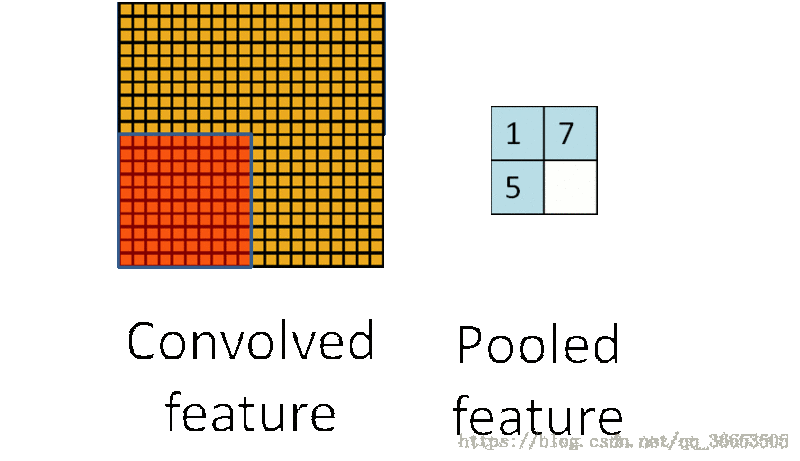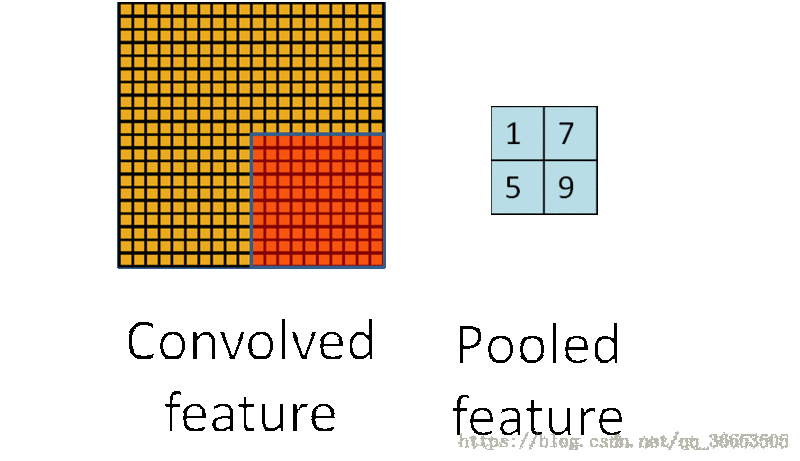
Pooling过程- 把提取之后的特征看做一个矩阵,并在这个矩阵上划分出几个不重合的区域,
- 然后在每个区域上计算该区域内特征的均值或最大值,然后用这些均值或最大值参与后续的训练
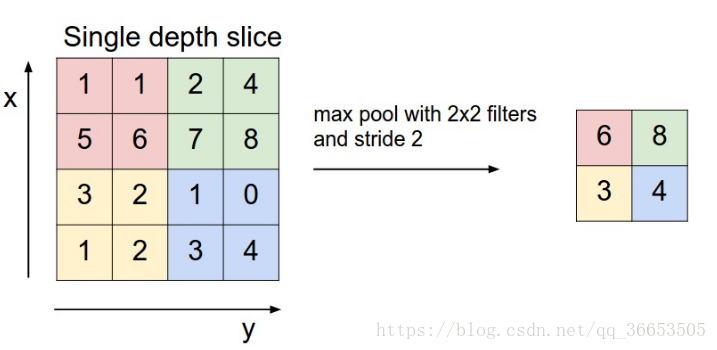
-下图是使用最大
Pooling的方法之后的结果
Pooling的好处
- 很明显就是减少参数
Pooling就有平移不变性((translation invariant)
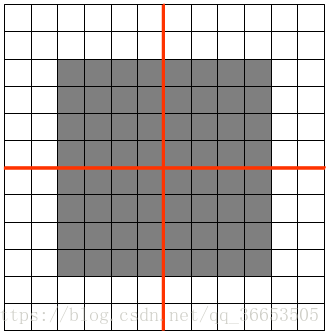
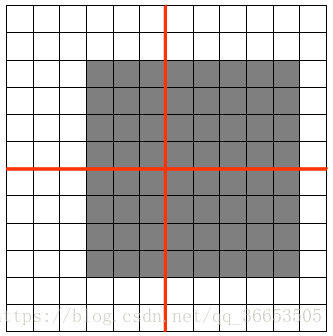
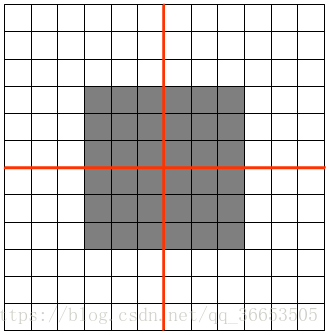
如图feature map是12x12大小的图片,Pooling区域为6x6,所以池化后得到的feature map为2x2,假设白色像素值为1,灰色像素值为0,若采用max pooling之后,左上角窗口值为**
将图像右移一个像素,左上角窗口值仍然为1
将图像缩放之后,左上角窗口值仍然为1
Pooling的方法中average方法对背景保留更好,max对纹理提取更好- 深度学习可以进行多次卷积、池化操作
4、激活层
- 在每次卷积操作之后一般都会经过一个非线性层,也是激活层
- 现在一般选择是
ReLu,层次越深,相对于其他的函数效果较好,还有Sigmod,tanh函数等
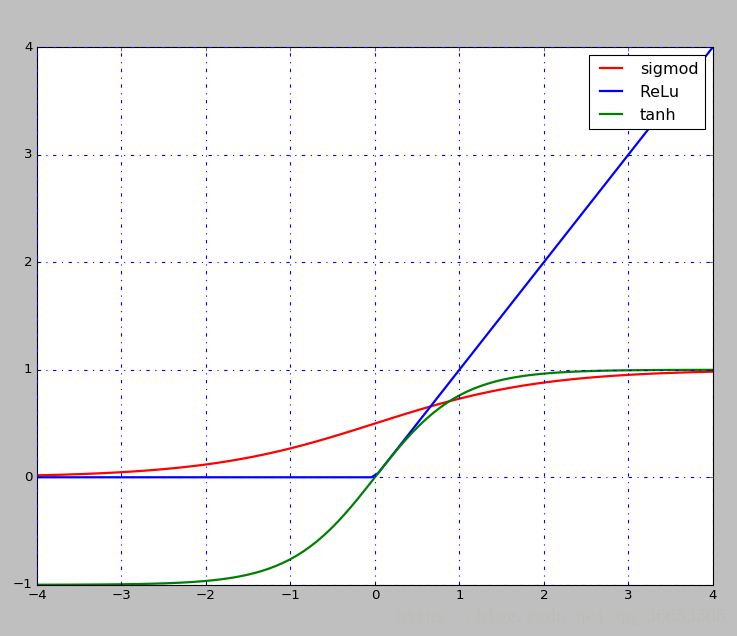
- sigmod和tanh都存在饱和的问题,如上图所示,当x轴上的值较大时,对应的梯度几乎为0,若是利用BP反向传播算法, 可能造成梯度消失的情况,也就学不到东西了
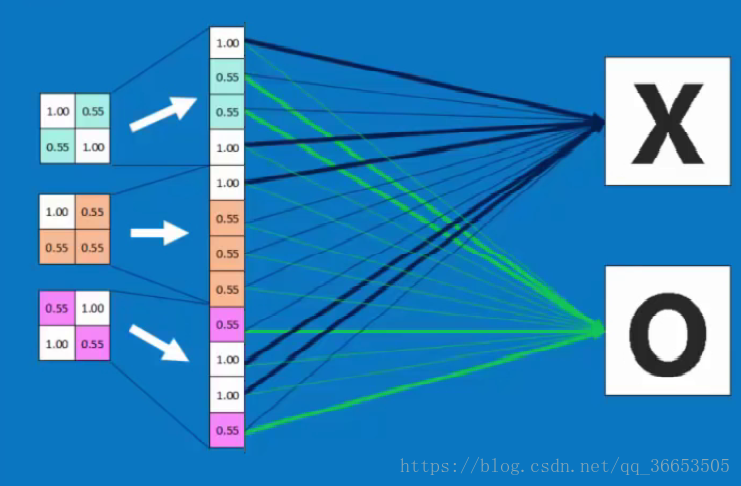
5、全连接层 Fully connected layer
- 将多次卷积和池化后的图像展开进行全连接,如下图所示。
- 接下来就可以通过BP反向传播进行训练了
- 所以总结起来,结构可以是这样的

6、CNN是如何工作的
- 看到知乎上的一个回答还不错:https://www.zhihu.com/question/52668301
- 每个过滤器可以被看成是特征标识符
( feature identifiers) - 如下图一个曲线检测器对应的值
- 我们有一张图片,当过滤器移动到左上角时,进行卷积运算
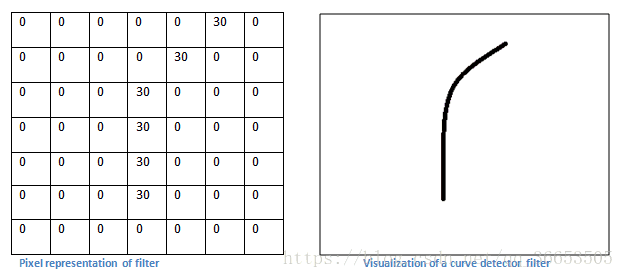
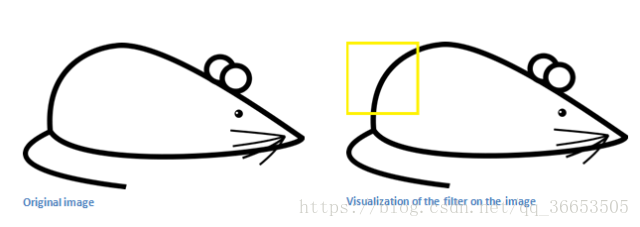
- 当与我们的过滤器的形状很相似时,得到的值会很大

- 若是滑动到其他的部分,可以看出很不一样,对应的值就会很小,然后进行激活层的映射。

- 过滤器filter的值怎么求到,就是我们通过BP训练得到的。
CNN的Tensorflow实现
import tensorflow as tf
import numpy as np
from tensorflow.examples.tutorials.mnist import input_data # 导入mnist数据集
'''计算准确度函数'''
def compute_accuracy(xs,ys,X,y,keep_prob,sess,prediction):
y_pre = sess.run(prediction,feed_dict={xs:X,keep_prob:1.0}) # 预测,这里的keep_prob是dropout时用的,防止过拟合
correct_prediction = tf.equal(tf.argmax(y_pre,1),tf.argmax(y,1)) #tf.argmax 给出某个tensor对象在某一维上的其数据最大值所在的索引值,即为对应的数字,tf.equal 来检测我们的预测是否真实标签匹配
accuracy = tf.reduce_mean(tf.cast(correct_prediction,tf.float32)) # 平均值即为准确度
result = sess.run(accuracy,feed_dict={xs:X,ys:y,keep_prob:1.0})
return result
'''权重初始化函数'''
def weight_variable(shape):
inital = tf.truncated_normal(shape, stddev=0.1) # 使用truncated_normal进行初始化
return tf.Variable(inital)
'''偏置初始化函数'''
def bias_variable(shape):
inital = tf.constant(0.1,shape=shape) # 偏置定义为常量
return tf.Variable(inital)
'''卷积函数'''
def conv2d(x,W):#x是图片的所有参数,W是此卷积层的权重
return tf.nn.conv2d(x,W,strides=[1,1,1,1],padding='SAME')#strides[0]和strides[3]的两个1是默认值,中间两个1代表padding时在x方向运动1步,y方向运动1步
'''池化函数'''
def max_pool_2x2(x):
return tf.nn.max_pool(x,ksize=[1,2,2,1],
strides=[1,2,2,1],
padding='SAME')#池化的核函数大小为2x2,因此ksize=[1,2,2,1],步长为2,因此strides=[1,2,2,1]
'''运行主函数'''
def cnn():
mnist = input_data.read_data_sets('MNIST_data', one_hot=True) # 下载数据
xs = tf.placeholder(tf.float32,[None,784]) # 输入图片的大小,28x28=784
ys = tf.placeholder(tf.float32,[None,10]) # 输出0-9共10个数字
keep_prob = tf.placeholder(tf.float32) # 用于接收dropout操作的值,dropout为了防止过拟合
x_image = tf.reshape(xs,[-1,28,28,1]) #-1代表先不考虑输入的图片例子多少这个维度,后面的1是channel的数量,因为我们输入的图片是黑白的,因此channel是1,例如如果是RGB图像,那么channel就是3
'''第一层卷积,池化'''
W_conv1 = weight_variable([5,5,1,32]) # 卷积核定义为5x5,1是输入的通道数目,32是输出的通道数目
b_conv1 = bias_variable([32]) # 每个输出通道对应一个偏置
h_conv1 = tf.nn.relu(conv2d(x_image,W_conv1)+b_conv1) # 卷积运算,并使用ReLu激活函数激活
h_pool1 = max_pool_2x2(h_conv1) # pooling操作
'''第二层卷积,池化'''
W_conv2 = weight_variable([5,5,32,64]) # 卷积核还是5x5,32个输入通道,64个输出通道
b_conv2 = bias_variable([64]) # 与输出通道一致
h_conv2 = tf.nn.relu(conv2d(h_pool1, W_conv2)+b_conv2)
h_pool2 = max_pool_2x2(h_conv2)
'''全连接层'''
h_pool2_flat = tf.reshape(h_pool2, [-1,7*7*64]) # 将最后操作的数据展开
W_fc1 = weight_variable([7*7*64,1024]) # 下面就是定义一般神经网络的操作了,继续扩大为1024
b_fc1 = bias_variable([1024]) # 对应的偏置
h_fc1 = tf.nn.relu(tf.matmul(h_pool2_flat,W_fc1)+b_fc1) # 运算、激活(这里不是卷积运算了,就是对应相乘)
'''dropout'''
h_fc1_drop = tf.nn.dropout(h_fc1,keep_prob) # dropout操作
'''最后一层全连接'''
W_fc2 = weight_variable([1024,10]) # 最后一层权重初始化
b_fc2 = bias_variable([10]) # 对应偏置
prediction = tf.nn.softmax(tf.matmul(h_fc1_drop,W_fc2)+b_fc2) # 使用softmax分类器
cross_entropy = tf.reduce_mean(-tf.reduce_sum(ys*tf.log(prediction),reduction_indices=[1])) # 交叉熵损失函数来定义cost function
train_step = tf.train.AdamOptimizer(1e-3).minimize(cross_entropy) # 调用梯度下降
'''下面就是tf的一般操作,定义Session,初始化所有变量,placeholder传入值训练'''
sess = tf.Session()
sess.run(tf.initialize_all_variables())
for i in range(1000):
batch_xs, batch_ys = mnist.train.next_batch(100) # 使用SGD,每次选取100个数据训练
sess.run(train_step, feed_dict={xs: batch_xs, ys: batch_ys, keep_prob: 0.5}) # dropout值定义为0.5
if i % 50 == 0:
print(compute_accuracy(xs,ys,mnist.test.images, mnist.test.labels,keep_prob,sess,prediction)) # 每50次输出一下准确度
if __name__ == '__main__':
cnn()